Computer Organization And Design The Hardware Software Interface 4th Revised Edition David A. Patterson, John L. Hennessy - Solutions
Unlock the full potential of your studies with the comprehensive solutions and answers key for "Computer Organization and Design: The Hardware/Software Interface, 4th Revised Edition" by David A. Patterson and John L. Hennessy. Whether you're looking for a solution manual or step-by-step answers, our online resources have you covered. Access solved problems and chapter solutions to enhance your understanding. Our test bank and instructor manual offer valuable insights into the textbook. Plus, enjoy the convenience of a free download of solutions in PDF format. Elevate your learning experience with our expertly crafted questions and answers.







![PC 4 Instruction [25-0] Add Read address Instruction [31-0] Instruction memory 26 Shift left 2, Instruction](https://dsd5zvtm8ll6.cloudfront.net/images/question_images/1698/2/2/0/7976538cafd628951698220795953.jpg)
![a. b. Instruction SEQ Rd, Rs. Rt LWI Rt, Rd (Rs) Reg[Rd] Reg[Rt] = Interpretation Boolean value (0 or 1) of](https://dsd5zvtm8ll6.cloudfront.net/images/question_images/1698/2/1/6/7006538bafd00a0f1698216699865.jpg)







![PC Instruction [25-0] Add Read address Instruction [31-0] Instruction memory 26 Shift left 2/ Instruction](https://dsd5zvtm8ll6.cloudfront.net/images/question_images/1698/2/2/3/2746538d4aab98951698223272879.jpg)






![a. b. ADDM Rd, Rt+Offs (Rs) BEQM Rd, Rt, Offs (Rs) Rd=Rt+Mem[Offs+Rs] if Rt=Mem[Offs+Rs] then PC = Rd](https://dsd5zvtm8ll6.cloudfront.net/images/question_images/1698/2/3/0/1826538efa6aa82d1698230175553.jpg)

![a. b. Instruction AND Rd, Rs, Rt SW Rt, Offs (Rs) Interpretation Reg[Rd]=Reg[Rs] AND Reg[Rt]](https://dsd5zvtm8ll6.cloudfront.net/images/question_images/1698/2/1/5/9996538b83feea8f1698215981279.jpg)

![a. Instruction SWINC Rt, Offset (Rs) b. SWI Rt, Rd (Rs) Interpretation Mem[Reg[Rs]+Offset]=Reg [Rt] Reg[Rs ]](https://dsd5zvtm8ll6.cloudfront.net/images/question_images/1698/3/0/9/990653a2766637201698309988336.jpg)


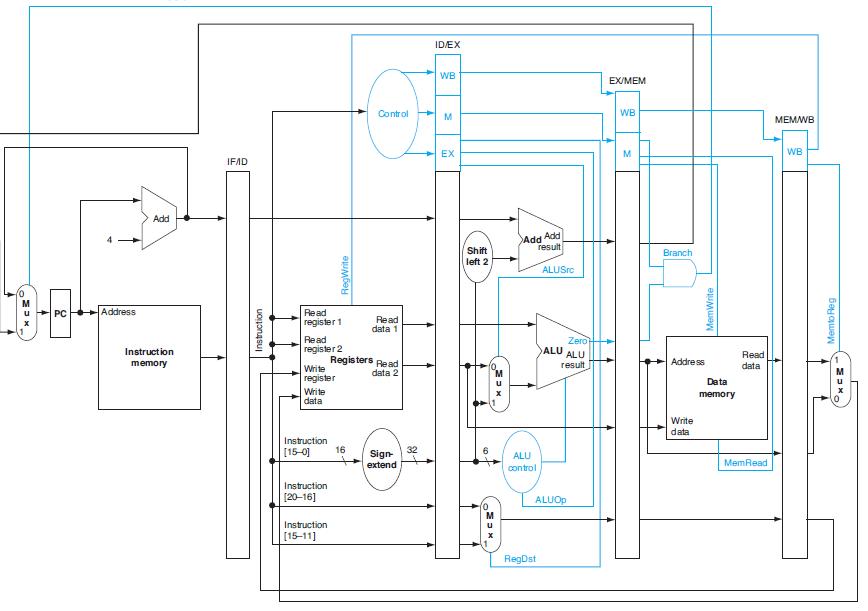

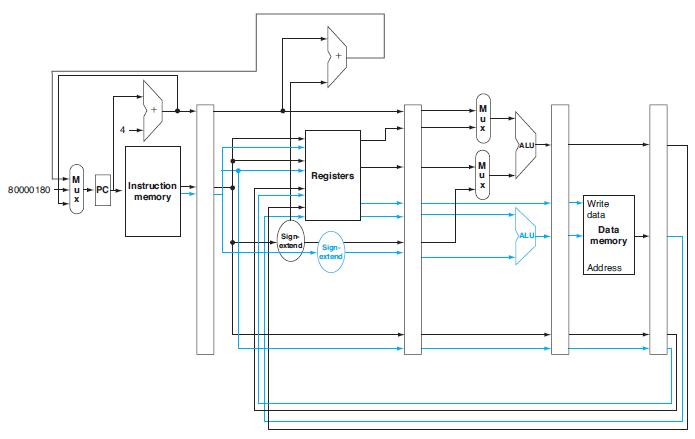
![a. for(i=0;i!-j;i+=2) a[i+1]=a[i]; b. for(i=0; i-j;i+=2) b[i]-a[i]-a[i+1]; C Code](https://dsd5zvtm8ll6.cloudfront.net/images/question_images/1698/3/0/6/885653a1b454551c1698306883241.jpg)





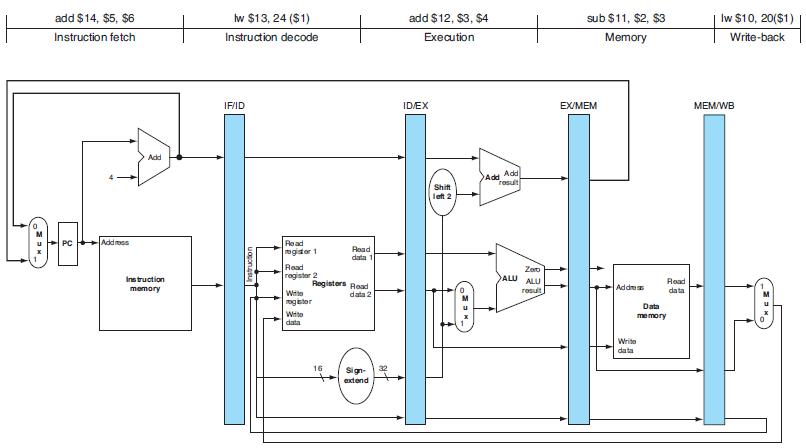



![PC Instruction [25-0] Add Read address Instruction [31-0] Instruction memory 26 Shift left 2/ Instruction](https://dsd5zvtm8ll6.cloudfront.net/images/question_images/1698/2/2/3/2886538d4b8756d71698223287104.jpg)




![a. b. Instruction AND Rd, Rs, Rt SW Rt, Offs (Rs) Interpretation Reg[Rd]=Reg[Rs] AND Reg[Rt]](https://dsd5zvtm8ll6.cloudfront.net/images/question_images/1698/3/0/9/169653a24315b4331698309167288.jpg)


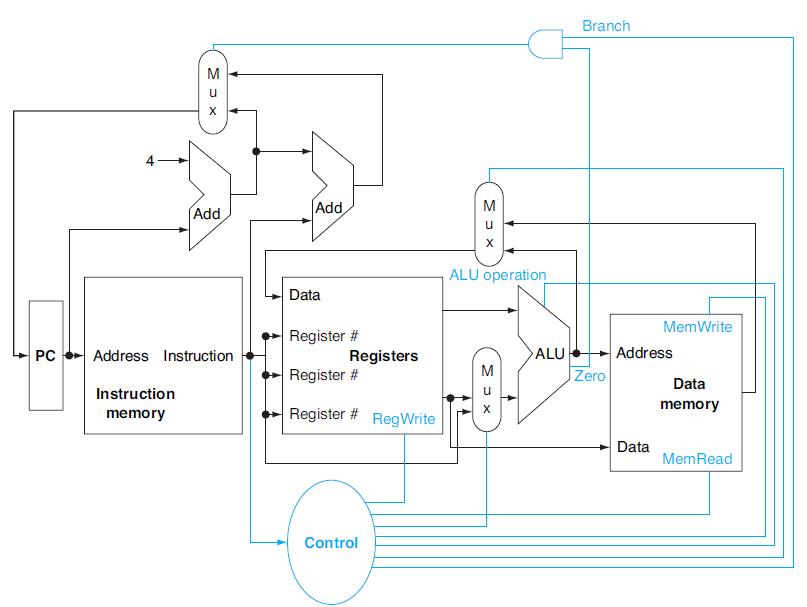













![PC 4 Instruction [25-0] Add Read address Instruction [31-0] Instruction memory 26 Shift left 2 Instruction](https://dsd5zvtm8ll6.cloudfront.net/images/question_images/1698/2/2/1/8226538cefe791201698221821237.jpg)