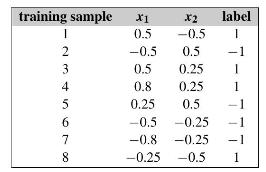
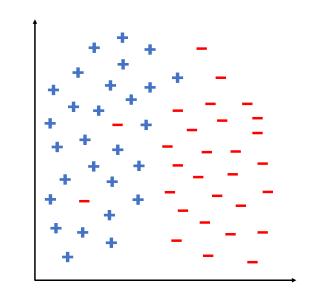
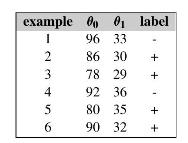
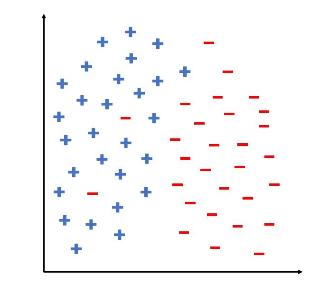
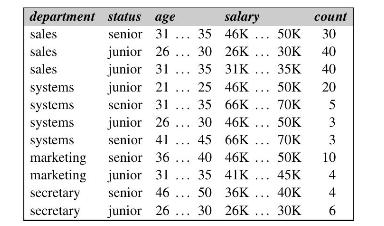
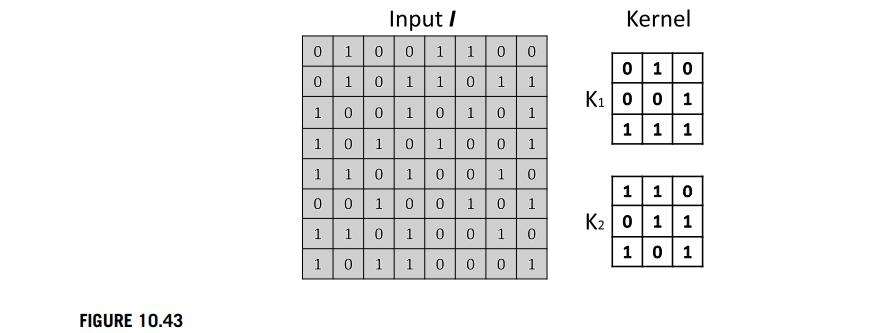
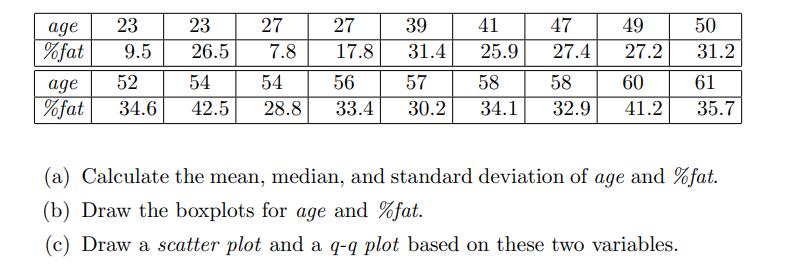
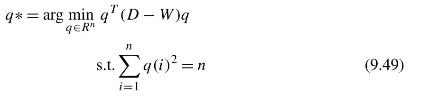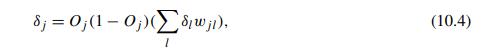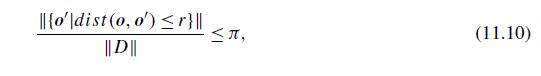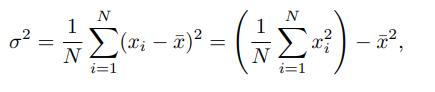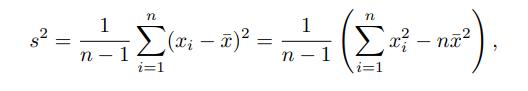Data Mining Concepts And Techniques 4th Edition Jiawei Han, Jian Pei, Hanghang Tong - Solutions
Unlock the comprehensive learning experience with the "Data Mining Concepts and Techniques 4th Edition" solutions. Explore a wide range of online answers key and solutions pdf to enhance your understanding. Our expertly crafted solution manual offers solved problems, providing step-by-step answers to challenging questions. Access the complete test bank and chapter solutions to excel in your studies. The instructor manual is designed to guide educators and students alike, ensuring a thorough grasp of the textbook material. Enjoy the convenience of a free download, making these invaluable resources readily available for all learners.