New Semester
Started
Get
50% OFF
Study Help!
--h --m --s
Claim Now
Question Answers
Textbooks
Find textbooks, questions and answers
Oops, something went wrong!
Change your search query and then try again
S
Books
FREE
Study Help
Expert Questions
Accounting
General Management
Mathematics
Finance
Organizational Behaviour
Law
Physics
Operating System
Management Leadership
Sociology
Programming
Marketing
Database
Computer Network
Economics
Textbooks Solutions
Accounting
Managerial Accounting
Management Leadership
Cost Accounting
Statistics
Business Law
Corporate Finance
Finance
Economics
Auditing
Tutors
Online Tutors
Find a Tutor
Hire a Tutor
Become a Tutor
AI Tutor
AI Study Planner
NEW
Sell Books
Search
Search
Sign In
Register
study help
computer science
data mining concepts and techniques
Data Mining Concepts And Techniques 4th Edition Jiawei Han, Jian Pei, Hanghang Tong - Solutions
A data warehouse can be modeled by either a star schema or a snowflake schema. Briefly describe the similarities and the differences of the two models, and then analyze their advantages and disadvantages with regard to one another. Give your opinion of which might be more empirically useful and
Design a data warehouse for a regional weather bureau. The weather bureau has about 1000 probes, which are scattered throughout various land and ocean locations in the region to collect basic weather data, including air pressure, temperature, and precipitation at each hour. All data are sent to the
A popular data warehouse implementation is to construct a multidimensional database, known as a data cube. Unfortunately, this may often generate a huge, yet very sparse, multidimensional matrix.a. Present an example illustrating such a huge and sparse data cube.b. Design an implementation method
Regarding the computation of measures in a data cube:a. Enumerate three categories of measures, based on the kind of aggregate functions used in computing a data cube.b. For a data cube with the three dimensions time, location, and item, which category does the function variance belong to? Describe
Suppose a company wants to design a data warehouse to facilitate the analysis of moving vehicles in an online analytical processing manner. The company registers huge amounts of automovement data in the format of (Auto_ID, location, speed, time). Each Auto_ID represents a vehicle associated with
Radio-frequency identification is commonly used to trace object movement and perform inventory control. An RFID reader can successfully read an RFID tag from a limited distance at any scheduled time. Suppose a company wants to design a data warehouse to facilitate the analysis of objects with RFID
In many applications, new data sets are incrementally added to the existing large data sets. Thus, an important consideration is whether a measure can be computed efficiently in an incremental manner. Use count, standard deviation, and median as examples to show that a distributive or algebraic
Suppose that we need to record three measures in a data cube: min (), a verage(), and median( ). Design an efficient computation and storage method for each measure given that the cube allows data to be deleted incrementally (i.e., in small portions at a time) from the cube.
In data warehouse technology, a multiple dimensional view can be implemented by a relational database technique (ROLAP), by a multidimensional database technique (MOLAP), or by a hybrid database technique (HOLAP).a. Briefly describe each implementation technique.b. For each technique, explain how
Suppose that a data warehouse contains 20 dimensions, each with about five levels of granularity.a. Users are mainly interested in four particular dimensions, each having three frequently accessed levels for rolling up and drilling down. How would you design a data cube structure to support this
A data cube, \(C\), has \(n\) dimensions, and each dimension has exactly \(p\) distinct values in the base cuboid. Assume that there are no concept hierarchies associated with the dimensions.a. What is the maximum number of cells possible in the base cuboid?b. What is the minimum number of cells
Assume that a 10-D base cuboid contains only three base cells: (1) \(\left(a_{1}, d_{2}, d_{3}, d_{4}, \ldots, d_{9}, d_{10}ight)\), (2) \(\left(d_{1}, b_{2}, d_{3}, d_{4}, \ldots, d_{9}, d_{10}ight)\), and (3) \(\left(d_{1}, d_{2}, c_{3}, d_{4}, \ldots, d_{9}, d_{10}ight)\), where \(a_{1} eq
There are several typical cube computation methods, such as MultiWay [ZDN97], BUC [BR99], and Star-Cubing [XHLW03]. Briefly describe these three methods (i.e., use one or two lines to outline the key points) and compare their feasibility and performance under the following conditions:a. Computing a
Suppose a data cube, \(C\), has \(D\) dimensions, and the base cuboid contains \(k\) distinct tuples.a. Present a formula to calculate the minimum number of cells that the cube, \(C\), may contain.b. Present a formula to calculate the maximum number of cells that \(C\) may contain.c. Answer parts
Suppose that a base cuboid has three dimensions, \(A, B, C\), with the following number of cells: \(|A|=1,000,000,|B|=100\), and \(|C|=1000\). Suppose that each dimension is evenly partitioned into 10 portions for chunking.a. Assuming each dimension has only one level, draw the complete lattice of
When computing a cube of high dimensionality, we encounter the inherent curse of dimensionality problem: There exists a huge number of subsets of combinations of dimensions.a. Suppose that there are only two base cells, \(\left\{\left(a_{1}, a_{2}, a_{3}, \ldots, a_{100}ight)ight.\) and
Propose an algorithm that computes closed iceberg cubes efficiently.
Suppose that we want to compute an iceberg cube for the dimensions, \(A, B, C, D\), where we wish to materialize all cells that satisfy a minimum support count of at least \(v\), and where car\(\operatorname{dinality}(A)
Discuss how you might extend the Star-Cubing algorithm to compute iceberg cubes where the iceberg condition tests for an avg that is no bigger than some value, \(v\).
A flight data warehouse for a travel agent consists of six dimensions: traveler, departure (city), departure_time, arrival, arrival_time, and fight; and two measures: count ( ) and avg_fare( ), where avg_fare ( ) stores the concrete fare at the lowest level but the average fare at other levels.a.
(Implementation project) There are four typical data cube computation methods: MultiWay [ZDN97], BUC [BR99], H-Cubing [HPDW01], and Star-Cubing [XHLW03].a. Implement any one of these cube computation algorithms and describe your implementation, experimentation, and performance. Find another student
The sampling cube was proposed for multidimensional analysis of sampling data (e.g., survey data). In many real applications, sampling data can be of high dimensionality (e.g., it is not unusual to have more than 50 dimensions in a survey data set).a. How can we construct an efficient and scalable
The ranking cube was designed to support top- \(k\) (ranking) queries in relational database systems. However, ranking queries are also posed to data warehouses, where ranking is on multidimensional aggregates instead of on measures of base facts. For example, consider a product managerwho is
Recently, researchers have proposed another kind of query, called a skyline query. A skyline query returns all the objects \(p_{i}\) such that \(p_{i}\) is not dominated by any other object \(p_{j}\), where dominance is defined as follows. Let the value of \(p_{i}\) on dimension \(d\) be
The prediction cube is a good example of multidimensional data mining in cube space.a. Propose an efficient algorithm that computes prediction cubes in a given multidimensional database.b. For what kind of classification models can your algorithm be applied? Explain.
Multifeature cubes allow us to construct interesting data cubes based on rather sophisticated query conditions. Can you construct the following multifeature cube by translating the following user requests into queries using the form introduced in this textbook?a. Construct a smart shopper cube
Discovery-driven cube exploration is a desirable way to mark interesting points among a large number of cells in a data cube. Individual users may have different views on whether a point should be considered interesting enough to be marked. Suppose one would like to mark those objects of which the
Suppose you have the set \(\mathcal{C}\) of all frequent closed itemsets on a data set \(D\), as well as the support count for each frequent closed itemset. Describe an algorithm to determine whether a given itemset \(X\) is frequent or not, and the support of \(X\) if it is frequent.
An itemset \(X\) is called a generator on a data set \(D\) if there does not exist a proper subitemset \(Y \subset\) \(X\) such that \(\operatorname{support}(X)=\operatorname{support}(Y)\). A generator \(X\) is a frequent generator if \(\operatorname{support}(X)\) passes the minimum support
The Apriori algorithm makes use of prior knowledge of subset support properties.a. Prove that all nonempty subsets of a frequent itemset must also be frequent.b. Prove that the support of any nonempty subset \(s^{\prime}\) of itemset \(s\) must be at least as great as the support of \(s\).c. Given
Let cc be a candidate itemset in CkCk generated by the Apriori algorithm. How many length- (k−1)(k−1) subsets do we need to check in the prune step? Per your previous answer, can you give an improved version of procedure has_infrequent_subset in Fig. 4.4?Fig. 4.4 Algorithm: Apriori. Find
Section 4.2.2 describes a method for generating association rules from frequent itemsets. Propose a more efficient method. Explain why it is more efficient than the one proposed there. (consider incorporating the properties of Exercises 4.3(b), (c) into your design.)Section 4.2.2Exercises 4.3b.
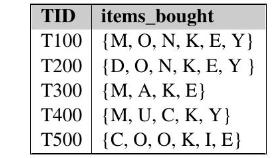
A database has five transactions. Let \(\min _{-} \sup =60 \%\) and \(\min _{-}\)conf \(=80 \%\).a. Find all frequent itemsets using Apriori and FP-growth, respectively. Compare the efficiency of the two mining processes.b. List all the strong association rules (with support \(s\) and confidence
(Implementation project) Using a programming language that you are familiar with, such as \(\mathrm{C}++\) or Java, implement three frequent itemset mining algorithms introduced in this chapter: (1) Apriori [AS94b], (2) FP-growth [HPY00], and (3) Eclat [Zak00] (mining using the vertical data
A database has four transactions. Let min_sup \(^{\text {4 }}=60 \%\) and min_conf \(^{\text {s }}=80 \%\).a. At the granularity of item_category (e.g., item \({ }_{i}\) could be "Milk"), for the rule template,\[\forall X \in \text { transaction, buys }\left(X, \text { item }_{1}ight) \wedge
Suppose that a large store has a transactional database that is distributed among four locations. Transactions in each component database have the same format, namely \(T_{j}:\left\{i_{1}, \ldots, i_{m}ight\}\), where \(T_{j}\) is a transaction identifier, and \(i_{k}(1 \leq k \leq m)\) is the
Suppose that frequent itemsets are saved for a large transactional database, \(D B\). Discuss how to efficiently mine the (global) association rules under the same minimum support threshold, if a set of new transactions, denoted as \(\triangle D B\), is (incrementally) added in?
Most frequent pattern mining algorithms consider only distinct items in a transaction. However, multiple occurrences of an item in the same shopping basket, such as four cakes and three jugs of milk, can be important in transactional data analysis. How can one mine frequent itemsets efficiently
(Implementation project) Many techniques have been proposed to further improve the performance of frequent itemset mining algorithms. Taking FP-tree-based frequent pattern growth algorithms (e.g., FP-growth) as an example, implement one of the following optimization techniques. Compare the
Give a short example to show that items in a strong association rule actually may be negatively correlated.
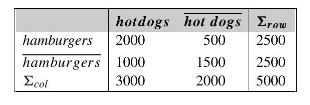
The following contingency table summarizes supermarket transaction data, where hot dogs refers to the transactions containing hot dogs, \(\overline{\text { hot dogs }}\) refers to the transactions that do not contain hot dogs, hamburgers refers to the transactions containing hamburgers, and
(Implementation project) The DBLP data set (https://dblp.uni-trier.de/xml/) consists of over three million entries of research papers published in computer science conferences and journals. Among these entries, there are a good number of authors that have coauthor relationships.a. Propose a method
Propose and outline a level-shared mining approach to mining multilevel association rules in which each item is encoded by its level position. Design it so that an initial scan of the database collects the count for each item at each concept level, identifying frequent and subfrequent items.
Suppose, as manager of a chain of stores, you would like to use sales transactional data to analyze the effectiveness of your store's advertisements. In particular, you would like to study how specific factors influence the effectiveness of advertisements that announce a particular category of
Quantitative association rules may disclose exceptional behaviors within a data set, where "exceptional" can be defined based on statistical theory. For example, Section 5.1.3 shows the association rule\[\text { gender }=\text { female } \Rightarrow \text { mean_wage }=\$ 7.90 / \text { hr }(\text
In multidimensional data analysis, it is interesting to extract pairs of similar cell characteristics associated with substantial changes in measure in a data cube, where cells are considered similar if they are related by roll-up (i.e., ancestors), drill-down (i.e., descendants), or 1-D mutation
Section 5.1.5 presented various ways of defining negatively correlated patterns. Consider Definition 5.3: "Suppose that itemsets \(X\) and \(Y\) are both frequent, that is, \(\sup (X) \geq\) min_sup and \(\sup (Y) \geq\) min_sup, where min_sup is the minimum support threshold. If \((P(X \mid Y)+\)
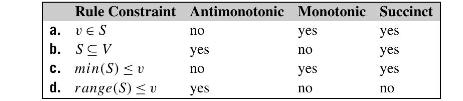
Prove that each entry in the following table correctly characterizes its corresponding rule constraint for frequent itemset mining. Rule Constraint a. ve S b. SCV c. min(S) O d. range(S) U Antimonotonic Monotonic Succinct yes yes yes no yes no yes yes no yes no
The price of each item in a store is nonnegative. The store manager is only interested in mining the rules, following the constraints given below. For each of the following cases, identify the kinds of constraints they represent and briefly discuss how to mine such association rules using
Section 5.1.4 introduced a core Pattern-Fusion method for mining high-dimensional data. Explain why a long pattern, if existing in the data set, is likely to be discovered by this method.Section 5.1.4Our discussions of mining multidimensional patterns in the above two subsections are confined to
Section 5.2.1 defined a pattern distance measure between closed patterns \(P_{1}\) and \(P_{2}\) as\[\text { Pat_Dist }\left(P_{1}, P_{2}ight)=1-\frac{\left|T\left(P_{1}ight) \cap T\left(P_{2}ight)ight|}{\left|T\left(P_{1}ight) \cup T\left(P_{2}ight)ight|}\]where \(T\left(P_{1}ight)\) and
Association rule mining often generates a large number of rules, many of which may be similar, thus not containing much novel information. Design an efficient algorithm that compresses a large set of patterns into a small compact set. Discuss whether your mining method is robust under different
Frequent pattern mining may generate many superfluous patterns. Therefore, it is important to develop methods that mine compressed patterns. Suppose a user would like to obtain only \(k\) patterns (where \(k\) is a small integer). Outline an efficient method that generates the \(\boldsymbol{k}\)
Sequential pattern mining is to mine sequential patterns for a set of items occurring in sequence order. In practice, people may like to find sequential patterns for types of items instead of for concrete items, such as sequence patterns formed by high-level concepts. For example, instead of
At studying customer shopping sequences, one may find if a customer buys a sequence of products from one company, the chance for him/her to buy the products of the similar kind from another company will be much reduced. Can you outline an efficient algorithm that will be able to capture such
Our study of subgraph pattern mining has been on how to mine frequent substructures from a collection of graph data sets. The current Web page structures (e.g., Wikipedia) or social networks may form one or a small number of gigantic network structures. One may need to find frequent common
In this chapter, we introduce an effective method for mining copy-and-paste bugs in software programs. Typically, a software program may take different inputs which may lead to different program execution sequences. For some inputs, the program execution finishes successfully but for some other
Briefly outline the major steps of decision tree classification.
Why is tree pruning useful in decision tree induction? What is a drawback of using a separate set of tuples to evaluate pruning?
Given a decision tree, you have the option of (a) converting the decision tree to rules and then pruning the resulting rules, or (b) pruning the decision tree and then converting the pruned tree to rules. What advantage does (a) have over (b)?
It is important to calculate the worst-case computational complexity of the decision tree algorithm. Given data set, DD, the number of attributes, nn, and the number of training tuples, |D||D|, analyze the computational complexity in terms of nn and |D||D|.
Given a 5-GB data set with 50 attributes (each containing 100 distinct values) and 512MB512MB of main memory in your laptop, outline an efficient method that constructs decision trees in such large data sets. Justify your answer by a rough calculation of your main memory usage.
Why is naïve Bayesian classification called "naïve"? Briefly outline the major ideas of naïve Bayesian classification.
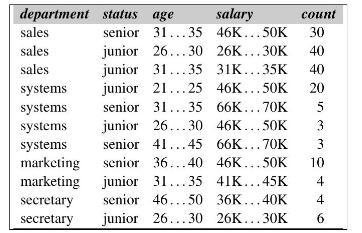
The following table consists of training data from an employee database. The data have been generalized. For example, " 31 ... 35" for age represents the age range of 31 to 35 . For a given row entry, count represents the number of data tuples having the values for department, status, age, and
Compare the advantages and disadvantages of eager classification (e.g., decision tree, Bayesian, neural network) vs. lazy classification (e.g., kk-nearest neighbor, case-based reasoning).
Write an algorithm for kk-nearest-neighbor classification given kk, the nearest number of neighbors, and nn, the number of attributes describing each tuple.
Rain Forest is a scalable algorithm for decision tree induction. Develop a scalable naïve Bayesian classification algorithm that requires just a single scan of the entire data set for most databases. Discuss whether such an algorithm can be refined to incorporate boosting to further enhance its
Design an efficient method that performs effective naïve Bayesian classification over an infinite data stream (i.e., you can scan the data stream only once). If we wanted to discover the evolution of such classification schemes (e.g., comparing the classification scheme at this moment with earlier
The perceptron model y=f(x)=sign(wTx+b)y=f(x)=sign(wTx+b) can be used to learn a binary classifier from training data.a. Assume there are two training samples. The positive one is x1=(2,1)Tx1=(2,1)T; the negative one is x2=(1,0)Tx2=(1,0)T. The learning rate η=1η=1. Starting from w=(1,1)Tw=(1,1)T
Suppose we have three positive examples x1=(1,0,0),x2=(0,0,1)x1=(1,0,0),x2=(0,0,1) and x3=(0,1,0)x3=(0,1,0) and three negative examples x4=(−1,0,0),x5=(0,−1,0)x4=(−1,0,0),x5=(0,−1,0) and x6=(0,0,−1)x6=(0,0,−1). Apply standard gradient ascent method to train a logistic regression
Suppose that we are training a naïve Bayes classifier and a logistic regression classifier: ff : X→YX→Y, which maps a dd-dimensional real-valued feature vector X∈RdX∈Rd to a binary class label Y∈{0,1}Y∈{0,1}. In the naïve Bayes classifier, we assume that all XiXi where
Show that accuracy is a function of sensitivity and specificity, that is, prove Eq. (6.25). P (P + N) accuracy = sensitivity. N (P+N) + specificity. (6.25)
The harmonic mean is one of several kinds of averages. Chapter 2 discussed how to compute the arithmetic mean, which is what most people typically think of when they compute an average. The harmonic mean, HH, of the positive real numbers, x1,x2,…,xnx1,x2,…,xn, is defined asThe FF measure is the
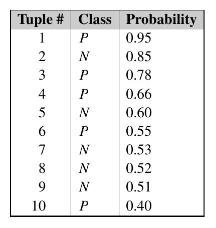
The data tuples of Fig. 6.28 are sorted by decreasing probability value, as returned by a classifier. For each tuple, compute the values for the number of true positives (TP)(TP), false positives (FP)(FP), true negatives (TN)(TN), and false negatives (FN)(FN). Compute the true positive rate
It is difficult to assess classification accuracy when individual data objects may belong to more than one class at a time. In such cases, comment on what criteria you would use to compare different classifiers modeled after the same data.
Suppose that we want to select between two prediction models, M1M1 and M2M2. We have performed 10 rounds of 10 -fold cross-validation on each model, where the same data partitioning in round ii is used for both M1M1 and M2M2. The error rates obtained for M1M1 are 30.5, 32.2, 20.7, 20.6, 31.0, 41.0,
What is boosting? State why it may improve the accuracy of decision tree induction.
Outline methods for addressing the class imbalance problem. Suppose a bank wants to develop a classifier that guards against fraudulent credit card transactions. Illustrate how you can induce a quality classifier based on a large set of legitimate examples and a very small set of fraudulent cases.
XGBoost is a scalable machine learning system for tree boosting. Its objective function has a training loss and a regularization term: L=∑il(),^yi)+∑kΩ(fk)L=∑il(yi,y^i)+∑kΩ(fk). Read the XGBoost paper and answer the following questions:a. What is ^yiy^i ? At the tt th iteration, XGBoost
What is data mining? In your answer, address the following:(a) Is it a simple transformation or application of technology developed from databases, statistics, machine learning, and pattern recognition?(b) Someone believes that data mining is an inevitable result of the evolution of information
Define each of the following data mining functionalities: association and correlation analysis, classification, regression, clustering, and outlier analysis.Give examples of each data mining functionality, using a real-life database that you are familiar with.
Present an example where data mining is crucial to the success of a business. What data mining functionalities does this business need (e.g., think of the kinds of patterns that could be mined)? Can such patterns be generated alternatively by data query processing or simple statistical analysis?
Explain the difference and similarity between correlation analysis and classification, between classification and clustering, and between classification and regression.
Based on your observations, describe another possible kind of knowledge that needs to be discovered by data mining methods but has not been listed in this chapter. Does it require a mining methodology that is quite different from those outlined in this chapter?
Outliers are often discarded as noise. However, one person’s garbage could be another’s treasure. For example, exceptions in credit card transactions can help us detect the fraudulent use of credit cards. Using fraud detection as an example, propose two methods that can be used to detect
Outline the major research challenges of data mining in one specific application domain, such as stream/sensor data analysis, spatiotemporal data analysis, or bioinformatics.
Showing 100 - 200
of 186
1
2
Step by Step Answers



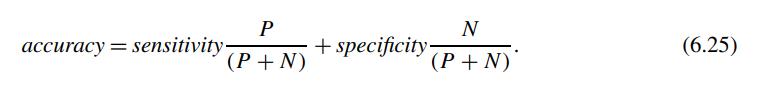
![H = || *] _i=l 72 1 12](https://dsd5zvtm8ll6.cloudfront.net/images/question_images/1705/5/8/2/98465a921880a70e1705582982622.jpg)

