New Semester
Started
Get
50% OFF
Study Help!
--h --m --s
Claim Now
Question Answers
Textbooks
Find textbooks, questions and answers
Oops, something went wrong!
Change your search query and then try again
S
Books
FREE
Study Help
Expert Questions
Accounting
General Management
Mathematics
Finance
Organizational Behaviour
Law
Physics
Operating System
Management Leadership
Sociology
Programming
Marketing
Database
Computer Network
Economics
Textbooks Solutions
Accounting
Managerial Accounting
Management Leadership
Cost Accounting
Statistics
Business Law
Corporate Finance
Finance
Economics
Auditing
Tutors
Online Tutors
Find a Tutor
Hire a Tutor
Become a Tutor
AI Tutor
AI Study Planner
NEW
Sell Books
Search
Search
Sign In
Register
study help
computer science
fundamentals of database systems
Fundamentals Of Database Systems 7th Edition Ramez Elmasri, Shamkant Navathe - Solutions
What are the main characteristics of NOSQL systems in the areas related to data models and query languages?
What are the main categories of NOSQL systems? List a few of the NOSQL systems in each category.
For which types of applications were NOSQL systems developed?
Consider that you have been asked to propose a database architecture in a large organization (General Motors, for example) to consolidate all data including legacy databases (from hierarchical and network models; no specific knowledge of these models is needed) as well as relational databases,
Consider the following relations:BOOKS(Book#, Primary_author, Topic, Total_stock, $price)BOOKSTORE(Store#, City, State, Zip, Inventory_value)STOCK(Store#, Book#, Qty)Total_stock is the total number of books in stock, and Inventory_value is the total inventory value for the store in dollars.a. Give
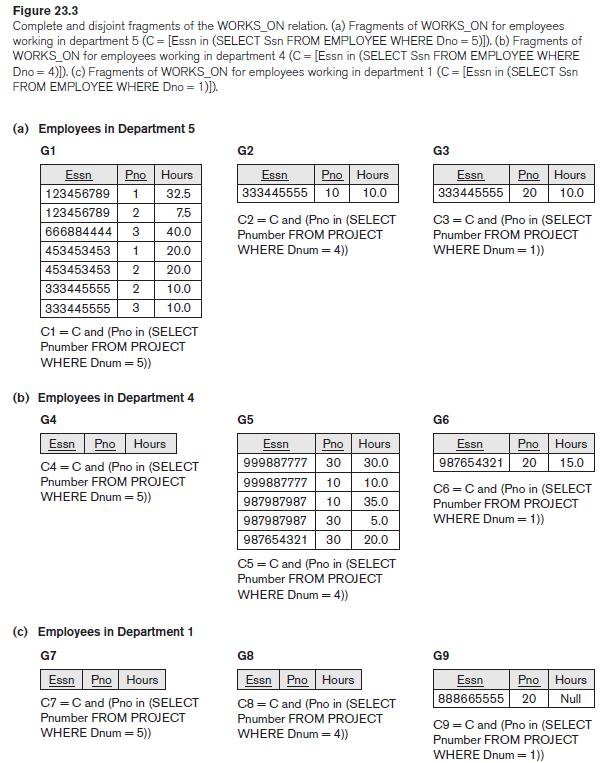
Consider the data distribution of the COMPANY database, where the fragments at sites 2 and 3 are as shown in Figure 23.3 and the fragments at site 1 are as shown in Figure 3.6. For each of the following queries, show at least two strategies of decomposing and executing the query. Under what
Discuss briefly online directories, their management, and their role in distributed databases.
Discuss briefly the support offered by Oracle for homogeneous, heterogeneous, and client/server-based distributed database architectures.
What are the main challenges facing a traditional DDBMS in the context of today’s Internet applications? How does cloud computing attempt to address them?
Discuss catalog management in distributed databases.
When are voting and elections used in distributed databases?
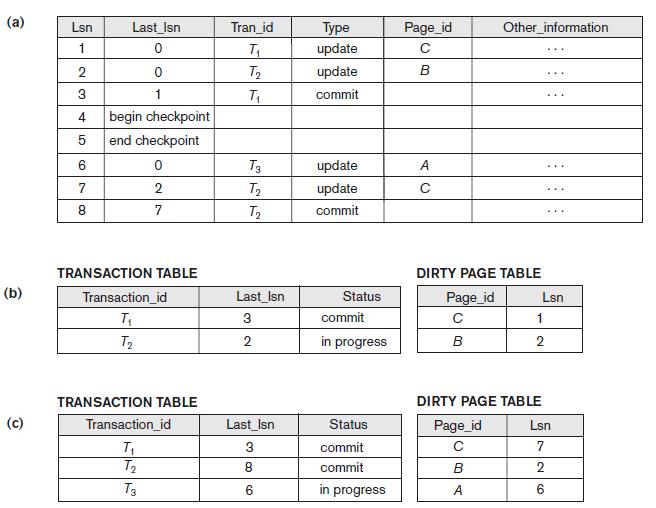
How are log sequence numbers used by ARIES to reduce the amount of REDO work needed for recovery? Illustrate with an example using the information shown in Figure 22.5. You can make your own assumptions as to when a page is written to disk.Figure 22.5
Suppose that we use the deferred update protocol for the example in Figure 22.6. Show how the log would be different in the case of deferred update by removing the unnecessary log entries; then describe the recovery process, using your modified log. Assume that only REDO operations are applied, and
Figure 22.6 shows the log corresponding to a particular schedule at the point of a system crash for four transactions T1, T2, T3, and T4. Suppose that we use the immediate update protocol with checkpointing. Describe the recovery process from the system crash. Specify which transactions are rolled
Discuss the two-phase commit protocol used for transaction management in a DDBMS. List its limitations and explain how they are overcome using the three-phase commit protocol.
List the support offered by operating systems to a DDBMS and also the benefits of these supports.
Discuss the factors that do not appear in centralized systems but that affect concurrency control and recovery in distributed systems.
How is the decomposition of an update request different from the decomposition of a query? How are guard conditions and attribute lists of fragments used during the decomposition of an update request?
Discuss the factors that affect query decomposition. How are guard conditions and attribute lists of fragments used during the query decomposition process?
Discuss the semijoin method for executing an equijoin of two files located at different sites. Under what conditions is an equijoin strategy efficient?
Discuss the different techniques for executing an equijoin of two files located at different sites. What main factors affect the cost of data transfer?
What are the different stages of processing a query in a DDBMS?
Discuss the naming problem in distributed databases.
How is a vertical partitioning of a relation specified? How can a relation be put back together from a complete vertical partitioning?
How is a horizontal partitioning of a relation specified? How can a relation be put back together from a complete horizontal partitioning?
What is meant by data allocation in distributed database design? What typical units of data are distributed over sites?
What is a fragment of a relation? What are the main types of fragments? Why is fragmentation a useful concept in distributed database design?
Compare the two-tier and three-tier client/server architectures.
What are the main software modules of a DDBMS? Discuss the main functions of each of these modules in the context of the client/server architecture.
Discuss the architecture of a DDBMS. Within the context of a centralized DBMS, briefly explain new components introduced by the distribution of data.
Discuss what is meant by the following terms: degree of homogeneity of a DDBMS, degree of local autonomy of a DDBMS, federated DBMS, distribution transparency, fragmentation transparency, replication transparency, multidatabase system.
What additional functions does a DDBMS have over a centralized DBMS?
What are the main reasons for and potential advantages of distributed databases?
If the shadowing approach is used for flushing a data item back to disk, thena. The item is written to disk only after the transaction commitsb. The item is written to a different location on diskc. The item is written to disk before the transaction commitsd. The item is written to the same disk
To cope with media (disk) failures, it is necessarya. For the DBMS to only execute transactions in a single user environmentb. To keep a redundant copy of the databasec. To never abort a transactiond. All of the above
There is a possibility of a cascading rollback whena. A transaction writes items that have been written only by a committed transactionb. A transaction writes an item that is previously written by an uncommitted transactionc. A transaction reads an item that is previously written by an uncommitted
Using a log-based recovery scheme might improve performance as well as provide a recovery mechanism bya. Writing the log records to disk when each transaction commitsb. Writing the appropriate log records to disk during the transaction’s executionc. Waiting to write the log records until multiple
For correct behavior during recovery, undo and redo operations must bea. Commutativeb. Associativec. Idempotentd. Distributive
For incremental logging with immediate updates, a log record for a transaction would containa. A transaction name, a data item name, and the old and new value of the itemb. A transaction name, a data item name, and the old value of the itemc. A transaction name, a data item name, and the new value
In case of transaction failure under a deferred update incremental logging scheme, which of the following will be needed?a. An undo operationb. A redo operationc. An undo and redo operationd. None of the above
The write-ahead logging (WAL) protocol simply means thata. Writing of a data item should be done ahead of any logging operationb. The log record for an operation should be written before the actual data is writtenc. All log records should be written before a new transaction begins executiond. The
Incremental logging with deferred updates implies that the recovery system musta. Store the old value of the updated item in the logb. Store the new value of the updated item in the logc. Store both the old and new value of the updated item in the logd. Store only the Begin Transaction and Commit
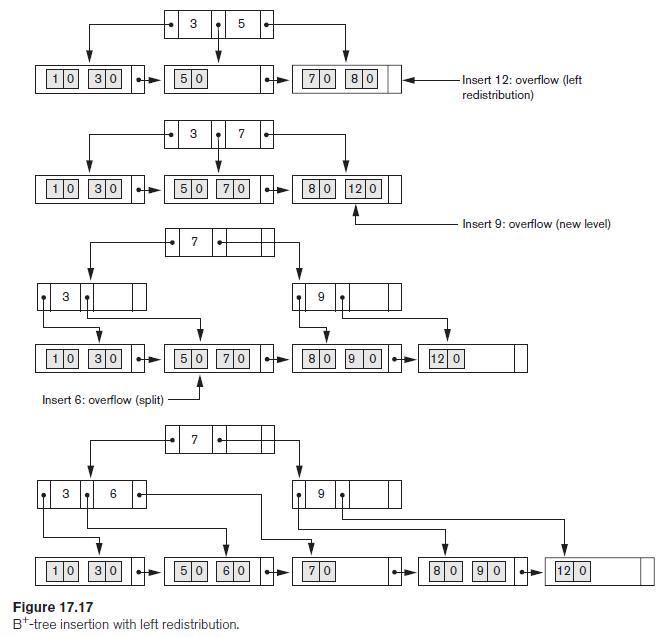
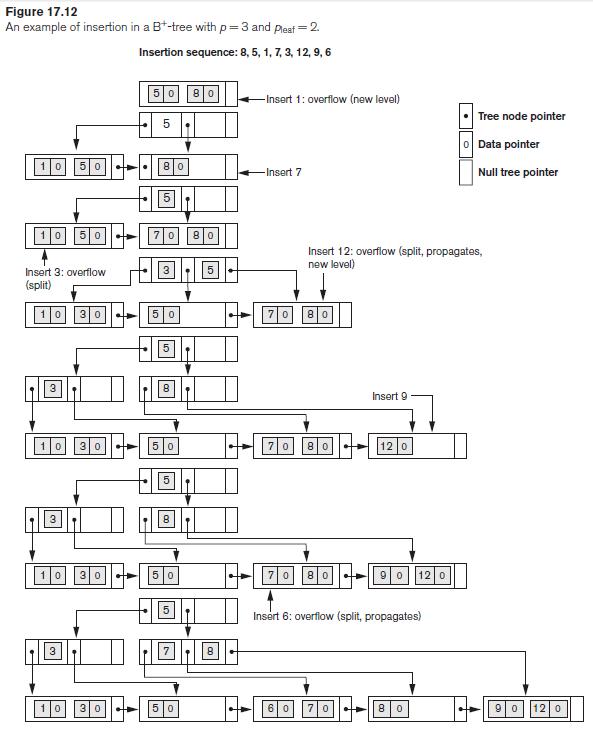
It is possible to modify the B+-tree insertion algorithm to delay the case where a new level is produced by checking for a possible redistribution of values among the leaf nodes. Figure 17.17 illustrates how this could be done for our example in Figure 17.12; rather than splitting the leftmost leaf
How are aggregate operations implemented?
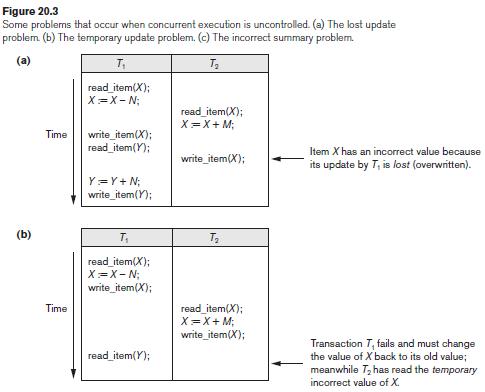
Add the operation commit at the end of each of the transactions T1 and T2 in Figure 20.2, and then list all possible schedules for the modified transactions. Determine which of the schedules are recoverable, which are cascadeless, and which are strict. (a) (b) T2 read_item(X); X=X-
List all possible schedules for transactions T1 and T2 in Figure 20.2, and determine which are conflict serializable (correct) and which are not.Figure 20.2 (a) (b) T2 read_item(X); X=X+ M; write_item(X); Figure 20.2 Two sample transactions. (a) Transaction T1. (b) Transaction T read_item(X); X=X -
How many serial schedules exist for the three transactions in Figure 20.8(a)? What are they? What is the total number of possible schedules?Figure 20.8(a) Figure 20.8 Another example of serializability testing. (a) The read and write operations of three transactions T1, T2, and T3. (b) Schedule E.
How do optimistic concurrency control techniques differ from other concurrency control techniques? Why are they also called validation or certification techniques? Discuss the typical phases of an optimistic concurrency control method.
What is snapshot isolation? What are the advantages and disadvantages of concurrency control methods that are based on snapshot isolation?
Describe the write-ahead logging protocol.
Identify three typical lists of transactions that are maintained by the recovery subsystem.
What is meant by transaction rollback? What is meant by cascading rollback? Why do practical recovery methods use protocols that do not permit cascading rollback? Which recovery techniques do not require any rollback?
Discuss the UNDO and REDO operations and the recovery techniques that use each.
Discuss the deferred update technique of recovery. What are the advantages and disadvantages of this technique? Why is it called the NO UNDO/REDO method?
How can recovery handle transaction operations that do not affect the database, such as the printing of reports by a transaction?
Repeat Exercise 20.14, adding a check in T1 so that Y does not exceed 90.Exercise 20.14Change transaction T2 in Figure 20.2(b) to readread_item(X);X := X + M;if X > 90 then exitelse write_item(X);Discuss the final result of the different schedules in Figures 20.3(a) and (b), where M = 2 and N =
Write programs that implement Algorithms 15.4 and 15.5.Algorithm 15.4 Relational Synthesis into 3NF with Dependency Preservation and Nonadditive Join PropertyInput: A universal relation R and a set of functional dependencies F on the attributes of R.1. Find a minimal cover G for F (use Algorithm
How have new iSCSI systems improved the applicability of storage area networks?
A file has r = 20,000 STUDENT records of fixed length. Each record has the following fields: Name (30 bytes), Ssn (9 bytes), Address (40 bytes), PHONE (10 bytes), Birth_date (8 bytes), Sex (1 byte), Major_dept_code (4 bytes), Minor_dept_code (4 bytes), Class_code (4 bytes, integer), and
Suppose that the following search field values are deleted, in the given order, from the B+-tree of Exercise 17.19; show how the tree will shrink and show the final tree. The deleted values are 65, 75, 43, 18, 20, 92, 59, 37.Exercise 17.19A PARTS file with Part# as the key field includes records
Write a program to create all possible schedules for the three transactions in Figure 20.8(a), and to determine which of those schedules are conflict serializable and which are not. For each conflict-serializable schedule, your program should print the schedule and list all equivalent serial
Adapt Algorithms 17.2 and 17.3, which outline search and insertion procedures for a B+-tree, to a B-tree.Algorithm 17.2. Searching for a Record with Search Key Field Value K, Using a B+-Treen ← block containing root node of B+-tree;read block n;while (n is not a leaf node of the B+-tree) dobeginq
What are the problems associated with keeping views materialized?
Estimate the cost of operations OP6 and OP7 using the formulas developed in Exercise 19.19.Exercise 19.19Develop formulas for the hybrid hash-join algorithm for calculating the size of the buffer for the first bucket. Develop more accurate cost estimation formulas for the algorithm.
Which of the following schedules is (conflict) serializable? For each serializable schedule, determine the equivalent serial schedules.a. r1(X); r3(X); w1(X); r2(X); w3(X);b. r1(X); r3(X); w3(X); w1(X); r2(X);c. r3(X); r2(X); w3(X); r1(X); w1(X);d. r3(X); r2(X); r1(X); w3(X); w1(X);
Consider the three transactions T1, T2, and T3, and the schedules S1 and S2 given below. Draw the serializability (precedence) graphs for S1 and S2, and state whether each schedule is serializable or not. If a schedule is serializable, write down the equivalent serial schedule(s).T1: r1 (X);
Discuss the problems of deadlock and starvation, and the different approaches to dealing with these problems.
Compare binary locks to exclusive/shared locks. Why is the latter type of locks preferable?
What is a timestamp? How does the system generate timestamps?
What type of lock is needed for insert and delete operations?
The compatibility matrix in Figure 21.8 shows that IS and IX locks are compatible. Explain why this is valid. IS IX S SIX IS Yes Yes Yes Yes No IX Yes Yes No No No S Yes No Yes No No SIX Yes No No No No Figure 21.8 Lock compatibility matrix for multiple granularity locking. X No No No No No
Discuss two multiversion techniques for concurrency control. What is a certify lock? What are the advantages and disadvantages of using certify locks?
What is multiple granularity locking? Under what circumstances is it used?
What are intention locks?
When are latches used?
What is a phantom record? Discuss the problem that a phantom record can cause for concurrency control.
How does index locking resolve the phantom problem?
What is a predicate lock?
The MGL protocol states that a transaction T can unlock a node N, only if none of the children of node N are still locked by transaction T. Show that without this condition, the MGL protocol would be incorrect.
Discuss the different types of transaction failures. What is meant by catastrophic failure?
What is the system log used for? What are the typical kinds of entries in a system log? What are checkpoints, and why are they important? What are transaction commit points, and why are they important?
How are buffering and caching techniques used by the recovery subsystem?
What are the before image (BFIM) and after image (AFIM) of a data item? What is the difference between in-place updating and shadowing, with respect to their handling of BFIM and AFIM?
What are UNDO-type and REDO-type log entries?
Discuss the immediate update recovery technique in both single-user and multiuser environments. What are the advantages and disadvantages of immediate update?
Change transaction T2 in Figure 20.2(b) to readread_item(X);X := X + M;if X > 90 then exitelse write_item(X);Discuss the final result of the different schedules in Figures 20.3(a) and (b), where M = 2 and N = 2, with respect to the following questions: Does adding the above condition change the
Define the violations caused by each of the following: dirty read, nonrepeatable read, and phantoms.
Describe the four levels of isolation in SQL. Also discuss the concept of snapshot isolation and its effect on the phantom record problem.
Discuss how serializability is used to enforce concurrency control in a database system. Why is serializability sometimes considered too restrictive as a measure of correctness for schedules?
What is the difference between the constrained write and the unconstrained write assumptions? Which is more realistic?
What is a serial schedule? What is a serializable schedule? Why is a serial schedule considered correct? Why is a serializable schedule considered correct?
Discuss the different measures of transaction equivalence. What is the difference between conflict equivalence and view equivalence?
What is a schedule (history)? Define the concepts of recoverable, cascadeless, and strict schedules, and compare them in terms of their recoverability.
Discuss the atomicity, durability, isolation, and consistency preservation properties of a database transaction.
What is the system log used for? What are the typical kinds of records in a system log? What are transaction commit points, and why are they important?
Draw a state diagram and discuss the typical states that a transaction goes through during execution.
Discuss the different types of failures. What is meant by catastrophic failure?
What is meant by the concurrent execution of database transactions in a multiuser system? Discuss why concurrency control is needed, and give informal examples.
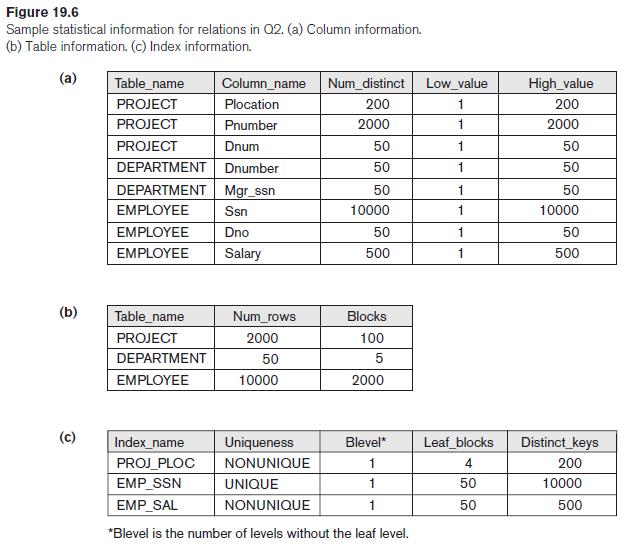
Compare the cost of two different query plans for the following query:σSalary< 40000(EMPLOYEE ∞ Dno=DnumberDEPARTMENT)Use the database statistics shown in Figure 19.6.Figure 19.6 Figure 19.6 Sample statistical information for relations in Q2. (a) Column information. (b) Table information. (c)
Develop formulas for the hybrid hash-join algorithm for calculating the size of the buffer for the first bucket. Develop more accurate cost estimation formulas for the algorithm.
Showing 200 - 300
of 606
1
2
3
4
5
6
7
Step by Step Answers