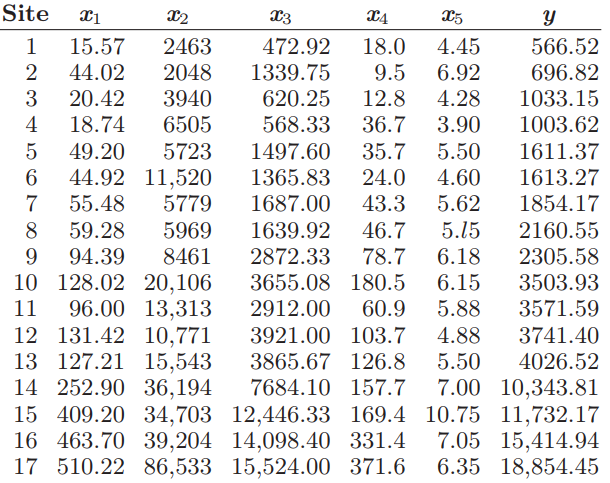
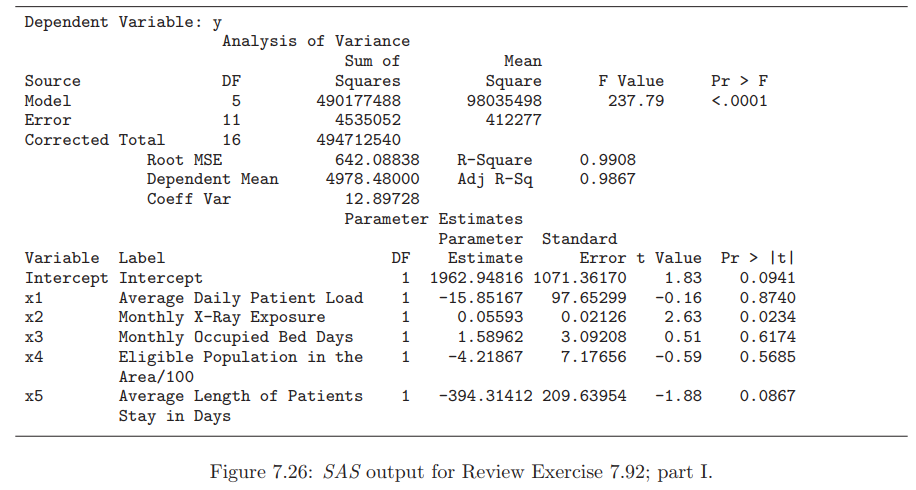
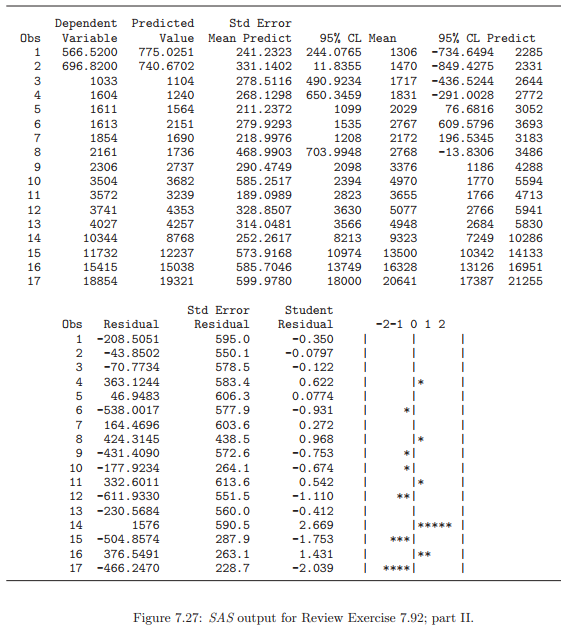
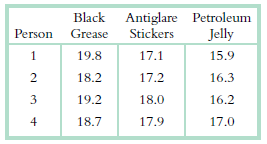
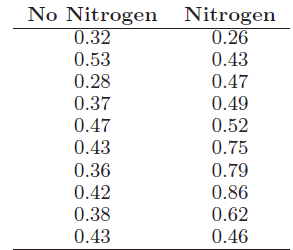
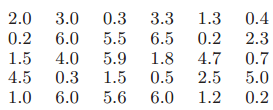
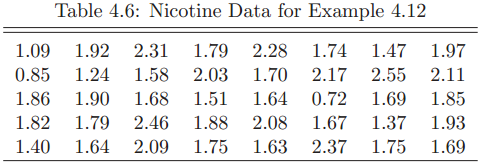
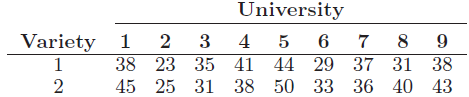
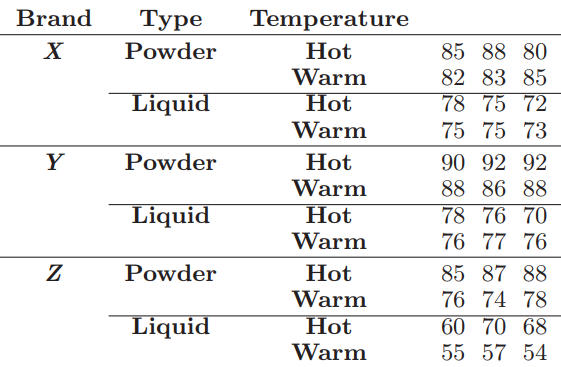
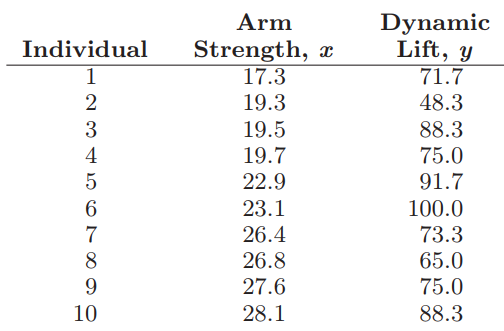
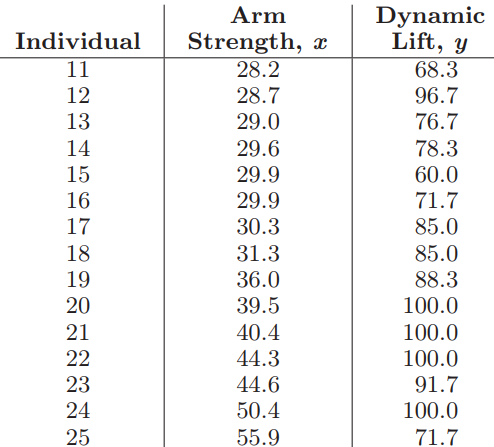
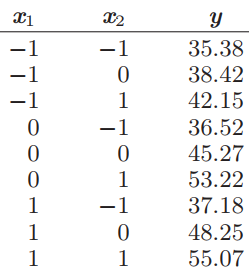
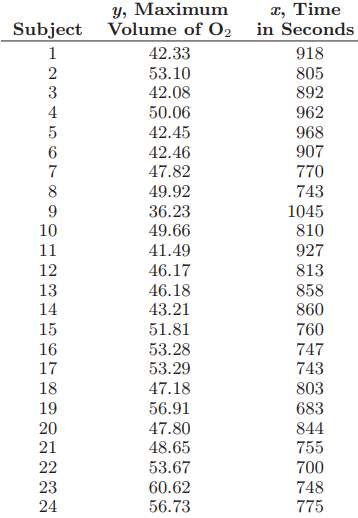
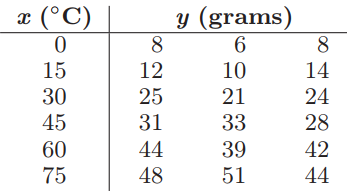
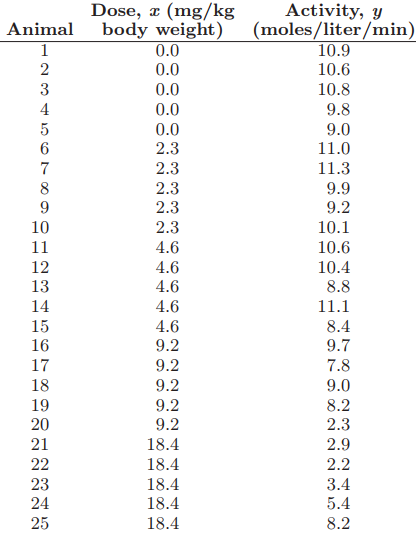
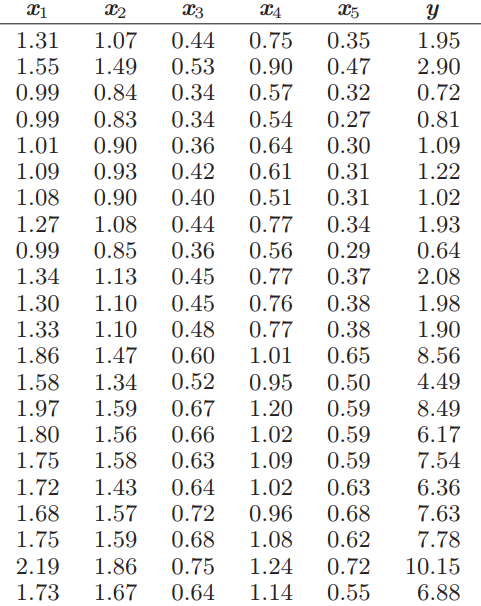
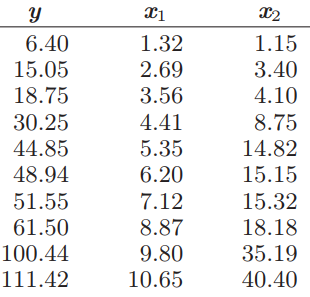
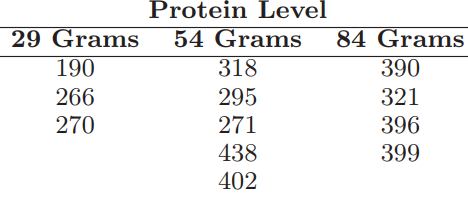
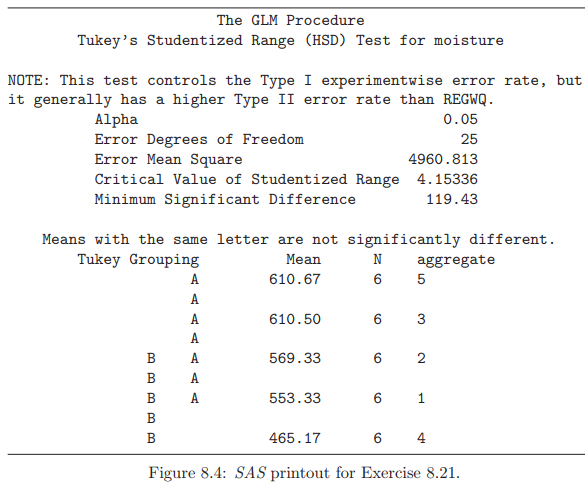
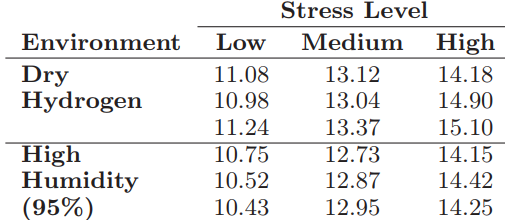
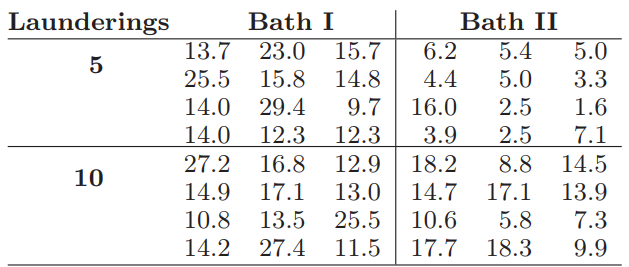
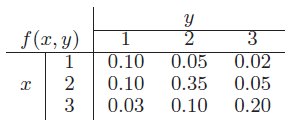
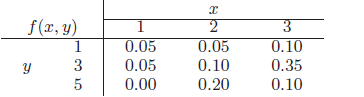
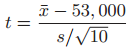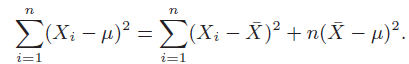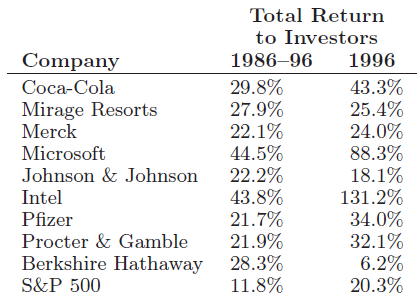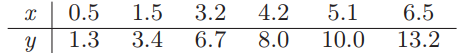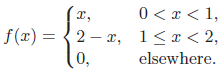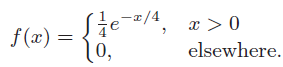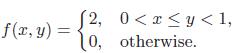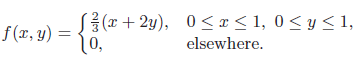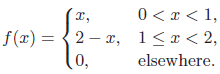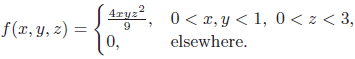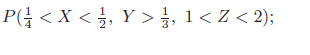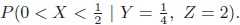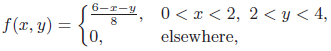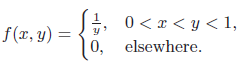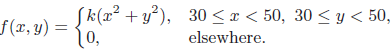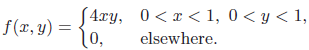Essentials Of Probability And Statistics For Engineers And Scientists 1st Edition Ronald E. Walpole, Raymond Myers, Sharon L. Myers, Keying E. Ye - Solutions
Enhance your understanding of probability and statistics with our comprehensive resources for "Essentials Of Probability And Statistics For Engineers And Scientists 1st Edition" by Ronald E. Walpole, Raymond Myers, Sharon L. Myers, and Keying E. Ye. Dive into our online answers key and explore detailed solutions in our solutions PDF. Whether you're looking for solved problems, questions and answers, or chapter solutions, our solution manual provides step-by-step answers to guide your learning. Access our test bank and instructor manual for a thorough grasp of the textbook material. Enjoy free download options to support your academic success!