

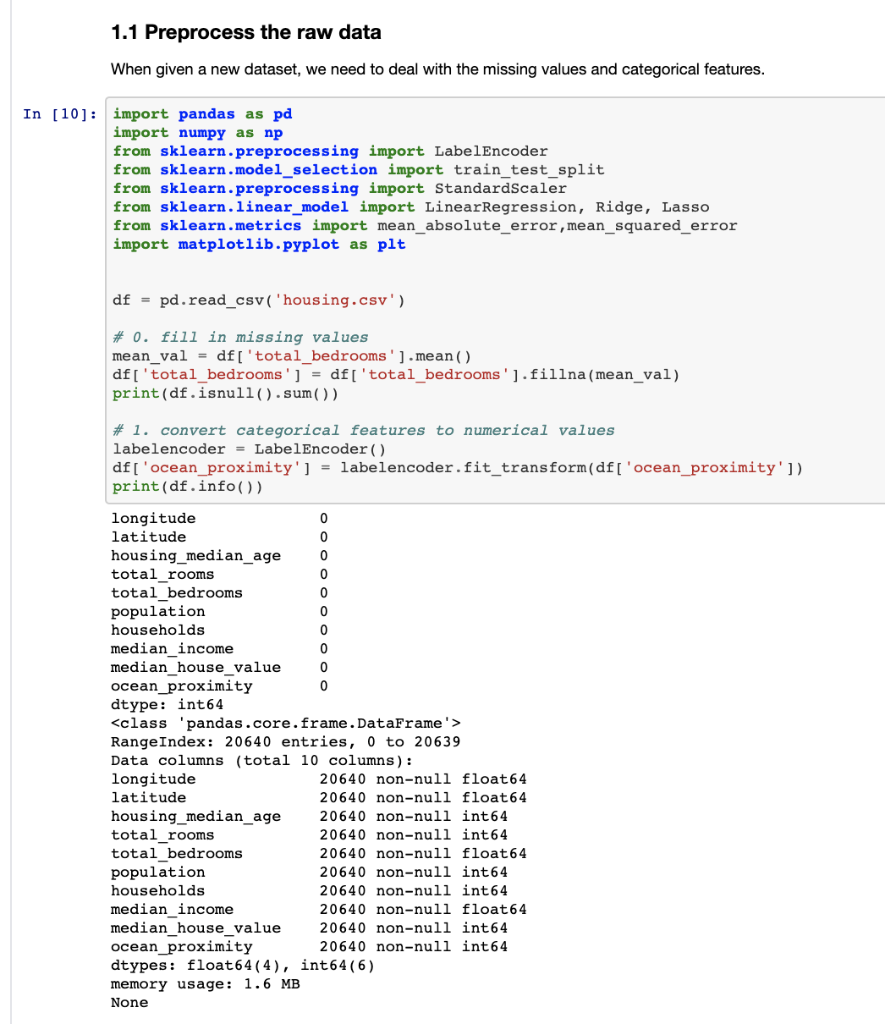
Question: 1.1 Preprocess the raw data When given a new dataset, we need to deal with the missing values and categorical features. In [10]; import pandas
![need to deal with the missing values and categorical features. In [10];](https://dsd5zvtm8ll6.cloudfront.net/si.experts.images/questions/2024/09/66f3e3f0a3bbd_63266f3e3f03c732.jpg)
1.1 Preprocess the raw data When given a new dataset, we need to deal with the missing values and categorical features. In [10]; import pandas as pd import numpy as np from sklearn.preprocessing import LabelEncoder from sklearn.model_selection import train_test_split from sklearn.preprocessing import StandardScaler from sklearn.linear_model import LinearRegression, Ridge, Lasso from sklearn.metrics import mean_absolute_error, mean_squared_error import matplotlib.pyplot as plt df = pd.read_csv('housing.csv') # 0. fill in missing values mean_val = df['total_bedrooms ' ) .mean() df ['total_bedrooms'] = df['total_bedrooms'].fillna(mean_val) print (df.isnull().sum()) # 1. convert categorical features to numerical values labelencoder = LabelEncoder() df['ocean_proximity'] = labelencoder.fit_transform(df['ocean_proximity']) print (df.info()) 0 longitude 0 latitude 0 housing_median_age 0 total rooms 0 total bedrooms 0 population 0 households 0 median_income 0 median_house_value ocean_proximity 0 dtype: int64
Step by Step Solution
There are 3 Steps involved in it

Get step-by-step solutions from verified subject matter experts