

Question: . Assume a single-issue pipeline. Show how the loop would look both unscheduled by the compiler and after compiler scheduling for both floating-point operation and
. Assume a single-issue pipeline. Show how the loop would look both unscheduled by the compiler and after compiler scheduling for both floating-point operation and branch delays, including any stalls or idle clock cycles. What is the execution time (in cycles) per element of the result vector, Y, unscheduled and scheduled? How much faster must the clock be for processor hardware alone to match the performance improvement achieved by the scheduling compiler? (Neglect any possible effects of increased clock speed on memory system performance.)
b. Assume a single-issue pipeline. Unroll the loop as many times as necessary to schedule it without any stalls, collapsing the loop overhead instructions. How many times must the loop be unrolled? Show the instruction schedule. Make a table to show the execution time per element of the result for each unrolling until stalls are eliminated.
.
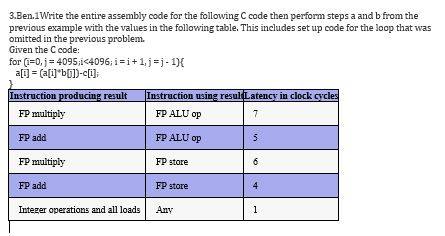
3.Ben. Write the entire assembly code for the following C code then perform steps a and b from the previous example with the values in the following table. This includes set up code for the loop that was omitted in the previous problem. Given the C code: for(i=0, j = 4095;i
Step by Step Solution
There are 3 Steps involved in it

Get step-by-step solutions from verified subject matter experts