

Question: Computer Science Data Mining Machine Learning Given the following FIT and Test data sets: FIT DATA SET: Program Modules Actual no of Faults (Y) 0
Computer Science Data Mining Machine Learning
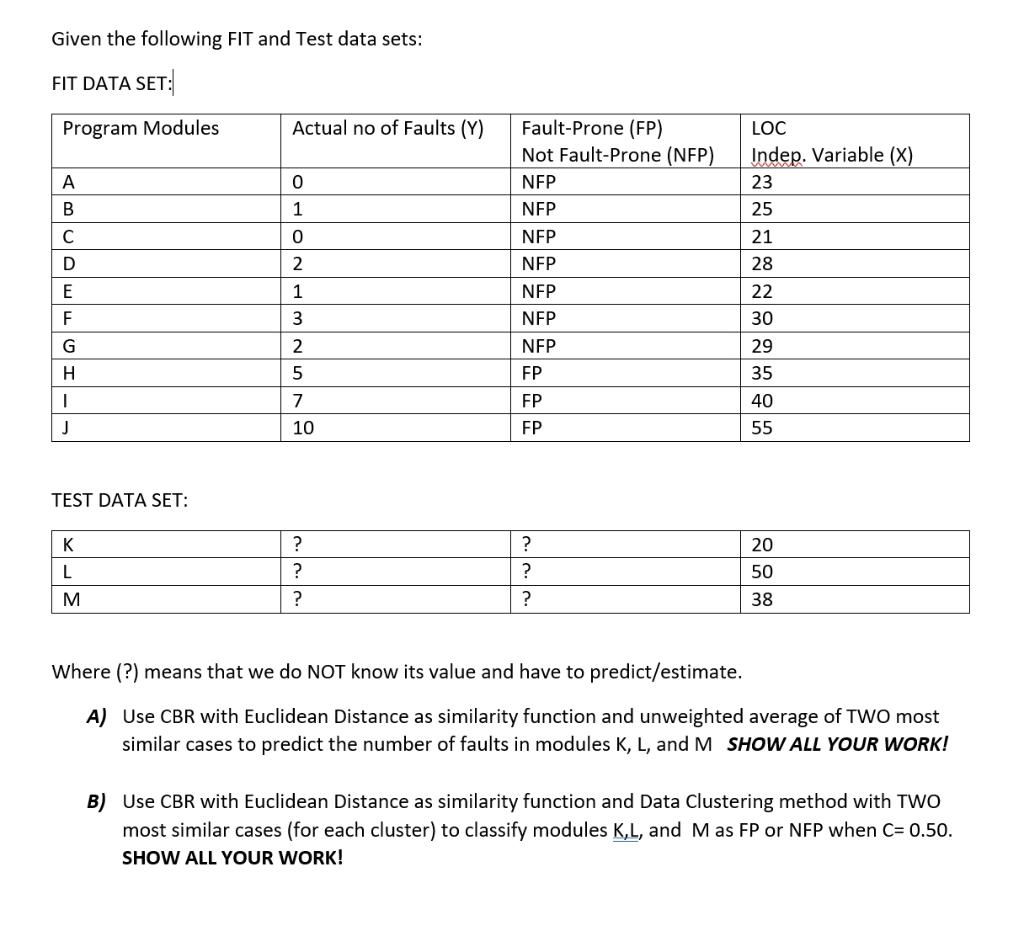
Given the following FIT and Test data sets: FIT DATA SET: Program Modules Actual no of Faults (Y) 0 A B 1 0 2 Fault-Prone (FP) Not Fault-Prone (NFP) NEP NEP NEP NEP NEP NEP NEP FP FP LOC Indep. Variable (X) 23 25 21 28 22. 30 29 35 D E 1 F 3 G H 2 5 7 10 I J 40 55 FP TEST DATA SET: L ? ? ? ? ? ? 20 50 M 38 Where (?) means that we do NOT know its value and have to predict/estimate. A) Use CBR with Euclidean Distance as similarity function and unweighted average of TWO most similar cases to predict the number of faults in modules K, L, and M SHOW ALL YOUR WORK! B) Use CBR with Euclidean Distance as similarity function and Data Clustering method with TWO most similar cases (for each cluster) to classify modules K,L, and Mas FP or NFP when C= 0.50. SHOW ALL YOUR WORK! Given the following FIT and Test data sets: FIT DATA SET: Program Modules Actual no of Faults (Y) 0 A B 1 0 2 Fault-Prone (FP) Not Fault-Prone (NFP) NEP NEP NEP NEP NEP NEP NEP FP FP LOC Indep. Variable (X) 23 25 21 28 22. 30 29 35 D E 1 F 3 G H 2 5 7 10 I J 40 55 FP TEST DATA SET: L ? ? ? ? ? ? 20 50 M 38 Where (?) means that we do NOT know its value and have to predict/estimate. A) Use CBR with Euclidean Distance as similarity function and unweighted average of TWO most similar cases to predict the number of faults in modules K, L, and M SHOW ALL YOUR WORK! B) Use CBR with Euclidean Distance as similarity function and Data Clustering method with TWO most similar cases (for each cluster) to classify modules K,L, and Mas FP or NFP when C= 0.50. SHOW ALL YOUR WORK
Step by Step Solution
There are 3 Steps involved in it

Get step-by-step solutions from verified subject matter experts