

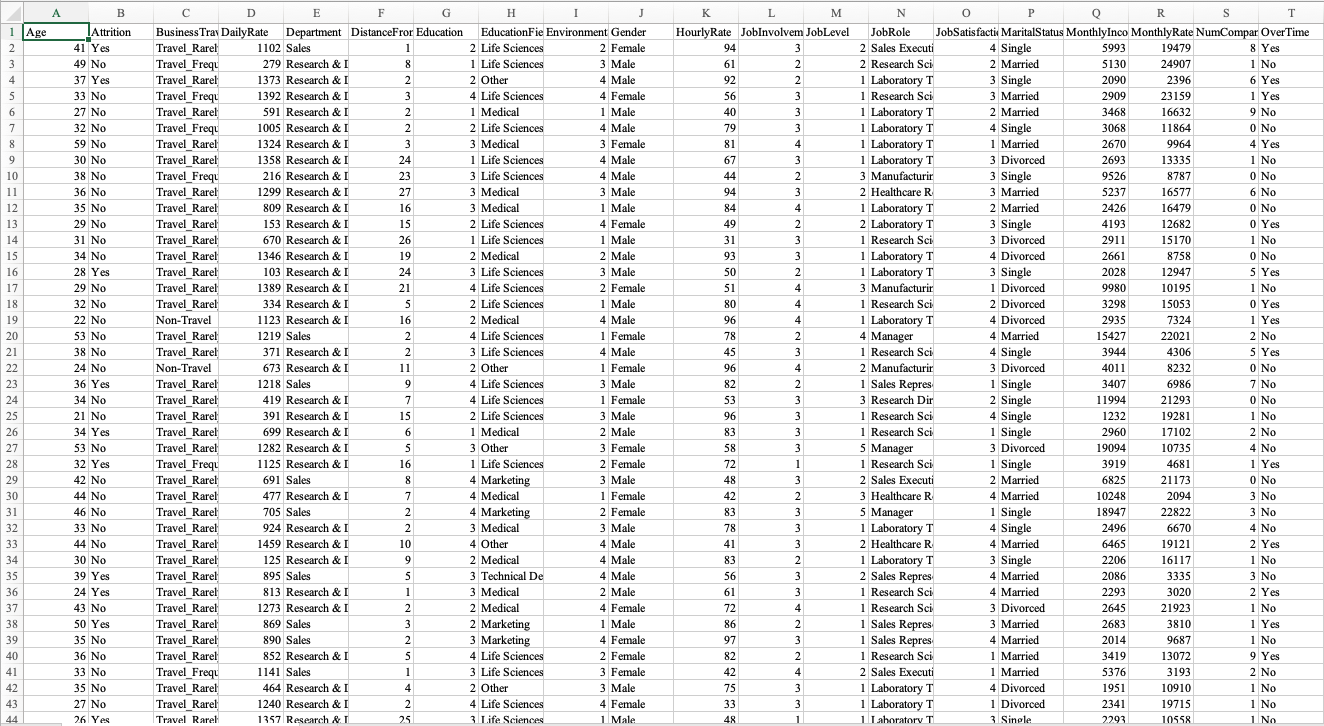
Question: From all the attributes available in the file, pick one numeric attribute to be the dependent variable (y), and pick five (or more if you
From all the attributes available in the file, pick one numeric attribute to be the dependent variable (y), and pick five (or more if you prefer) other reasonable numeric attributes as the independent variables (X). The final data after processing should be stored in a variable whose type is DataFrame.
Instead of using functions from pandas, use file reading/writing and while/for loops to process each line in the data file to perform the same task described in the previous question (i.e., pick y and X, and store as a DataFrame). You should first save Assignment-Q2-IBM-Data-Clean.xlsx as a CSV (comma delimited) file before using open() to open it. Tip: You can open one file for reading and one new file for writing. For each line, use list indexing to select the attributes you need to write to the new file. Use string concatenation to construct the new line to be written to the new file. After the new file is closed, you can use read_csv() to convert it to DataFrame.
Step by Step Solution
There are 3 Steps involved in it

Get step-by-step solutions from verified subject matter experts