

Question: Hello, I don't know how to do this question. Can you help me to solve it with code in Python? Thank you so much! Getting
Hello, I don't know how to do this question. Can you help me to solve it with code in Python? Thank you so much!
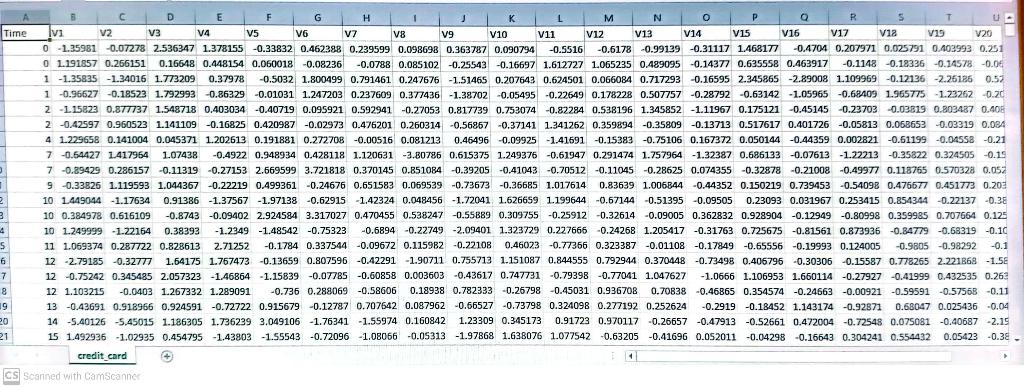

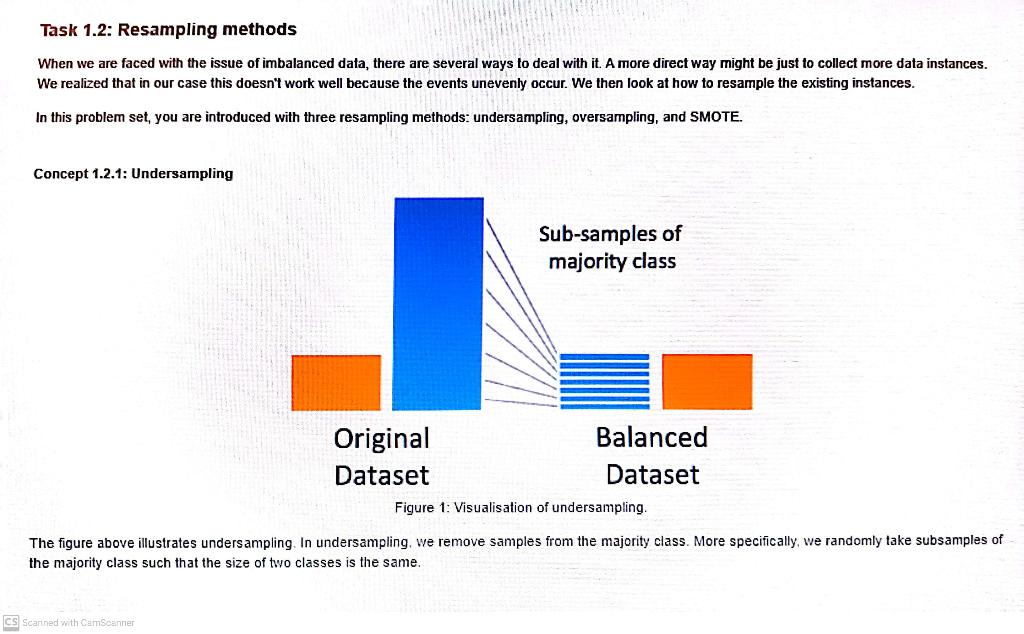
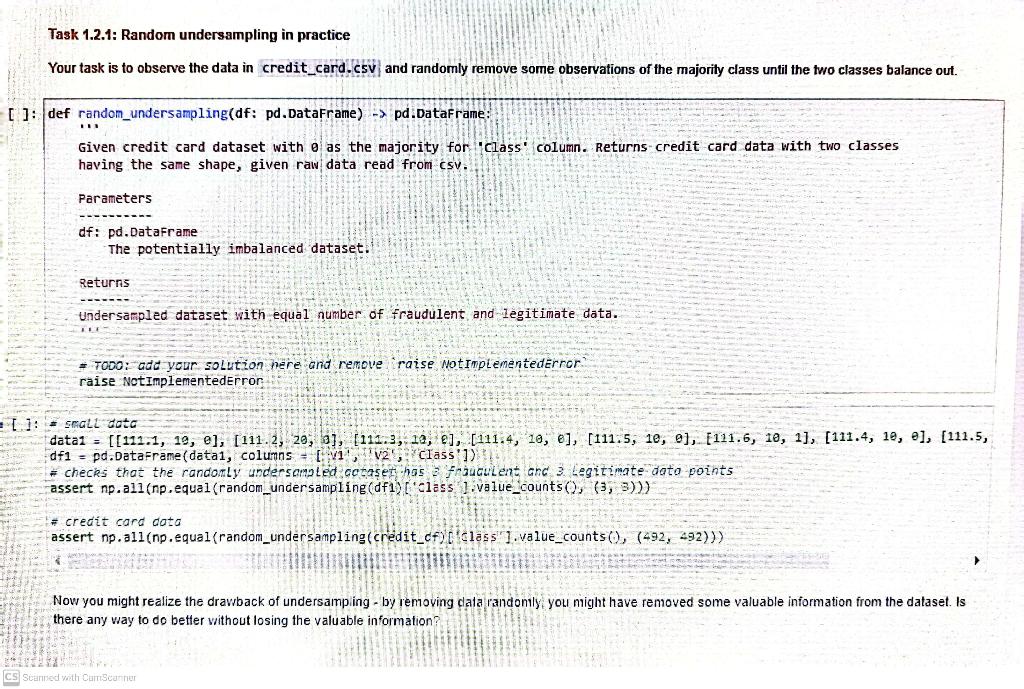
Getting Started Take a look at the columns in the dataset credit_card.csv. We have V1-V20, 'Amount', and 'Time' as input features, and 'Class' as output which takes the value 1 if it's fraud and 0 otherwise. This dataset presents 492 frauds out of 284,807 transactions. That means, there are 284,808 rows (including the header) in the csv file. We will use this dataset to implement logistic regression using batch and stochastic gradient descent for binary classification. \#Initial imports and setup import numpy as np import os import pandas as pd from sklearn import svm from sklearn import model_selection \# Read credit card data into a pandas dataframe for Large tests dirname = os.getcwd() credit_card_data_filepath = os.path.join(dirname, 'credit_card.csv') restaurant_data_filepath = os.path.join(dirname, 'restaurant_data.csv') credit_df = pd.read_csv(credit_card_data_filepath) X= credit_df.values [:,:1] y= credit_df.values[ :,1:] credit_df_head() NameError Traceback (most recent call last) 1 credit_df. head() NameError: name "credit_df" is not defined Next, we can inspect the value counts of the 'Class' property in the dataframe to know the number of fraudulent and non-fraudulent transactions. I: Inspect the number of froudulent and non-fraudulent transactions. credit_df['Cless'].value_counts() Indexing and selecting data Similar to NumPy, we can also index and select data on Pandas dataframes. For example, we can select columns in the dataframe by their labels. In the following example, we use to index the 'Class' column in the credit dataframe. * Select the 'class' column in the credit dataframe credit_df['Class'] Or, we can use integer indexing. H Cr We can also select colunins in the dataframe that fulfils some condition. In the example below, credit_df [' Class'] == returns a Pandas Series of length 284807 , which is the size of our dataset. It contains the value True if and only if the class value for the particular entry is of value 0 , and False otherwise. We can use this Boolean series to index the credit dataframe to return the rows where the Class field is 0 . Does this remind you of how NumPy arrays operate? * obtain the credit actafrane where the 'class' fiela is 0 credit_df[credit_df['Class'] ==0] You can also concatenate Pandas series or dataframes together! In this example. We explored how we can concat the first 2 rows and last 2 rows of the dataframe. Similar to NumPy. you would also need to specify the axis for concatenation. pd. concat([credit_df [:2], credit_df [2:]], axis =0) Task 1.2: Resampling methods When we are faced with the issue of imbalanced data, there are several ways to deal with it. A more direct way might be just to collect more data instances. We realized that in our case this doesn't work well because the events unevenly occur. We then look at how to resample the existing instances. In this problem set, you are introduced with three resampling methods: undersampling, oversampling, and SMOTE. Concept 1.2.1: Undersampling rigute 1. VIsualisaliun ui umuersanimg. The figure above illustrates undersampling. In undersampling. we remove samples from the majority class. More specifically, we randomly take subsamples of the majority class such that the size of two classes is the same. Task 1.2.1: Random undersampling in practice Your task is to observe the data in credit_card.C5V] and randomly remove some observations of the majority class until the two classes balance out. ]: def random_undersampling(df: pd.Dataframe) pd.DataFrame: Given credit card dataset with o as the majority for 'class' column. Returns-credit card data with two classes having the same shape, given raw data read from csv. Parameters df: pd. Dataframe The potentially imbalanced dataset. Returns Undersampled dataset with equal number of fraudulent and legitimate data. * Tooo: add your solution here and remove raise Notimplementederror raise notimplementederror: Now you might realize the drawback of undersamping - by removing clala randonly you might have removed some valuable information from the dataset. Is there any way to do better without losing the valuable information? Getting Started Take a look at the columns in the dataset credit_card.csv. We have V1-V20, 'Amount', and 'Time' as input features, and 'Class' as output which takes the value 1 if it's fraud and 0 otherwise. This dataset presents 492 frauds out of 284,807 transactions. That means, there are 284,808 rows (including the header) in the csv file. We will use this dataset to implement logistic regression using batch and stochastic gradient descent for binary classification. \#Initial imports and setup import numpy as np import os import pandas as pd from sklearn import svm from sklearn import model_selection \# Read credit card data into a pandas dataframe for Large tests dirname = os.getcwd() credit_card_data_filepath = os.path.join(dirname, 'credit_card.csv') restaurant_data_filepath = os.path.join(dirname, 'restaurant_data.csv') credit_df = pd.read_csv(credit_card_data_filepath) X= credit_df.values [:,:1] y= credit_df.values[ :,1:] credit_df_head() NameError Traceback (most recent call last) 1 credit_df. head() NameError: name "credit_df" is not defined Next, we can inspect the value counts of the 'Class' property in the dataframe to know the number of fraudulent and non-fraudulent transactions. I: Inspect the number of froudulent and non-fraudulent transactions. credit_df['Cless'].value_counts() Indexing and selecting data Similar to NumPy, we can also index and select data on Pandas dataframes. For example, we can select columns in the dataframe by their labels. In the following example, we use to index the 'Class' column in the credit dataframe. * Select the 'class' column in the credit dataframe credit_df['Class'] Or, we can use integer indexing. H Cr We can also select colunins in the dataframe that fulfils some condition. In the example below, credit_df [' Class'] == returns a Pandas Series of length 284807 , which is the size of our dataset. It contains the value True if and only if the class value for the particular entry is of value 0 , and False otherwise. We can use this Boolean series to index the credit dataframe to return the rows where the Class field is 0 . Does this remind you of how NumPy arrays operate? * obtain the credit actafrane where the 'class' fiela is 0 credit_df[credit_df['Class'] ==0] You can also concatenate Pandas series or dataframes together! In this example. We explored how we can concat the first 2 rows and last 2 rows of the dataframe. Similar to NumPy. you would also need to specify the axis for concatenation. pd. concat([credit_df [:2], credit_df [2:]], axis =0) Task 1.2: Resampling methods When we are faced with the issue of imbalanced data, there are several ways to deal with it. A more direct way might be just to collect more data instances. We realized that in our case this doesn't work well because the events unevenly occur. We then look at how to resample the existing instances. In this problem set, you are introduced with three resampling methods: undersampling, oversampling, and SMOTE. Concept 1.2.1: Undersampling rigute 1. VIsualisaliun ui umuersanimg. The figure above illustrates undersampling. In undersampling. we remove samples from the majority class. More specifically, we randomly take subsamples of the majority class such that the size of two classes is the same. Task 1.2.1: Random undersampling in practice Your task is to observe the data in credit_card.C5V] and randomly remove some observations of the majority class until the two classes balance out. ]: def random_undersampling(df: pd.Dataframe) pd.DataFrame: Given credit card dataset with o as the majority for 'class' column. Returns-credit card data with two classes having the same shape, given raw data read from csv. Parameters df: pd. Dataframe The potentially imbalanced dataset. Returns Undersampled dataset with equal number of fraudulent and legitimate data. * Tooo: add your solution here and remove raise Notimplementederror raise notimplementederror: Now you might realize the drawback of undersamping - by removing clala randonly you might have removed some valuable information from the dataset. Is there any way to do better without losing the valuable information
Step by Step Solution
There are 3 Steps involved in it

Get step-by-step solutions from verified subject matter experts