

Question: Matrix Multiplication using CUDA and implementation on Nvidia GPU 1) Declare matrix A of width 480 and height 800. 2) Declare matrix B of width

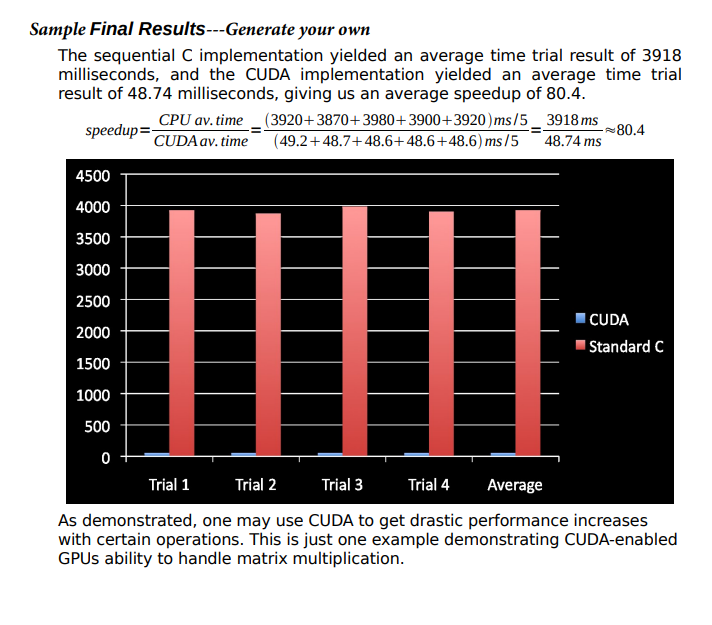

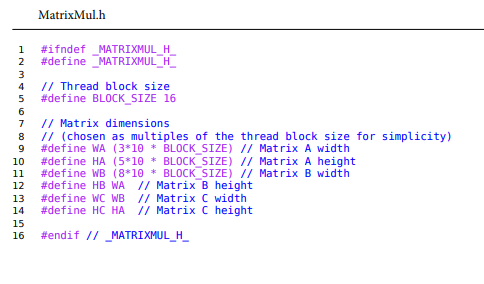


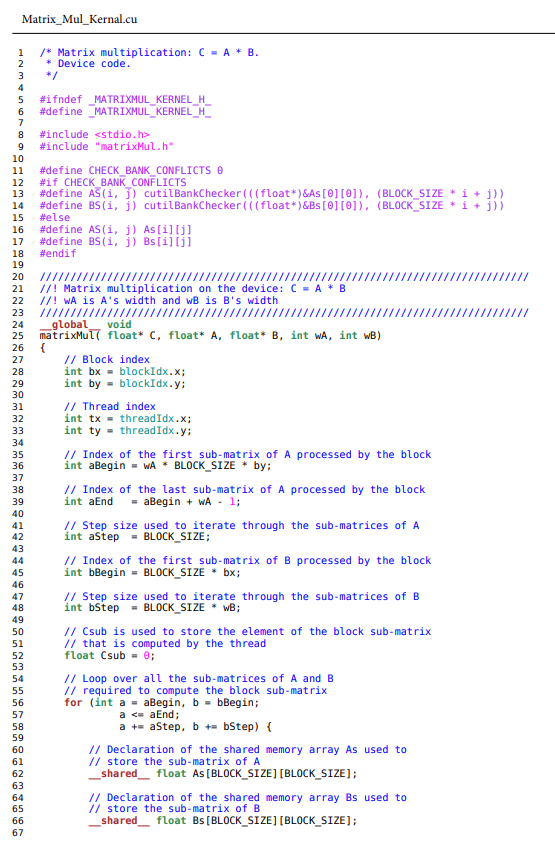

Matrix Multiplication using CUDA and implementation on Nvidia GPU 1) Declare matrix A of width 480 and height 800. 2) Declare matrix B of width 1280 and height 480. 3) Declare an answer matrix C of width 1280 and height 800 l. 4) Fill matrix A and B with random float values. 5) Start a stopwatch. 6) Multiply the two matrices and store the answer in matrix C. 7) Stop the stopwatch. 8) Report the time it took to perform the matrix multiplication operation. Sequential C Implementation The standard sequential C implementation of the matrix multiplier is strait forward. Five time trials of the matrix multiplication operations yielded 3920 , 3870,3980,3900, and 3920 milliseconds, yielding an average time of 3918 milliseconds. Please reference the attached MatrixMul.c source file for more details on implementation. imple Final Results-Generate your own The sequential C implementation yielded an average time trial result of 3918 milliseconds, and the CUDA implementation yielded an average time trial result of 48.74 milliseconds, giving us an average speedup of 80.4. speedup=CUDAav.timeCPUav.time=(49.2+48.7+48.6+48.6+48.6)ms/5(3920+3870+3980+3900+3920)ms/5=48.74ms3918ms80.4 As demonstrated, one may use CUDA to get drastic performance increases with certain operations. This is just one example demonstrating CUDA-enabled GPUs ability to handle matrix multiplication. MatrixMul.h \( \begin{aligned} 1 & \text { \#ifndef MATRIXMUL_H } \\ 2 & \text { \#define _MATRIXMUL_H_ } \\ 3 & \\ 4 & \text { // Thread block size } \\ 5 & \text { \#define BLOCK_SIZE } 16 \\ 6 & \\ 7 & \text { // Matrix dimensions } \\ 8 & \text { // (chosen as multiples of the thread block size for simplicity) } \\ 9 & \text { \#define WA (3*10 * BLOCK_SIZE) // Matrix A width } \\ 10 & \text { \#define HA (5*10 * BLOCK_SIZE) // Matrix A height } \\ 11 & \text { \#define WB (8*10 * BLOCK_SIZE) // Matrix B width } \\ 12 & \text { \#define HB WA // Matrix B height } \\ 13 & \text { \#define WC WB // Matrix C width } \\ 14 & \text { \#define HC HA // Matrix C height } \\ 15 & \\ 16 & \text { \#endif // _MATRIXMUL_H_ }\end{aligned} \) MatrixMul.cu Page 1 MatrixMulcu continued Matrix_Mul_Kernal.cu
Step by Step Solution
There are 3 Steps involved in it

Get step-by-step solutions from verified subject matter experts