

Question: Problem 4: GOAL: Understanding scheduling and loop unrolling* Instruction cing result Instruction using result Latency in clock cycles Another FP ALU Store double Branch FP
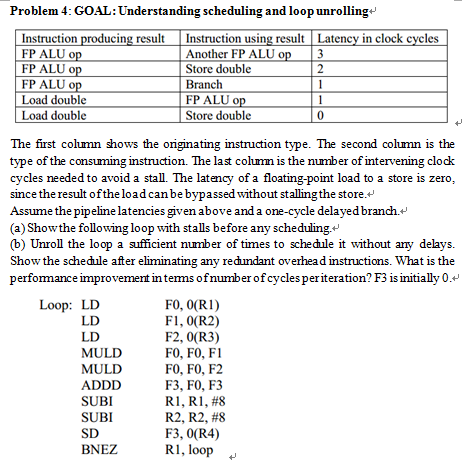
Problem 4: GOAL: Understanding scheduling and loop unrolling* Instruction cing result Instruction using result Latency in clock cycles Another FP ALU Store double Branch FP ALU Store double FP ALU FP ALUo FP ALU o Load double Load double The first column shows the originating instruction type. The second column is the type of the consuming instruction. The last colunm is the number of intervening clock cycles needed to avoid a stall. The latency of a floating-point load to a store is zero since the result oftheloadcanbe bypassed without stalling the store. Assume the pipeline latencies given above and a one-cycle delayed branch.^ (a) Showthe following loop with stalls before any scheduling. (b) Unroll the loop a sufficient number of times to schedule it without ary delays. Show the schecule after eliminating any recundant overhea d instructions. What is the performance improvement in terms ofnumber of cycles periteration? F3 is initially 0 F0, 0(RI) F1, 0(R2) F2, 0(R3) FO, FO, FI FO, FO, F2 F3, FO, F3 RI, RI, #8 R2, R2, #8 F3, 0(R4) R1, loop Loop: LD LD LD MULD MULD ADDD SUBI SUBI SD BNEZ
Step by Step Solution
There are 3 Steps involved in it

Get step-by-step solutions from verified subject matter experts