

Question: Project 3 - Data Mining for Intrusion Detection Recently there has been much interest in applying data mining to computer network intrusion detection. An

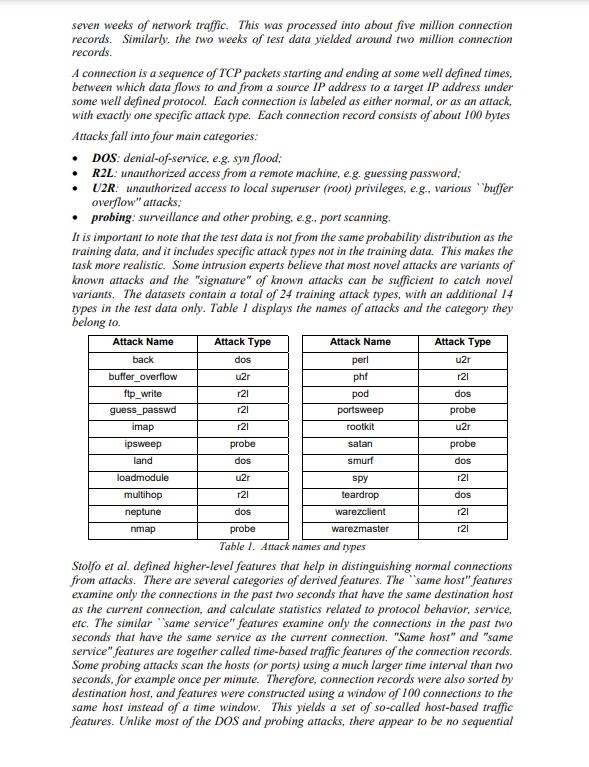
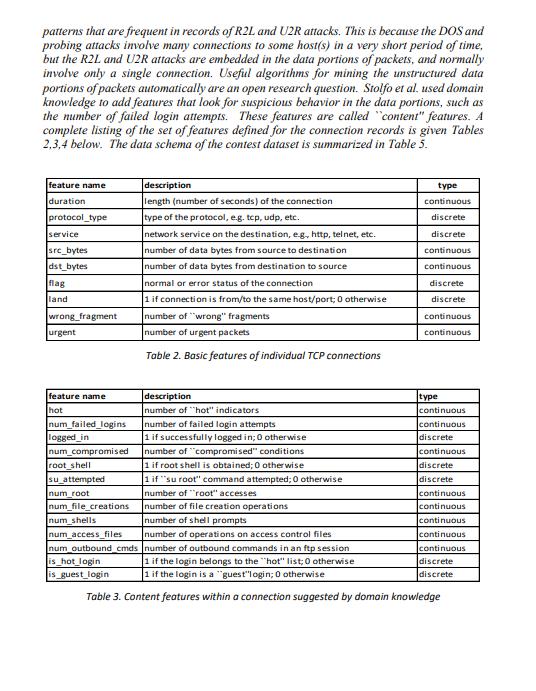
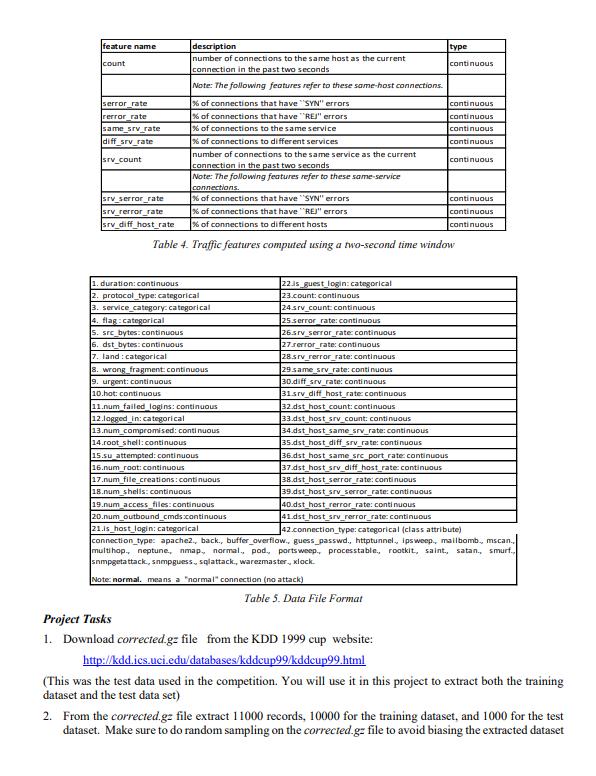

Project 3 - Data Mining for Intrusion Detection Recently there has been much interest in applying data mining to computer network intrusion detection. An intrusion can be defined as "any set of actions that attempt to compromise the integrity, confidentiality or availability of a resource"i. A network intrusion attack can compromise the stability or the security of the information stored in those computers connected to it. Considering that in today's world, companies depend on their physical networks and on their level of connectivity to survive, it comes at no surprise that the role of network intrusion detection has grown so rapidly. While there may still be different approaches as to what is the best way to protect a company's network, it is evident that an intrusion detection system is certainly an important asset among the group of tools used to secure the network architecture. Added security measures have failed in many cases to stop the wide variety of possible attacks. The goal of intrusion detection is to build a system that would automatically scan network activity and detect such intrusion attacks, providing the necessary information to the system administrator to allow for corrective actionii. A strong case can be made for the use of data mining techniques to improve the current state of intrusion detection. Stolfo and Lee describe several approaches to data mining which are particularly useful in this domain, including classification, association and sequence analysis. Classification seems especially suitable is a training set is of audit data is available. An ideal application in intrusion detection will be to train a classifier by using sufficient "normal" and "abnormal" audit data, then apply the classifier to determine (future) audit data as belonging to the normal class or the abnormal class. In this research project you will apply classification methods for network intrusion detection. The datasets on which these techniques must be applied were extracted from data files used for The Third International Knowledge Discovery and Data Mining Tools Competition, which was held in conjunction with KDD-99 (The Fifth International Conference on Knowledge Discovery and Data Mining). The competition task was to build a network intrusion detector, a predictive model capable of distinguishing between "bad" connections, called intrusions or attacks, and "good" normal connections. The database used for the competition contains a standard set of data to be audited, which includes a wide variety of intrusions simulated in a military network environment. In this project you must replicate the experiment on a reduced sample data set (10000 records for the training data set, 1000 records for the test data set), using the classifiers you have learnt during this first part of the course (decision trees, tree augmented Nave Bayes, and knn) Data sets The following text, adapted from the 1999 paper Cost-based Modeling and Evaluation for Data Mining with Application to Fraud and Intrusion Detection: Results from the JAM Project by Salvatore J. Stolfo, Wei Fan, Wenke Lee, Andreas Prodromidis, and Philip K. Chan, was given to competitors to understand the task at hand and the data set with which they were confronted. Software to detect network intrusions protects a computer network from unauthorized users, including perhaps insiders. The intrusion detector learning task is to build a predictive model (i.e. a classifier) capable of distinguishing between "bad" connections, called intrusions or attacks, and "good" normal connections. The 1998 DARPA Intrusion Detection Evaluation Program was prepared and managed by MIT Lincoln Labs. The objective was to survey and evaluate research in intrusion detection. A stand rd set of data to be audited, which includes a wide variety of intrusions simulated in a military network environment, was provided. The 1999 KDD intrusion detection contest uses a version of this dataset. Lincoln Labs set up an environment to acquire nine weeks of raw TCP dump data for a local-area network (LAN) simulating a typical U.S. Air Force LAN. They operated the LAN as if it were a true Air Force environment, but peppered it with multiple attacks. The raw training data was about four gigabytes of compressed binary TCP dump data from seven weeks of network traffic. This was processed into about five million connection records. Similarly, the two weeks of test data yielded around two million connection records. A connection is a sequence of TCP packets starting and ending at some well defined times, between which data flows to and from a source IP address to a target IP address under some well defined protocol. Each connection is labeled as either normal, or as an attack, with exactly one specific attack type. Each connection record consists of about 100 bytes Attacks fall into four main categories: DOS: denial-of-service, e.g. syn flood; . R2L: unauthorized access from a remote machine, e.g. guessing password; U2R: unauthorized access to local superuser (root) privileges, e.g., various buffer overflow" attacks; probing: surveillance and other probing, e.g., port scanning. It is important to note that the test data is not from the same probability distribution as the training data, and it includes specific attack types not in the training data. This makes the task more realistic. Some intrusion experts believe that most novel attacks are variants of known attacks and the "signature" of known attacks can be sufficient to catch novel variants. The datasets contain a total of 24 training attack types, with an additional 14 types in the test data only. Table I displays the names of attacks and the category they belong to. Attack Name back buffer_overflow ftp_write guess_passwd imap ipsweep land loadmodule multihop neptune nmap Attack Type dos u2r r21 r21 r21 probe dos u2r 121 dos Attack Name perl phf pod portsweep rootkit satan smurf spy teardrop warezclient warezmaster Attack Type u2r r21 dos probe u2r probe dos r21 dos r21 r21 probe Table 1. Attack names and types Stolfo et al. defined higher-level features that help in distinguishing normal connections from attacks. There are several categories of derived features. The same host" features examine only the connections in the past two seconds that have the same destination host as the current connection, and calculate statistics related to protocol behavior, service, etc. The similar same service" features examine only the connections in the past two seconds that have the same service as the current connection. "Same host" and "same service" features are together called time-based traffic features of the connection records. Some probing attacks scan the hosts (or ports) using a much larger time interval than two seconds, for example once per minute. Therefore, connection records were also sorted by destination host, and features were constructed using a window of 100 connections to the same host instead of a time window. This yields a set of so-called host-based traffic features. Unlike most of the DOS and probing attacks, there appear to be no sequential patterns that are frequent in records of R2L and U2R attacks. This is because the DOS and probing attacks involve many connections to some host(s) in a very short period of time, but the R2L and U2R attacks are embedded in the data portions of packets, and normally involve only a single connection. Useful algorithms for mining the unstructured data portions of packets automatically are an open research question. Stolfo et al. used domain knowledge to add features that look for suspicious behavior in the data portions, such as the number of failed login attempts. These features are called "content" features. A complete listing of the set of features defined for the connection records is given Tables 2,3,4 below. The data schema of the contest dataset is summarized in Table 5. feature name duration protocol_type service src_bytes dst_bytes flag land wrong fragment urgent feature name hot num_failed_logins logged_in num_compromised root shell su_attempted num_root num_file_creations description length (number of seconds) of the connection type of the protocol, e.g. tcp, udp, etc. network service on the destination, e.g, http, telnet, etc. number of data bytes from source to destination number of data bytes from destination to source normal or error status of the connection 1 if connection is from/to the same host/port; 0 otherwise number of "wrong" fragments number of urgent packets Table 2. Basic features of individual TCP connections is_hot_login is_guest_login description number of "hot" indicators number of failed login attempts 1 if successfully logged in; 0 other number of "compromised" conditions 1 if root shell is obtained; 0 otherwise 1 if "su root" command attempted; 0 otherwise number of "root" accesses number of file creation operations number of shell prompts type continuous discrete discrete continuous continuous discrete discrete continuous continuous type continuous continuous disc continuous discrete discrete continuous continuous continuous num_shells num_access_files number of operations on access control files num_outbound_cmds number of outbound commands in an ftp session 1 if the login belongs to the "hot" list; 0 otherwise 1 if the login is a "guest"login; 0 otherwise Table 3. Content features within a connection suggested by domain knowledge continuous continuous discrete discrete feature name count serror_rate rerror_rate same_srv_rate diff_srv_rate srv_count description number of connections to the same host as the current connection in the past two seconds Note: The following features refer to these same-host connections. % of connections that have "SYN" errors % of connections that have "REJ" errors % of connections to the same service % of connections to different services number of connections to the same service as the current connection in the past two seconds Note: The following features refer to these same-service connections srv_serror_rate srv_rerror_rate srv_diff_host_rate 1. duration: continuous 2. protocol_type: categorical 3. service category: categorical % of connections that have "SYN" errors % of connections that have "REJ" errors. % of connections to different hosts Table 4. Traffic features computed using a two-second time window 4. flag:categorical 5. src_bytes: continuous 6. dst_bytes: continuous 7. land: categorical 8. wrong fragment: continuous 9. urgent: continuous 10.hot: continuous 11.num failed logins: continuous 12.logged in: categorical 13.num_compromised: continuous 14.root shell: continuous 15.su attempted: continuous 16.num_roat: continuous 17.num_file_creations: continuous 18.num_shells: continuous 19.num_access_files: continuous type 22is_guest_login: categorical 23.count: continuous 24.srv_count: continuous 25.serror_rate: continuous 26.srv_serror_rate: continuous 27.rerror_rate: continuous 28.srv_rerror_rate: continuous 29 same srv rate: continuous 30.diff_srv_rate: continuous 31srv_diff_host_rate: continuous 32.dst_host_count: continuous 33.dst_host_srv_count: continuous 34.dst host same srv_rate: continuous 35.dst_host_diff_srv_rate: continuous 36.dst host same src port rate: continuous 37.dst_host_srv_diff_host_rate: continuous 38.dst host serror_rate: continuous 39.dst_host_srv_serror_rate: continuous 40.dst_host_rerror_rate: continuous 41.dst_host_srv_rerror_rate: continuous 20.num_outbound_cmds.continuous 21.is host login: categorical 42.connection_type: categorical (class attribute) connection type: apache2., back., buffer_overflow., guess_passwd., httptunnel, ipsweep., mailbomb., mscan., multihop., neptune, nmap., normal, pod., portsweep., processtable., rootkit, saint, satan., smurf., snmpgetattack, sampguess, sqlattack., warezmaster., xlock. Note: normal. means a "normal" connection (no attack) Table 5. Data File Format continuous Project Tasks 1. Download corrected.gz file from the KDD 1999 cup website: http://kdd.ics.uci.edu/databases/kddcup99/kddcup99.html continuous continuous continuous continuous continuous continuous continuous continuous (This was the test data used in the competition. You will use it in this project to extract both the training dataset and the test data set) 2. From the corrected.gz file extract 11000 records, 10000 for the training dataset, and 1000 for the test dataset. Make sure to do random sampling on the corrected.gz file to avoid biasing the extracted dataset 3. The target variable is connection type, recoded as normal, dos, u2r, r21, probe. The first value represents a normal connection, the rest are different attack types. This means that you will have to recode the records to meet these connections type values. 4. Perform exploratory data analysis on the datasets, in order to get a feeling on the underlying characteristics of the attributes in the files. Report your findings 5. Build classifiers for the classes depicted above using the algorithms you know and you deem useful. Please note that some of them may take long(er) to complete given the size of the training dataset. Report on execution time (if significant) and on the predictive performance of the classifiers. 6. Recode the variable as binary (normal, attack) to model a binary classification problem and run classifiers on it. 7. Decision tree algorithms such as C5.0 are not only robust classifiers but also good profiling tools (i.e. can be used to characterize the predictors based on the rules derived from the tree). Use the C5.0 tree to describe the features that characterize each of the 4 types of attacks considered in this study (note: you may need to prune the tree to come up with satisfactory rules) 8. Labeling the data can be costly, as it requires a domain expert to sift through the records and label each of them according to whether it is a normal connection or a certain type of attack. The alternative to this is to apply an unsupervised approach, and cluster the unlabeled data records according to its common characteristics. How feasible and accurate is this approach? Try it and report results. You must present your results in the format of a professionally written report. Don't just answer numbered questions, used them as the outline of the report you need to prepare. Think of yourselves as data scientists reporting results on an experiment.
Step by Step Solution
3.33 Rating (165 Votes )
There are 3 Steps involved in it
Project 3 Data Mining for Intrusion Detection Report 1 Introduction In recent times the application of data mining in computer network intrusion detec... View full answer

Get step-by-step solutions from verified subject matter experts