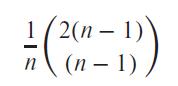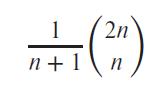New Semester
Started
Get
50% OFF
Study Help!
--h --m --s
Claim Now
Question Answers
Textbooks
Find textbooks, questions and answers
Oops, something went wrong!
Change your search query and then try again
S
Books
FREE
Study Help
Expert Questions
Accounting
General Management
Mathematics
Finance
Organizational Behaviour
Law
Physics
Operating System
Management Leadership
Sociology
Programming
Marketing
Database
Computer Network
Economics
Textbooks Solutions
Accounting
Managerial Accounting
Management Leadership
Cost Accounting
Statistics
Business Law
Corporate Finance
Finance
Economics
Auditing
Tutors
Online Tutors
Find a Tutor
Hire a Tutor
Become a Tutor
AI Tutor
AI Study Planner
NEW
Sell Books
Search
Search
Sign In
Register
study help
computer science
database system concepts
Database System Concepts 7th Edition Abraham Silberschatz, Henry F. Korth, S. Sudarshan - Solutions
What trade-offs do write-optimized indices pose as compared to B+-tree indices?
An existence bitmap has a bit for each record position, with the bit set to 1 if the record exists, and 0 if there is no record at that position (for example, if the record were deleted). Show how to compute the existing bitmap from other bitmaps. Make sure that your technique works even in the
Spatial indices that can index spatial intervals can conceptually be used to index temporal data by treating valid time as a time interval. What is the problem with doing so, and how is the problem solved?
Design sort-based and hash-based algorithms for computing the relational division operation. branch(branch_name, branch_city, assets) customer (customer_name, customer_street, customer_city) loan (loan_number, branch name, amount) borrower (customer_name, loan_number) account (account_number,
Let r and s be relations with no indices, and assume that the relations are not sorted. Assuming infinite memory, what is the lowest-cost way (in terms of I/O operations) to compute r ⋈ s? What is the amount of memory required for this algorithm?
What is the effect What is the effect on the cost of merging runs if the number of buffer blocks per run is increased while overall memory available for buffering runs remains fixed? Act on the cost of merging runs if the number of buffer blocks per run is increased while overall memory available
Suppose a query retrieves only the first K results of an operation and terminates after that. Which choice of demand-driven or producer-driven pipelining (with buffering) would be a good choice for such a query? Explain your answer.
Current generation CPUs include an instruction cache, which caches recently used instructions. A function call then has a significant overhead because the set of instructions being executed changes, resulting in cache misses on the instruction cache.a. Explain why producer-driven pipelining with
Suggest how a document containing a word (such as “leopard”) can be indexed such that it is efficiently retrieved by queries using a more general concept (such as “carnivore” or “mammal”). You can assume that the concept hierarchy is not very deep, so each concept has only a few
Explain why the nested-loops join algorithm would work poorly on a database stored in a column-oriented manner. Describe an alternative algorithm that would work better, and explain why your solution is better.
Consider the following queries. For each query, indicate if column-oriented storage is likely to be beneficial or not, and explain why.a. Fetch ID, name and dept name of the student with ID 12345.b. Group the takes relation by year and course id, and find the total number of students for each
Suppose you need to sort a relation of 40 gigabytes, with 4-kilobyte blocks, using a memory size of 40 megabytes. Suppose the cost of a seek is 5 milliseconds, while the disk transfer rate is 40 megabytes per second.a. Find the cost of sorting the relation, in seconds, with bb = 1 and with bb =
Suppose you have to compute Aγsum(C)(r) as well as A,Bγsum(C)(r). Describe how to compute these together using a single sorting of r.
Write pseudocode for an iterator that implements a version of the sort–merge algorithm where the result of the final merge is pipelined to its consumers. Your pseudocode must define the standard iterator functions open(), next(), and close(). Show what state information the iterator must maintain
Explain how to split the hybrid hash-join operator into sub-operators to model pipelining. Also explain how this split is different from the split for a hash-join operator.
Suppose you need to sort relation r using sort—merge and merge—join the result with an already sorted relation s.a. Describe how the sort operator is broken into sub operators to model the pipelining in this case.b. The same idea is applicable even if both inputs to the merge join are the
Consider the relations r1(A, B, C), r2(C, D, E), and r3(E, F), with primary keys A, C, and E, respectively. Assume that r1 has 1000 tuples, r2 has 1500 tuples, and r3 has 750 tuples. Estimate the size of r1 ⋈ r2 ⋈ r3, and give an efficient strategy for computing the join.
Give conditions under which the following expressions are equivalent:where agg denotes any aggregation operation. How can the above conditions be relaxed if agg is one of min or max? A,BY agg(C) (E₁ E₂) and (Yagg(c)(E₁)) □ E₂
Suppose you need to sort relation r using sort-merge and merge—join the result with an already sorted relation s.a. Describe how the sort operator is broken into sub operators to model the pipelining in this case.b. The same idea is applicable even if both inputs to the merge join are the outputs
Write pseudocode for an iterator that implements indexed nested-loop join, where the outer relation is pipelined. Your pseudocode must define the standard iterator functions open(), next(), and close(). Show what state information the iterator must maintain between calls.
Show that, with n relations, there are (2(n−1))!∕(n−1)! different join orders. A complete binary tree is one where every internal node has exactly two children. Use the fact that the number of different complete binary trees with n leaf nodes is:If you wish, you can derive the formula for the
Consider the query:select *from r, swhere upper(r.A) = upper(s.A)where “upper” is a function that returns its input argument with all lowercase letters replaced by the corresponding uppercase letters.a. Find out what plan is generated for this query on the database system you use.b. Some
Consider the issue of interesting orders in optimization. Suppose you are given a query that computes the natural join of a set of relations S. Given a subset S1 of S, what are the interesting orders of S1?
Suppose that a B+-tree index on (dept_name, building) is available on relation department. What would be the best way to handle the following selection? (building < "Watson") ^ (budget < 55000) ^ (dept_name "Music") (department) = branch(branch_name, branch_city, assets) customer (customer_name,
Modify the Find Best Plan(S) function to create a function Find Best Plan(S, O), where O is the desired sort order for S, and which considers interesting sort orders. A null order indicates that the order is not relevant. An algorithm A may give the desired order O; if not a sort operation may need
Consider the bank database of Figure 16.9, where the primary keys are underlined. Construct the following SQL queries for this relational database.a. Write a nested query on the relation account to find, for each branch with name starting with B, all accounts with the maximum balance at the
The lost update anomaly is said to occur if a transaction Tj reads a data item, then another transaction Tk writes the data item (possibly based on a previous read), after which Tj writes the data item. The update performed by Tk has been lost, since the update done by Tj ignored the value written
Describe how to incrementally maintain the results of the following operations on both insertions and deletions:a. Union and set difference.b. Left outer join.
Suppose you need to sort relation r using sort-merge and merge—join the result with an already sorted relation s.a. Describe how the sort operator is broken into sub operators to model the pipelining in this case.b. The same idea is applicable even if both inputs to the merge join are the outputs
What class or classes of storage can be used to ensure durability? Why?
Consider a database for a bank where the database system uses snapshot isolation. Describe a particular scenario in which a non serializable execution occurs that would present a problem for the bank.
Consider a database for an airline where the database system uses snapshot isolation. Describe a particular scenario in which a non serializable execution occurs, but the airline may be willing to accept it in order to gain better overall performance.
The definition of a schedule assumes that operations can be totally ordered by time. Consider a database system that runs on a system with multiple processors, where it is not always possible to establish an exact ordering between operations that executed on different processors. However,
Give an example of a serializable schedule with two transactions such that the order in which the transactions commit is different from the serialization order.
Why do database systems support concurrent execution of transactions, despite the extra effort needed to ensure that concurrent execution does not cause any problems?
Explain why the read-committed isolation level ensures that schedules are cascade-free.
For each of the following isolation levels, give an example of a schedule that respects the specified level of isolation but is not serializable:a. Read uncommittedb. Read committedc. Repeatable read
Explain why the following technique for transaction execution may provide better performance than just using strict two-phase locking: First execute the transaction without acquiring any locks and without performing any writes to the database as in the validation-based techniques, but unlike the
Consider the timestamp-ordering protocol, and two transactions, one that writes two data items p and q, and another that reads the same two data items. Give a schedule whereby the timestamp test for a write operation fails and causes the first transaction to be restarted, in turn causing a
The snapshot isolation protocol uses a validation step which, before performing a write of a data item by transaction T, checks if a transaction concurrent with T has already written the data item. a. A straightforward implementation uses a start timestamp and a commit timestamp for each
The multiple-granularity protocol rules specify that a transaction Ti can lock a node Q in S or IS mode only if Ti currently has the parent of Q locked in either IX or IS mode. Given that SIX and S locks are stronger than IX or IS locks, why does the protocol not allow locking a node in S or IS
Suppose the lock hierarchy for a database consists of database, relations, and tuples.a. If a transaction needs to read a lot of tuples from a relation r, what locks should it acquire?b. Now suppose the transaction wants to update a few of the tuples in r after reading a lot of tuples. What locks
As discussed in Exercise 18.15, snapshot isolation can be implemented using a form of timestamp validation. However, unlike the multi-version timestamp ordering scheme, which guarantees serializability, snapshot isolation does not guarantee serializability. Explain the key difference between
Outline the key similarities and differences between the timestamp-based implementation of the first-committer-wins version of snapshot isolation, described in Exercise 18.15, and the optimistic-concurrency control-without-read validation scheme, describe.Exercise 18.15The snapshot isolation
Consider a relation r(A, B, C) and a transaction T that does the following: find the maximum A value in r, and insert a new tuple in r whose A value is 1+ the maximum A value. Assume that an index is used to find the maximum A value.a. Suppose that the transaction locks each tuple it reads in S
Explain the reason for the use of degree-two consistency. What disadvantages does this approach have?
Give example schedules to show that with key-value locking, if lookup, insert, or delete does not lock the next-key value, the phantom phenomenon could go undetected.
Many transactions update a common item (e.g., the cash balance at a branch) and private items (e.g., individual account balances). Explain how you can increase concurrency (and throughput) by ordering the operations of the transaction.
Consider the following locking protocol: All items are numbered, and once an item is unlocked, only higher-numbered items may be locked. Locks may be released at any time. Only X-locks are used. Show by an example that this protocol does not guarantee serializability.
The Oracle database system uses undo log records to provide a snapshot view of the database under snapshot isolation. The snapshot view seen by transaction Ti reflects updates of all transactions that had committed when Ti started and the updates of Ti; updates of all other transactions are not
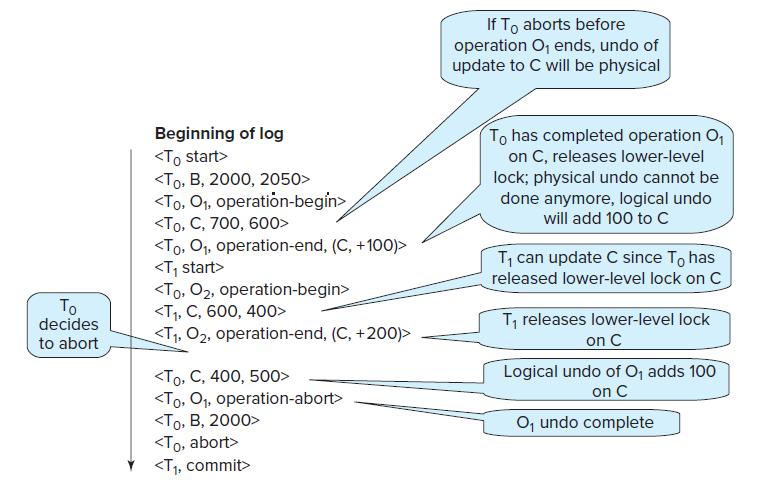
Consider the log in Figure 19.7. Suppose there is a crash during recovery, just before the operation abort log record is written for operation O1. Explain what will happen when the system recovers again.Figure 19.7 To decides to abort Beginning of log If To aborts before operation
Outline the drawbacks of the no-steal and force buffer management policies.
Suppose two-phase locking is used, but exclusive locks are released early, that is, locking is not done in a strict two-phase manner. Give an example to show why transaction rollback can result in a wrong final state, when using the log based recovery algorithm.
Physiological redo logging can reduce logging overheads significantly, especially with a slotted page record organization. Explain why.
Consider a pair of processes in a shared memory system such that process A updates a data structure, and then sets a flag to indicate that the update is completed. Process B monitors the flag, and starts processing the data structure only after it finds the flag is set.Explain the problems that
Assume that a growing enterprise has outgrown its current computer system and is purchasing a new parallel computer. If the growth has resulted in many more transactions per unit time, but the length of individual transactions has not changed, what measure is most relevant—speedup, batch scaleup,
Suppose you have a large relation r(A, B, C) and a materialized view v = AУsum(B)(r). View maintenance can be performed as part of each transaction that updates r, on a parallel/distributed storage system that supports transactions across multiple nodes. Suppose the system uses two-phase commit
What characteristics of an application make it easy to scale the application by using a key-value store, and what characteristics rule out deployment on key-value stores?
Give a search algorithm on an R-tree for efficiently finding the nearest neighbor to a given query point.
What is a blockchain fork? List the two types of fork and explain their differences.
Explain why log records for transactions on the undo-list must be processed in reverse order, whereas redo is performed in a forward direction.
Suppose the deferred modification technique is used in a database.a. Is the old value part of an update log record required any more? Why or why not? b. If old values are not stored in update log records, transaction undo is clearly not feasible. How would the redo phase of recovery have to be
The shadow-paging scheme requires the page table to be copied. Suppose the page table is represented as a B+-tree.a. Suggest how to share as many nodes as possible between the new copy and the shadow copy of the B+-tree, assuming that updates are made only to leaf entries, with no insertions or
Suppose a transaction deletes a record, and the free space generated thus is allocated to a record inserted by another transaction, even before the first transaction commits. Disk space allocated to a file as a result of a transaction should not be released even if the transaction is
Suppose a transaction deletes a record, and the free space generated thus is allocated to a record inserted by another transaction, even before the first transaction commits.a. What problem can occur if the first transaction needs to be rolled back?b. Would this problem be an issue if page-level
The recovery techniques that we described assume that blocks are written atomically to disk. However, a block may be partially written when power fails, with some sectors written, and others not yet written.a. What problems can partial block writes cause?b. Partial block writes can be detected
Is a multiuser system necessarily a parallel system? Why or why not?
Atomic instructions such as compare-and-swap and test-and-set also execute a memory fence as part of the instruction on many architectures. Explain what is the motivation for executing the memory fence, from the viewpoint of data in shared memory that is protected by a mutex implemented by the
Explain the distinction between a latch and a lock as used for transactional concurrency control.
In a shared-memory architecture, why might the time to access a memory location vary depending on the memory location being accessed?
Most operating systems for parallel machines (i) allocate memory in a local memory area when a process requests memory, and (ii) avoid moving a process from one core to another. Why are these optimizations important with a NUMA architecture?
Some database operations such as joins can see a significant difference in speed when data (e.g., one of the relations involved in a join) fits in memory as compared to the situation where the data do not fit in memory. Show how this fact can explain the phenomenon of super linear speedup, where an
Why might a client choose to subscribe only to the basic infrastructure-as-aservice model rather than to the services offered by other cloud service models?
Why do cloud-computing services support traditional database systems best by using a virtual machine, instead of running directly on the service provider’s actual machine, assuming that data is on external storage?
Is it wise to allow a user process to access the shared-memory area of a database system? Explain your answer.
Assume we have data items d1, d2,…, dn with each di protected by a lock stored in memory location Mi.a. Describe the implementation of lock-X(di) and unlock(di) via the use of the test-and-set instruction.b. Describe the implementation of lock-X(di) and unlock(di) via the use of the
Memory systems today are divided into multiple modules, each of which can be serving a separate request at a given time, in contrast to earlier architectures where there was a single interface to memory. What impact has such a memory architecture have on the number of processors that can be
In a shared-nothing system data access from a remote node can be done by remote procedure calls, or by sending messages. But remote direct memory access (RDMA) provides a much faster mechanism for such data access. Explain why.
Suppose that a major database vendor offers its database system (e.g., Oracle, SQL Server DB2) as a cloud service. Where would this fit among the cloudservice models? Why?
If an enterprise uses its own ERP application on a cloud service under the platform-as-a-service model, what restrictions would there be on when that enterprise may upgrade the ERP system to a new version?
Histograms are traditionally constructed on the values of a specific attribute (or set of attributes) of a relation. Such histograms are good for avoiding data distribution skew but are not very useful for avoiding execution skew. Explain why.Now suppose you have a workload of queries that perform
Replication:a. Give two reasons for replicating data across geographically distributed data centers.b. Centralized databases support replication using log records. How is the replication in centralized databases different from that in parallel/distributed databases?
Parallel indices: a. Secondary indices in a centralized database store the record identifier. A global secondary index too could potentially store a partition number holding the record, and a record identifier within the partition. Why would this be a bad idea?b. Global secondary indices are
Partitioning and replication.a. Explain why range-partitioning gives better control on tablet sizes than hash partitioning. List an analogy between this case and the case of B+-tree indices versus hash indices.b. Some systems first perform hashing on the key, and then use range partitioning on the
What is the motivation for storing related records together in a key-value store? Explain the idea using the notion of an entity group.
Why is it easier for a distributed file system such as GFS or HDFS to support replication than it is for a key-value store?
Joins can be expensive in a key-value store, and difficult to express if the system does not support SQL or a similar declarative query language. What can an application developer do to efficiently get results of join or aggregate queries in such a setting?
Suppose relation r is stored partitioned and indexed on A, and s is stored partitioned and indexed on B. Consider the query:a. Give a parallel query plan using the exchange operator, for computing the subtree of the query involving only the select and join operators.b. Now extend the above to
Describe how partial aggregation can be implemented for the count and avg aggregate functions to reduce data transfer.
Suppose relation r is stored partitioned and indexed on A, and s is stored partitioned and indexed on B. Consider the join r ⋈r.B=s.B s. Suppose s is relatively small, but not small enough to make asymmetric fragment-and-replicate join the best choice, and r is large, with most r tuples not
Suppose you want to compute r⟕r.A=s.A s.a. Suppose s is a small relation, while r is stored partitioned on r.B. Give an efficient parallel algorithm for computing the left outer join.b. Now suppose that r is a small relation, and s is a large relation, stored partitioned on attribute s.B. Give an
Suppose you want to compute A,Bγsum(C) on a relation s which is stored partitioned on s.B. Explain how you would do it efficiently, minimizing/avoiding repartitioning, if the number of distinct s.B values is large, and the distribution of number of tuples with each s.B value is relatively uniform.
MapReduce implementations provide fault tolerance, where you can re execute only failed mappers or reducers. By default, a partitioned parallel join execution would have to be rerun completely in case of even one node failure. It is possible to modify a parallel partitioned join execution to add
If a parallel data-store is used to store two relations r and s and we need to join r and s, it may be useful to maintain the join as a materialized view. What are the benefits and overheads in terms of overall throughput, use of space, and response time to user queries?
Explain how each of the following join algorithms can be implemented using the MapReduce framework:a. Broadcast join (also known as asymmetric fragment-and-replicate join).b. Indexed nested loop join, where the inner relation is stored in a parallel data-store.c. Partitioned join.
Can partitioned join be used for r ⋈r.A s? Explain your answer
What is the motivation for work-stealing with virtual nodes in a shared-memory setting? Why might work-stealing not be as efficient in a shared-nothing setting?
The attribute on which a relation is partitioned can have a significant impact on the cost of a query.a. Given a workload of SQL queries on a single relation, what attributes would be candidates for partitioning?b. How would you choose between the alternative partitioning techniques, based on the
Consider system that is processing a stream of tuples for a relation r with attributes (A, B, C, timestamp) Suppose the goal of a parallel stream processing system is to compute the number of tuples for each A value in each 5 minute window (based on the timestamp of the tuple). What would be the
If the primary copy scheme is used for replication, and the primary gets disconnected from the rest of the system, a new node may get elected as primary. But the old primary may not realize it has got disconnected, and may get reconnected subsequently without realizing that there is a new
Showing 100 - 200
of 303
1
2
3
4
Step by Step Answers