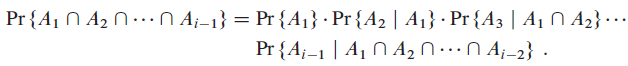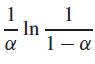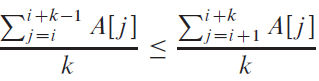New Semester
Started
Get
50% OFF
Study Help!
--h --m --s
Claim Now
Question Answers
Textbooks
Find textbooks, questions and answers
Oops, something went wrong!
Change your search query and then try again
S
Books
FREE
Study Help
Expert Questions
Accounting
General Management
Mathematics
Finance
Organizational Behaviour
Law
Physics
Operating System
Management Leadership
Sociology
Programming
Marketing
Database
Computer Network
Economics
Textbooks Solutions
Accounting
Managerial Accounting
Management Leadership
Cost Accounting
Statistics
Business Law
Corporate Finance
Finance
Economics
Auditing
Tutors
Online Tutors
Find a Tutor
Hire a Tutor
Become a Tutor
AI Tutor
AI Study Planner
NEW
Sell Books
Search
Search
Sign In
Register
study help
computer science
introduction to algorithms
Introduction to Algorithms 3rd edition Thomas H. Cormen, Charles E. Leiserson, Ronald L. Rivest - Solutions
We wish to augment red-black trees with an operation RB-ENUMERATE (x, a, b) that outputs all the keys k such that a ≤ k ≤ b in a red-black tree rooted at x. Describe how to implement RB-ENUMERATE in Θ(m + lg n) time, where m is the number of keys that are output and n is the number of internal
Write a recursive procedure OS-KEY-RANK(T, k) that takes as input an order statistic tree T and a key k and returns the rank of k in the dynamic set represented by T. Assume that the keys of T are distinct.
Let ⊗ be an associative binary operator, and let a be an attribute maintained in each node of a red-black tree. Suppose that we want to include in each node x an additional attribute f such
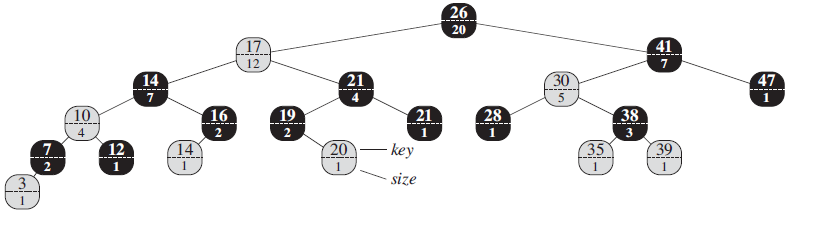
Show how OS-RANK (T, x) operates on the red-black tree T of Figure 14.1 and the node x with x.key = 35. Figure 14.1 26 20 17 41 E--- 12 7 14 21 30 47 -------- -------- E---- ----- --- 4 1 16 2 (14 (10 19 21 28 38 4 2 1 12 20 – key 35 39 ---- T------ 2 1 1 1 1 3 size
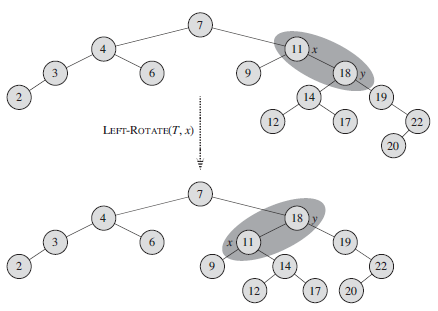
Write pseudocode for LEFT-ROTATE that operates on nodes in an interval tree and updates the max attributes in O(1) time.
Show, by adding pointers to the nodes, how to support each of the dynamic-set queries MINIMUM, MAXIMUM, SUCCESSOR, and PREDECESSOR in O(1) worst case time on an augmented order-statistic tree. The asymptotic performance of other operations on order-statistic trees should not be affected.
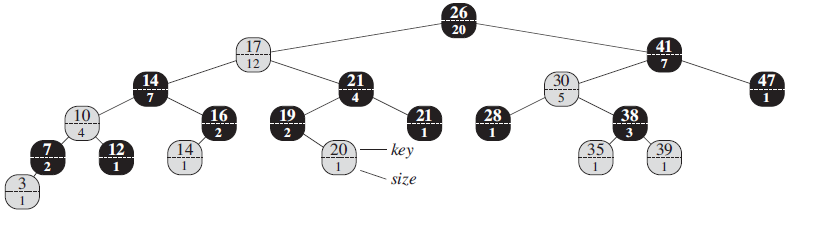
Show how OS-SELECT (T.root, 10) operates on the red-black tree T of Figure 14.1. Figure 14.1 26 20 17 41 E--- 12 7 14 21 30 47 -------- -------- E---- ----- --- 4 1 16 2 (14 (10 19 21 28 38 4 2 1 12 20 – key 35 39 ---- T------ 2 1 1 1 1 3 size
Describe a red-black tree on n keys that realizes the largest possible ratio of red internal nodes to black internal nodes. What is this ratio? What tree has the smallest possible ratio, and what is the ratio?
What is the largest possible number of internal nodes in a red-black tree with black height k? What is the smallest possible number?
We say that a binary search tree T1 can be right-converted to binary search tree T2 if it is possible to obtain T2 from T1 via a series of calls to RIGHT-ROTATE. Give an example of two trees T1 and T2 such that T1 cannot be right-converted
In each of the cases of Figure 13.7, give the count of black nodes from the root of the subtree shown to each of the subtrees ?, ?, . . . , ?, and verify that each count remains the same after the transformation. When a node has a color attribute c or c?, use the notation count (c) or count (c?)
Consider a red-black tree formed by inserting n nodes with RB-INSERT. Argue that if n > 1, the tree has at least one red node.
In which lines of the code for RB-DELETE-FIXUP might we examine or modify the sentinel T.nil?
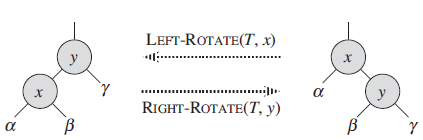
Let?a,?b, and?c?be arbitrary nodes in subtrees??,??, and ?, respectively, in the left tree of Figure 13.2. How do the depths of?a,?b, and?c?change when a left rotation is performed on node?x?in the figure? Figure 13.2 LEFT-ROTATE(T, x) ...... ...... RIGHT-ROTATE(T, y) B B
In Exercise 13.3-2, you found the red-black tree that results from successively inserting the keys 41, 38, 31, 12, 19, 8 into an initially empty tree. Now show the red-black trees that result from the successive deletion of the keys in the order 8, 12, 19, 31, 38, 41.Exercise 13.3-2Show the
Argue that in every n-node binary search tree, there are exactly n - 1 possible rotations. Figure 13.3 An example of how the procedure LEFT-ROTATE (T, x) modifies a binary search tree. In order tree walks of the input tree and the modified tree produce the same listing of key values. 7 11x 3 6 18
The join operation takes two dynamic sets S1 and S2 and an element x such that for any x1 ∈ S1 and x2 ∈ S2, we have x1.key ≤ x.key ≤ x2.key. It returns a set S = S1 ⋃ {x} ⋃ S2. In this problem, we investigate how to implement the join
Argue that if in RB-DELETE both x and x.p are red, then property 4 is restored by the call to RB-DELETE-FIXUP (T, x).
Show the red-black trees that result after successively inserting the keys 41, 38, 31, 12, 19, 8 into an initially empty red-black tree.
In the style of Figure 13.1(a), draw the complete binary search tree of height 3 on the keys {1, 2, . . . , 15}. Add the NIL leaves and color the nodes in three different ways such that the black-heights of the resulting red-black trees are 2, 3, and 4.
Argue that after executing RB-DELETE-FIXUP, the root of the tree must be black.
In line 16 of RB-INSERT, we set the color of the newly inserted node z to red. Observe that if we had chosen to set z’s color to black, then property 4 of a red black tree would not be violated. Why didn’t we choose to set z’s color to black?
Let T be a binary search tree whose keys are distinct, let x be a leaf node, and let y be its parent. Show that y.key is either the smallest key in T larger than x.key or the largest key in T smaller than x.key.
Prove that no matter what node we start at in a height-h binary search tree, k successive calls to TREE-SUCCESSOR take O(k + h) time.
When node z in TREE-DELETE has two children, we could choose node y as its predecessor rather than its successor. What other changes to TREE-DELETE would be necessary if we did so? Some have argued that a fair strategy, giving equal priority to predecessor and successor, yields better empirical
Consider a binary search tree T whose keys are distinct. Show that if the right sub tree of a node x in T is empty and x has a successor y, then y is the lowest ancestor of x whose left child is also an ancestor of x. (Recall that every node is its own ancestor.)
Consider RANDOMIZED-QUICKSORT operating on a sequence of n distinct input numbers. Prove that for any constant k > 0, all but O(1/nk) of the n! input permutations yield an O(n lg n) running time.
Suppose that instead of each node x keeping the attribute x.p, pointing to x's parent, it keeps x.succ, pointing to x's successor. Give pseudocode for SEARCH, INSERT, and DELETE on a binary search tree T using this representation. These procedures should operate in time O(h), where h is the height
Argue that since sorting n elements takes Ω(n lg n) time in the worst case in the comparison model, any comparison-based algorithm for constructing a binary search tree from an arbitrary list of n elements takes Ω(n lg n) time in the worst case.
Is the operation of deletion "commutative" in the sense that deleting x and then y from a binary search tree leaves the same tree as deleting y and then x? Argue why it is or give a counterexample.
Give recursive algorithms that perform preorder and post-order tree walks in Θ(n) time on a tree of n nodes.
Show that the notion of a randomly chosen binary search tree on n keys, where each binary search tree of n keys is equally likely to be chosen, is different from the notion of a randomly built binary search tree given in this section. List the possibilities when n = 3.
Give a non recursive algorithm that performs an in order tree walk. An easy solution uses a stack as an auxiliary data structure. A more complicated, but elegant, solution uses no stack but assumes that we can test two pointers for equality.)
Suppose that we construct a binary search tree by repeatedly inserting distinct values into the tree. Argue that the number of nodes examined in searching for a value in the tree is one plus the number of nodes examined when the value was first inserted into the tree.
Equal keys pose a problem for the implementation of binary search trees.a. What is the asymptotic performance of TREE-INSERT when used to insert n items with identical keys into an initially empty binary search tree?We propose to improve TREE-INSERT by testing before line 5 to
For the set of {1, 4, 5, 10, 16, 17, 21} of keys, draw binary search trees of heights 2, 3, 4, 5, and 6.
Consider an open-address hash table with a load factor ?. Find the nonzero value ? for which the expected number of probes in an unsuccessful search equals twice the expected number of probes in a successful search. Use the upper bounds given by Theorems 11.6 and 11.8 for these expected numbers of
Suppose that we are storing a set of n keys into a hash table of size m. Show that if the keys are drawn from a universe U with|U| > nm, then U has a subset of size n consisting of keys that all hash to the same slot, so that the worst-case searching time for hashing with chaining is Θ(n).
Suppose that we use double hashing to resolve collisions—that is, we use the hash function h(k, i) = (h1(k) + ih2(k)) mod m. Show that if m and h2(k) have greatest common divisor d ≥ 1 for some key k, then an
Consider a hash table of size m = 1000 and a corresponding hash function h(k) = ⌊m(kA mod 1)⌋ for A = (√5 – 1)/2. Compute the locations to which the keys 61, 62, 63, 64, and 65 are mapped.
Let H be a class of hash functions in which each hash function h ε H maps the universe U of keys to {0, 1, . . . , m — 1}. We say that H is k-universal if, for every fixed sequence of k distinct keys 〈x(1), x(2), . . . , x(k)〉 and for any h chosen at random from H, the sequence 〈h(x(1)),
Suggest how to implement a direct-address table in which the keys of stored elements do not need to be distinct and the elements can have satellite data. All three dictionary operations (INSERT, DELETE, and SEARCH) should run in O(1) time. (Don't forget that DELETE takes as an argument a pointer to
Consider an open-address hash table with uniform hashing. Give upper bounds on the expected number of probes in an unsuccessful search and on the expected number of probes in a successful search when the load factor is 3/4 and when it is 7/8.
Professor Marley hypothesizes that he can obtain substantial performance gains by modifying the chaining scheme to keep each list in sorted order. How does the professor’s modification affect the running time for successful searches, unsuccessful searches, insertions, and deletions?
A bit vector is simply an array of bits (0s and 1s). A bit vector of length m takes much less space than an array of m pointers. Describe how to use a bit vector to represent a dynamic set of distinct elements with no satellite data. Dictionary operations should run in O(1) time.
Write pseudocode for HASH-DELETE as outlined in the text, and modify HASHINSERT to handle the special value DELETED.
Suppose that we hash a string of r characters into m slots by treating it as a radix-128 number and then using the division method. We can easily represent the number m as a 32-bit computer word, but the string of r characters, treated as a radix-128 number, takes many words. How can we apply the
Demonstrate what happens when we insert the keys 5, 28, 19, 15, 20, 33, 12, 17, 10 into a hash table with collisions resolved by chaining. Let the table have 9 slots, and let the hash function be h(k) = k mod 9.
Suppose that a dynamic set S is represented by a direct-address table T of length m. Describe a procedure that finds the maximum element of S. What is the worst-case performance of your procedure?
Consider inserting the keys 10, 22, 31, 4, 15, 28, 17, 88, 59 into a hash table of length m = 11 using open addressing with the auxiliary hash function h′(k) = k. Illustrate the result of inserting these keys using linear probing, using quadratic
Suppose we wish to search a linked list of length n, where each element contains a key k along with a hash value h(k). Each key is a long character string. How might we take advantage of the hash values when searching the list for an element with a given key?
Explain how to implement doubly linked lists using only one pointer value x.np per item instead of the usual two (next and prev). Assume that all pointer values can be interpreted as k-bit integers, and define x.np to be x.np = x.next XOR x.preν, the k-bit "exclusive-or" of x.next and x.prev. (The
Give a Θ(n)-time non recursive procedure that reverses a singly linked list of n elements. The procedure should use no more than constant storage beyond that needed for the list itself.
Show how to implement a stack using two queues. Analyze the running time of the stack operations.
The left-child, right-sibling representation of an arbitrary rooted tree uses three pointers in each node: left-child, right-sibling, and parent. From any node, its parent can be reached and identified in constant time and all its children can be reached and identified in time linear in the number
The dynamic-set operation UNION takes two disjoint sets S1 and S2 as input, and it returns a set S = S1 ⋃ S2 consisting of all the elements of S1 and S2. The sets S1 and S2 are usually destroyed by the operation. Show how to support
Show how to implement a queue using two stacks. Analyze the running time of the queue operations.
Write an O(n)-time non recursive procedure that, given an n-node binary tree, prints out the key of each node. Use no more than constant extra space outside of the tree itself and do not modify the tree, even temporarily, during the procedure.
Let L be a doubly linked list of length n stored in arrays key, prev, and next of length m. Suppose that these arrays are managed by ALLOCATE-OBJECT and FREE-OBJECT procedures that keep a doubly linked free list F. Suppose further that of the m items, exactly n are on list L and m - n are on the
Implement the dictionary operations INSERT, DELETE, and SEARCH using singly linked, circular lists. What are the running times of your procedures?
Whereas a stack allows insertion and deletion of elements at only one end, and a queue allows insertion at one end and deletion at the other end, a deque (doubleended queue) allows insertion and deletion at both ends. Write four O(1)-time procedures to insert elements into and delete elements from
Write an O(n)-time procedure that prints all the keys of an arbitrary rooted tree with n nodes, where the tree is stored using the left-child, right-sibling representation.
It is often desirable to keep all elements of a doubly linked list compact in storage, using, for example, the first m index locations in the multiple-array representation. (This is the case in a paged, virtual-memory computing environment.) Explain how to implement the procedures ALLOCATE-OBJECT
As written, each loop iteration in the LIST-SEARCH′ procedure requires two tests: one for x ≠ L.nil and one for x.key ≠ k. Show how to eliminate the test for x ≠ L.nil in each iteration.
Write an O(n)-time non recursive procedure that, given an n-node binary tree, prints out the key of each node in the tree. Use a stack as an auxiliary data structure.
Why don't we need to set or reset the prev attributes of objects in the implementation of the ALLOCATE-OBJECT and FREE-OBJECT procedures?
Implement a queue by a singly linked list L. The operations ENQUEUE and DEQUEUE should still take O(1) time.
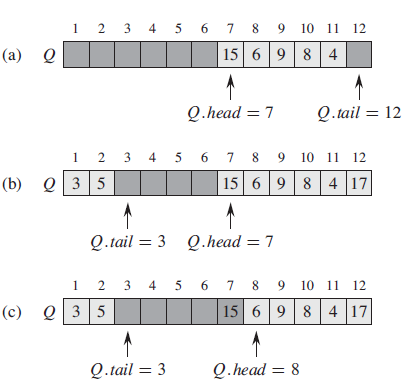
Using Figure 10.2 as a model, illustrate the result of each operation in the sequence ENQUEUE?(Q, 4), ENQUEUE?(Q, 1), ENQUEUE?(Q, 3), DEQUEUE?(Q), ENQUEUE?(Q, 8), and DEQUEUE?(Q)?on an initially empty queue?Q?stored in array?Q[1. . 6]. Figure 10.2 1 2 3 4 5 6 7 8 9 10 11 12 15 6 9 8 4 (а) Q
A mergeable heap supports the following operations: MAKE-HEAP (which creates an empty mergeable heap), INSERT, MINIMUM, EXTRACT-MIN, and UNION.1 Show how to implement mergeable heaps using linked lists in each of the following cases. Try to make each operation as efficient as possible. Analyze the
Write an O(n)-time recursive procedure that, given an n-node binary tree, prints out the key of each node in the tree.
Write the procedures ALLOCATE-OBJECT and FREE-OBJECT for a homogeneous collection of objects implemented by the single-array representation.
Implement a stack using a singly linked list L. The operations PUSH and POP should still take O(1) time.
Explain how to implement two stacks in one array A[1 . . n] in such a way that neither stack overflows unless the total number of elements in both stacks together is n. The PUSH and POP operations should run in O(1) time.
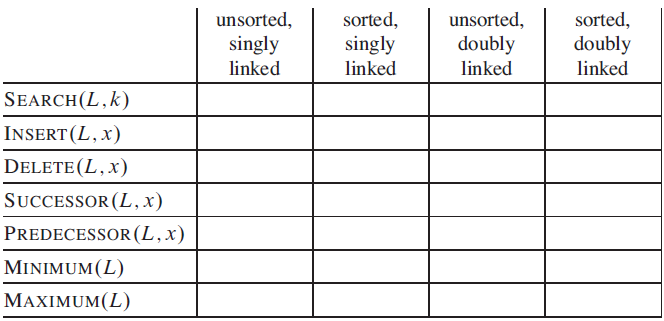
For each of the four types of lists in the following table, what is the asymptotic worst-case running time for each dynamic-set operation listed? sorted, singly unsorted, doubly linked sorted, doubly unsorted, singly linked linked linked SEARCH(L,k) INSERT (L,x) DELETE (L,x) SUCCESSOR (L, x)
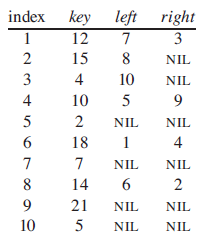
Draw the binary tree rooted at index 6 that is represented by the following attributes: index key left right 1 12 7 3 2 15 8 NIL 3 4 10 NIL 4 10 5 9 2 NIL NIL 18 1 4 7 7 NIL NIL 8 14 2 9. 21 NIL NIL 10 5 NIL NIL
Draw a picture of the sequence 〈13, 4, 8, 19, 5, 11〉 stored as a doubly linked list using the multiple-array representation. Do the same for the single-array representation.
Can you implement the dynamic-set operation INSERT on a singly linked list in O(1) time? How about DELETE?
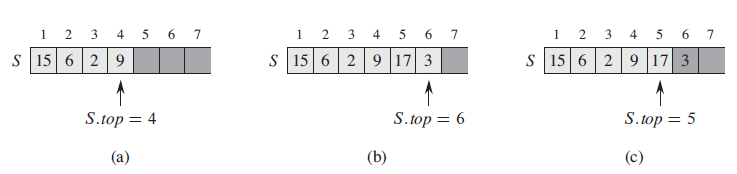
Using Figure 10.1 as a model, illustrate the result of each operation in the sequence PUSH(S, 4), PUSH(S, 1), PUSH(S, 3), POP(S), PUSH(S, 8), and POP(S) on an initially empty stack S stored in array S[1. . 6]. Figure 10.1 4 5 6 7 1 2 3 4 5 6 7 1 2 4 5 6 7 1 S 15 6 2 9 S 15 6 2 9 17 3 S 15 6 2 9
Describe an O(n)-time algorithm that, given a set S of n distinct numbers and a positive integer k – n, determines the k numbers in S that are closest to the median of S.
The kth quantiles of an n-element set are the k - 1 order statistics that divide the sorted set into k equal-sized sets (to within 1). Give an O(n lg k)-time algorithm to list the kth quantiles of a set.
Suppose that an algorithm uses only comparisons to find the i th smallest element in a set of n elements. Show that it can also find the i - 1 smaller elements and the n - i larger elements without performing any additional comparisons.
Suppose we use RANDOMIZED-SELECT to select the minimum element of the array A = 〈3, 2, 9, 0, 7, 5, 4, 8, 6, 1〉. Describe a sequence of partitions that results in a worst-case performance of RANDOMIZED-SELECT.
Analyze SELECT to show that if n ≥ 140, then at least ⌈n/4⌉ elements are greater than the median-of-medians x and at least ⌈n/4⌉ elements are less than x.
Argue that the indicator random variable Xk and the value T(max(k - 1, n - k)) are independent.
Prove the lower bound of ⌈3n/2⌉ - 2 comparisons in the worst case to find both the maximum and minimum of n numbers.
Show that RANDOMIZED-SELECT never makes a recursive call to a 0-length array.
A probability distribution function P(x) for a random variable X is defined by P(x) = Pr {X ≤ x}. Suppose that we draw a list of n random variables X1, X2, . . . ,Xn from a continuous probability distribution function P that is computable in O(1) time. Give an algorithm that sorts these numbers
In the first card-sorting algorithm in this section, exactly how many sorting passes are needed to sort d-digit decimal numbers in the worst case? How many piles of cards would an operator need to keep track of in the worst case?
Suppose that, instead of sorting an array, we just require that the elements increase on average. More precisely, we call an n-element array A k-sorted if, for all i = 1, 2, . . . ,n ? k, the following holds: a. What does it mean for an array to be 1-sorted? b. Give a permutation of the numbers
We are given n points in the unit circle, pi = (xi, yi), such that 0 < x2i + y2i ≤ 1 for i = 1, 2, . . . ,n. Suppose that the points are uniformly distributed; that is, the probability of finding a point in any region of the circle is proportional
Let X be a random variable that is equal to the number of heads in two flips of a fair coin. What is E [X2]? What is E2 [X]?
Suppose that we have an array of n data records to sort and that the key of each record has the value 0 or 1. An algorithm for sorting such a set of records might possess some subset of the following three desirable characteristics:1. The algorithm runs in O(n) time.2. The algorithm is
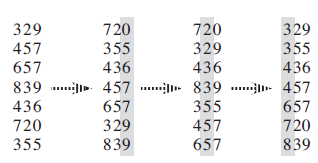
Using Figure 8.3 as a model, illustrate the operation of RADIX-SORT on the following list of English words: COW, DOG, SEA, RUG, ROW, MOB, BOX, TAB, BAR, EAR, TAR, DIG, BIG, TEA, NOW, FOX. Figure 8.3 329 720 720 329 457 355 329 355 657 436 436 436 839 . » 457 .» 839 .» 457 436 657 329 839 355
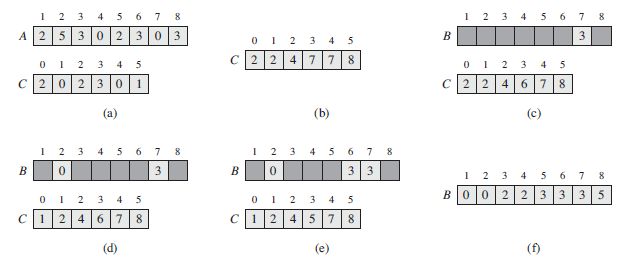
Using Figure 8.2 as a model, illustrate the operation of COUNTING-SORT on the array A = ?6, 0, 2, 0, 1, 3, 4, 6, 1, 3, 2?. Figure 8.2 1 2 3 4 5 6 7 8 1 2 3 4 6 7 8 A 2 53 02 3 0 3 0 1 2 3 4 5 c 2 2 4 7 7 8 0 1 2 3 4 5 C 2 02 3 01 0 1 2 3 4 5 C2 2 46 78 (a) (b) 1 2 4 5 6 7 8 1 2 3 4 5 6 7 8 B0 |3
What is the smallest possible depth of a leaf in a decision tree for a comparison sort?
Consider modifying the PARTITION procedure by randomly picking three elements from array A and partitioning about their median (the middle value of the three elements). Approximate the probability of getting at worst an α-to-(1 – α) split, as a function of α in the range 0 < α < 1.
Argue that for any constant 0 < α ≤ 1/2, the probability is approximately 1 - 2α that on a random input array, PARTITION produces a split more balanced than 1 – α to α.
Consider a sorting problem in which we do not know the numbers exactly. Instead, for each number, we know an interval on the real line to which it belongs. That is, we are given n closed intervals of the form [ai, bi], where ai ≤ bi. We wish to fuzzy-sort these intervals, i.e., to
We can improve the running time of quicksort in practice by taking advantage of the fast running time of insertion sort when its input is "nearly" sorted. Upon calling quicksort on a subarray with fewer than k elements, let it simply return without sorting the subarray. After the top-level call to
One way to improve the RANDOMIZED-QUICKSORT procedure is to partition around a pivot that is chosen more carefully than by picking a random element from the subarray. One common approach is the median-of-3 method: choose the pivot as the median (middle element) of a set of 3 elements randomly
Showing 900 - 1000
of 1549
First
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
Step by Step Answers