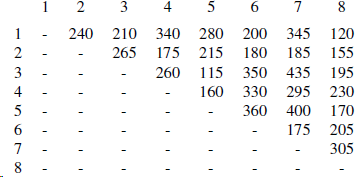New Semester
Started
Get
50% OFF
Study Help!
--h --m --s
Claim Now
Question Answers
Textbooks
Find textbooks, questions and answers
Oops, something went wrong!
Change your search query and then try again
S
Books
FREE
Study Help
Expert Questions
Accounting
General Management
Mathematics
Finance
Organizational Behaviour
Law
Physics
Operating System
Management Leadership
Sociology
Programming
Marketing
Database
Computer Network
Economics
Textbooks Solutions
Accounting
Managerial Accounting
Management Leadership
Cost Accounting
Statistics
Business Law
Corporate Finance
Finance
Economics
Auditing
Tutors
Online Tutors
Find a Tutor
Hire a Tutor
Become a Tutor
AI Tutor
AI Study Planner
NEW
Sell Books
Search
Search
Sign In
Register
study help
computer science
introduction to algorithms
Data Structures and Algorithms in Java 6th edition Michael T. Goodrich, Roberto Tamassia, Michael H. Goldwasser - Solutions
Implement an algorithm that returns a cycle in a directed graph G, if one exists.
Let G be an undirected graph with n vertices and m edges. Describe an O(n+m)-time algorithm for traversing each edge of G exactly once in each direction.
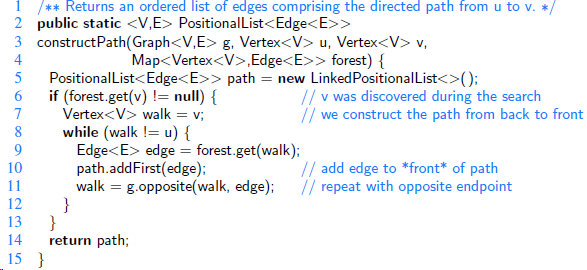
Our solution to reporting a path fromu to v in Code Fragment 14.6 could bemade more efficient in practice if the DFS process ended as soon as v is discovered. Describe how to modify our code base to implement this optimization. 1 / ** Returns an ordered list of edges comprising the directed path
Let T be the spanning tree rooted at the start vertex produced by the depth-first search of a connected, undirected graph G. Argue why every edge of G not in T goes from a vertex in T to one of its ancestors, that is, it is a back edge.
Suppose we wish to represent an n-vertex graph G using the edge list structure, assuming that we identify the vertices with the integers in the set {0,1, . . . ,n−1}. Describe how to implement the collection E to support O(logn)-time performance for the getEdge(u, v) method. How are you
George claims he has a fast way to do path compression in a partition structure, starting at a position p. He puts p into a list L, and starts following parent pointers. Each time he encounters a new position, q, he adds q to L and updates the parent pointer of each node in L to point to q’s
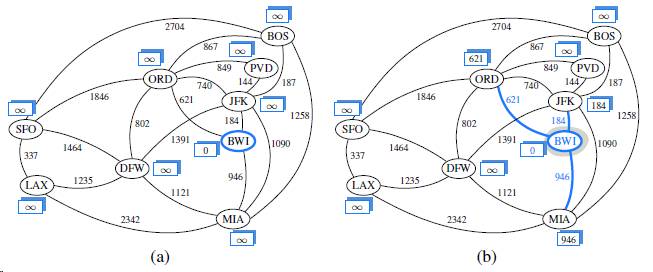
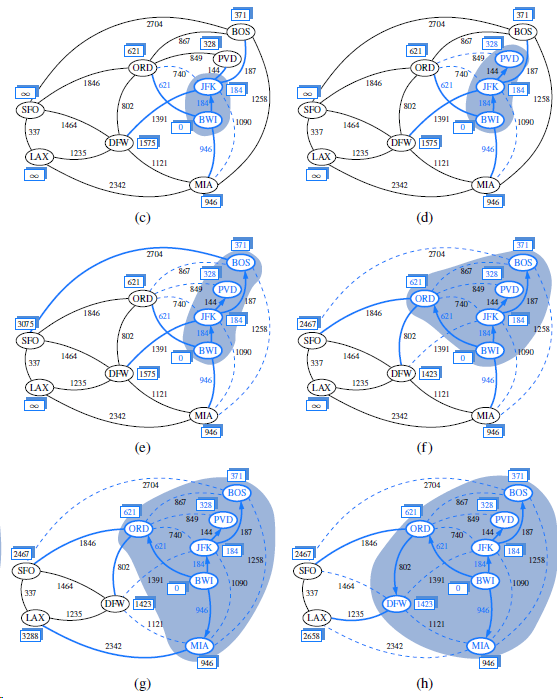
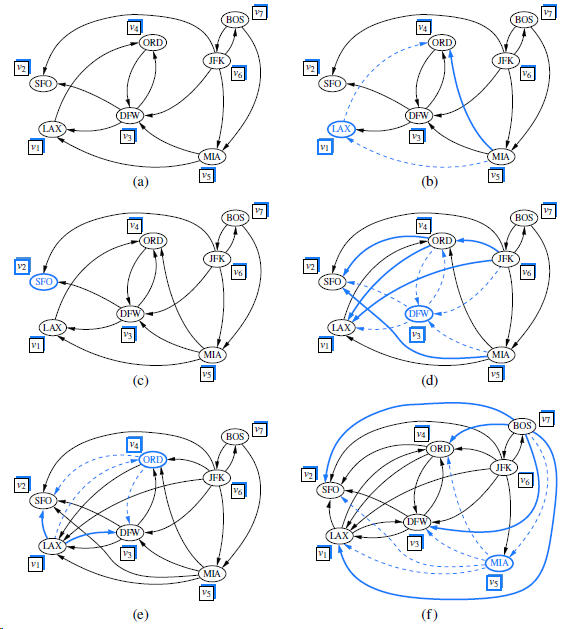
Repeat Exercise R-14.28 for Figures 14.15 and 14.16 illustrating Dijkstra?s algorithm. Figures 14.15 Figures 14.16 Repeat Exercise Describe the meaning of the graphical conventions used in Figure 14.9 illustrating a DFS traversal. What do the line thicknesses signify? What do the arrows
Repeat Exercise R-14.28 for Figure 14.11 illustrating the Floyd-Warshall algorithm. Repeat Exercise Describe the meaning of the graphical conventions used in Figure 14.9 illustrating a DFS traversal. What do the line thicknesses signify? What do the arrows signify? How about dashed lines? H) (F
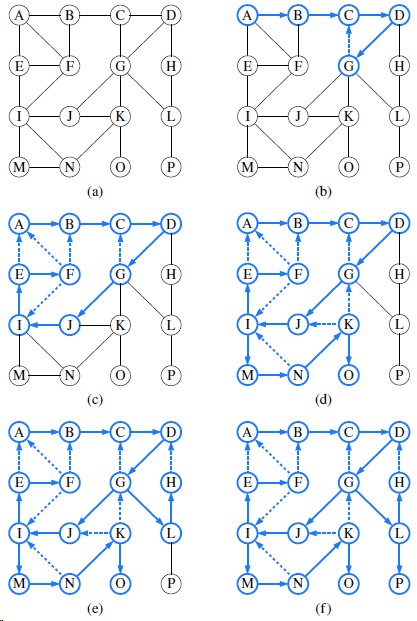
Describe the meaning of the graphical conventions used in Figure 14.9 illustrating a DFS traversal. What do the line thicknesses signify? What do the arrows signify? How about dashed lines? В E F H) E (F (M) (P M) (N (B F H) E (F (1) K (M (B B (D E (F H) E F H (K K) M) M (f)
There are eight small islands in a lake, and the state wants to build seven bridges to connect them so that each island can be reached from any other one via one or more bridges. The cost of constructing a bridge is proportional to its length. The distances between pairs of islands are given in the
Repeat the previous problem for Kruskal’s algorithm.Repeat problemDraw a simple, connected, undirected, weighted graph with 8 vertices and 16 edges, each with unique edge weights. Illustrate the execution of the Prim-Jarn´ık algorithm for computing the minimum spanning tree of this graph.
Draw a simple, connected, undirected, weighted graph with 8 vertices and 16 edges, each with unique edge weights. Illustrate the execution of the Prim-Jarnik algorithm for computing the minimum spanning tree of this graph.
Show how to modify the pseudocode for Dijkstra’s algorithm for the case when the graph is directed and we want to compute shortest directed paths from the source vertex to all the other vertices.
Draw a simple, connected, weighted graph with 8 vertices and 16 edges, each with unique edge weights. Identify one vertex as a “start” vertex and illustrate a running of Dijkstra’s algorithm on this graph.
Explain why the DFS traversal runs in O(n2) time on an n-vertex simple graph that is represented with the adjacency matrix structure.
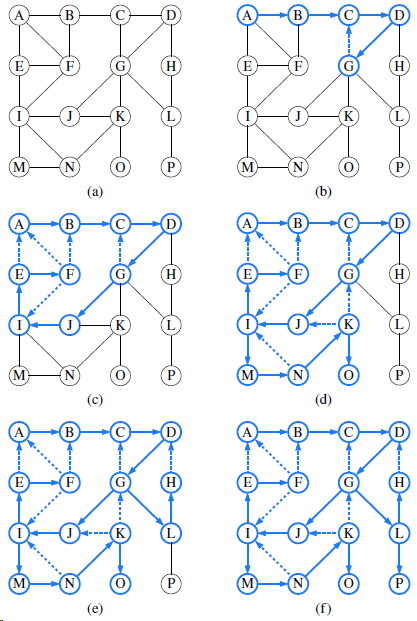
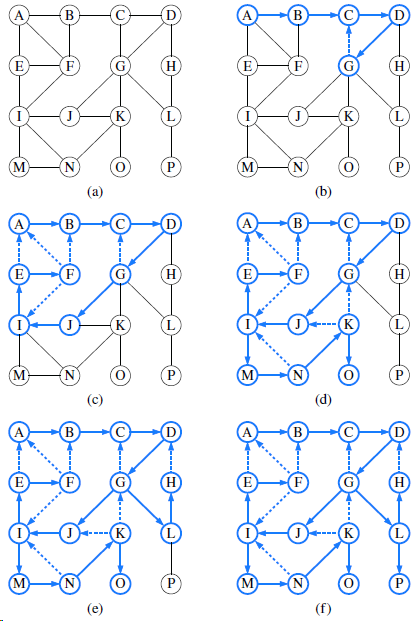
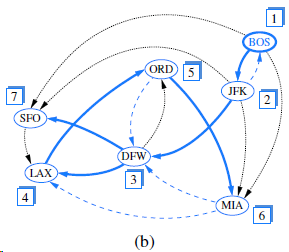
In order to verify that all of its nontree edges are back edges, redraw the graph from Figure 14.8b so that the DFS tree edges are drawn with solid lines and oriented downward, as in a standard portrayal of a tree, and with all nontree edges drawn using dashed lines. 1 BOS ORD 5 7, JFK 2 SFO DFW
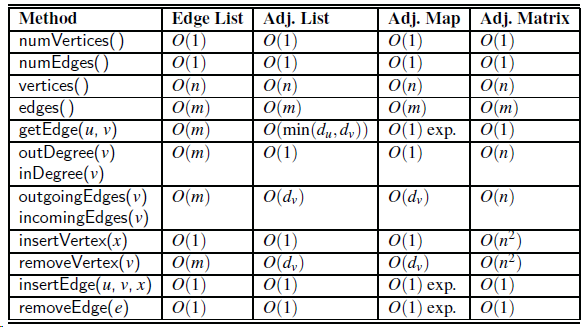
Can edge list E be omitted from the adjacency list representation while still achieving the time bounds given in Table 14.3? Why or why not? Method numVertices(), numEdges() vertices() edges() getEdge(u, v) outDegree(v), inDegree(v) outgoingEdges(v), incomingEdges(v) | 0(deg(v)) insertVertex(x),
Can edge list E be omitted from the adjacency matrix representation while still achieving the time bounds given in Table 14.1? Why or why not? Edge List | Adj. List O(1) 0(1) O(n) O(m) O(m) O(m) Adj. Matrix 0(1) 0(1) O(n) O(m) O(1) O(n) Method Adj. Map O(1) O(1) O(n) O(m) 0(1) exp. O(1)
Give pseudocode for performing the operation insertEdge(u, v, x) in O(1) time using the adjacency matrix representation.
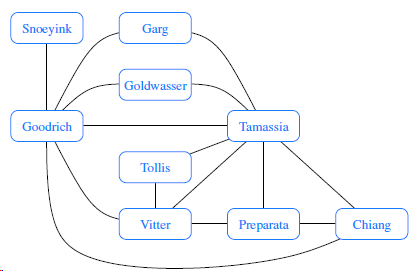
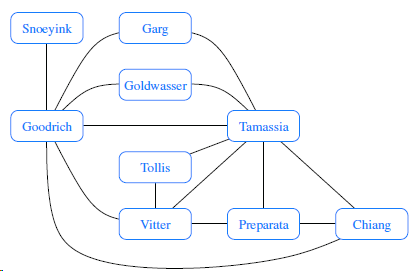
Draw an adjacency list representation of the undirected graph shown in Figure 14.1. Snoeyink Garg Goldwasser Goodrich Tamassia Tollis Vitter Preparata Chiang
Draw an adjacency matrix representation of the undirected graph shown in Figure 14.1. Snoeyink Garg Goldwasser Goodrich Tamassia Tollis Vitter Preparata Chiang
Use the LCS algorithm to compute the best sequence alignment between some DNA strings, which you can get online from GenBank.
A very effective pattern-matching algorithm, developed by Rabin and Karp [54], relies on the use of hashing to produce an algorithm with very good expected performance. Recall that the brute-force algorithm compares the pattern to each possible placement in the text, spending O(m) time, in the
Experiment with the efficiency of the indexOf method of Java’s String class and develop a hypothesis about which pattern-matching algorithm it uses. Describe your experiments and your conclusions.
Perform an experimental comparison of the relative speeds of the brute-force, KMP, and Boyer-Moore pattern-matching algorithms. Document the relative running times on large text documents that are then searched using varyinglength patterns.
Perform an experimental analysis of the efficiency (number of character comparisons performed) of the brute-force and Boyer-Moore pattern-matching algorithms for varying-length patterns.
Perform an experimental analysis of the efficiency (number of character comparisons performed) of the brute-force and KMP pattern-matching algorithms for varying-length patterns.
Let three integer arrays, A, B, and C, be given, each of size n. Given an arbitrary integer k, design an O(n2 logn)-time algorithm to determine if there exist numbers, a in A, b in B, and c in C, such that k = a+b+c.
Let X and Y be strings of length n and m, respectively. Define B(j,k) to be the length of the longest common substring of the suffix X[n− j..n−1] and the suffix Y[m−k..m−1]. Design an O(nm)-time algorithm for computing all the values of B( j,k) for j = 1, . . . ,n and k = 1, . . . ,m.
Write a program that takes two character strings (which could be, for example, representations of DNA strands) and computes their edit distance, based on your algorithm from the previous exercise.
Define the edit distance between two strings X and Y of length n and m, respectively, to be the number of edits that it takes to change X into Y. An edit consists of a character insertion, a character deletion, or a character replacement. For example, the strings "algorithm" and "rhythm" have edit
Give an efficient algorithm for determining if a pattern P is a subsequence (not substring) of a text T. What is the running time of your algorithm?
Let P be a convex polygon, a triangulation of P is an addition of diagonals connecting the vertices of P so that each interior face is a triangle. The weight of a triangulation is the sum of the lengths of the diagonals. Assuming that we can compute lengths and add and compare them in constant
Given a sequence S=(x0,x1, . . . ,xn−1) of numbers, describe an O(n2)-time algorithm for finding a longest subsequence T = (xi0,xi1, . . . ,xik−1) of numbers, such that ij < ij+1 and xij > xij+1. That is, T is a longest decreasing subsequence of S.
Design an efficient algorithm for the matrix chain multiplication problem that outputs a fully parenthesized expression for how to multiply the matrices in the chain using the minimum number of operations.
Implement a compression and decompression scheme that is based on Huffman coding.
Anna has just won a contest that allows her to take n pieces of candy out of a candy store for free. Anna is old enough to realize that some candy is expensive, while other candy is relatively cheap, costing much less. The jars of candy are numbered 0, 1, . . ., m−1, so that jar j has nj pieces
Given a string X of length n and a string Y of length m, describe an O(n+m)-time algorithm for finding the longest prefix of X that is a suffix of Y.
Create a class that implements a prefix trie for a string. The class should have a constructor that takes a string as an argument, and a method for pattern matching on the string.
Create a class that implements a compressed trie for a set of strings. The class should have a constructor that takes a list of strings as an argument, and the class should have a method that tests whether a given string is stored in the trie.
Create a class that implements a standard trie for a set of strings. The class should have a constructor that takes a list of strings as an argument, and the class should have a method that tests whether a given string is stored in the trie.
Describe an algorithmfor constructing the compact representation of a suffix trie, given its noncompact representation, and analyze its running time.
Describe an efficient algorithm to find the longest palindrome that is a suffix of a string T of length n. Recall that a palindrome is a string that is equal to its reversal. What is the running time of your method?
Modify the simplified Boyer-Moore algorithm presented in this chapter using ideas from the KMP algorithm so that it runs in O(n+m) time.
Redo Exercise C-13.16, adapting the Knuth-Morris-Pratt pattern-matching algorithm appropriately to implement a method findLastKMP(T,P).Exercise C-13.16Adapt the brute-force pattern-matching algorithm so as to implement a method findLastBrute(T,P) that returns the index at which the rightmost
Redo the previous problem, adapting the Boyer-Moore pattern-matching algorithm to implement a method findLastBoyerMoore(T,P).
Adapt the brute-force pattern-matching algorithm so as to implement a method findLastBrute(T,P) that returns the index at which the rightmost occurrence of pattern P within text T, if any.
Show the longest common subsequence array L for the two strings:X = "skullandbones"Y = "lullabybabies"What is a longest common subsequence between these strings?
What is the best way to multiply a chain of matrices with dimensions that are 10×5, 5×2, 2×20, 20×12, 12×4, and 4×60? Show your work.
Draw the frequency array and Huffman tree for the following string:"dogs do not spot hot pots or cats".
Draw the compact representation of the suffix trie for the string:"minimize minime".
Compute a table representing the Knuth-Morris-Pratt failure function for the pattern string "cgtacgttcgtac".
Compute a map representing the last function used in the Boyer-Moore patternmatching algorithm for characters in the pattern string:"the quick brown fox jumped over a lazy cat".
Design and implement two versions of the bucket-sort algorithm in Java, one for sorting an array of byte values and one for sorting an array of short values. Experimentally compare the performance of your implementations with that of the method, java.util.Arrays.sort.
Implement an animation of one of the sorting algorithms described in this chapter, illustrating key properties of the algorithm in an intuitive manner.
Design and implement a version of the bucket-sort algorithm for sorting a list of n entries with integer keys taken from the range [0,N −1], for N ≥ 2. The algorithm should run in O(n+N) time.
Implement an in-place version of insertion-sort and an in-place version of quicksort. Perform benchmarking tests to determine the range of values of n where quick-sort is on average better than insertion-sort.
Implement deterministic and randomized versions of the quick-sort algorithm and perform a series of benchmarking tests to see which one is faster. Your tests should include sequences that are very “random” looking as well as ones that are “almost” sorted.
Perform a series of benchmarking tests on a version of merge-sort and quick-sort to determine which one is faster. Your tests should include sequences that are “random” as well as “almost” sorted.
Experimentally compare the performance of in-place quick-sort and a version of quick-sort that is not in-place.
As a generalization of the previous problem, revisit Exercise C-11.45, which involves performing general selection queries on a dynamic set of values.Exercise 11.45Describe a modification to the binary search-tree data structure that would support the following two index-based operations for a
Suppose we are interested in dynamically maintaining a set S of integers, which is initially empty, while supporting the following two operations:add(v): Adds value v to set S.median( ): Returns the current median value of the set. For a set with even cardinality, we define the median as the
We can make the quick-select algorithm deterministic, by choosing the pivot of an n-element sequence as follows:Partition the set S into ⌈n/5⌉ groups of size 5 each (except possibly for one group). Sort each little set and identify the median element in this set. From this set of ⌈n/5⌉
Space aliens have given us a method, alienSplit, that can take a sequence S of n integers and partition S in O(n) time into sequences S1,S2, . . . ,Sk of size at most ⌈n/k⌉ each, such that the elements in Si are less than or equal to every element in Si+1, for i = 1,2, . . . ,k−1, for a fixed
Given an unsorted sequence S of n comparable elements, and an integer k, give an O(nlogk)-expected-time algorithm for finding the O(k) elements that have rank ⌈n/k⌉, 2⌈n/k⌉, 3⌈n/k⌉, and so on.
Show how to use a deterministic O(n)-time selection algorithmto sort a sequence of n elements in O(nlogn)-worst-case time.
Describe an in-place version of the quick-select algorithm in pseudocode, assuming that you are allowed to modify the order of elements.
Our quick-select implementation can be made more space-efficient by initially computing only the counts for sets L, E, and G, and creating only the new subset that will be needed for recursion. Implement such a version.
Given a set of n integers, describe and analyze a fast method for finding the ⌈logn⌉ integers closest to the median.
Let A and B be two sequences of n integers each. Given an integer m, describe an O(nlogn)-time algorithm for determining if there is an integer a in A and an integer b in B such that m = a+b.
Let S be a sequence of n integers. Describe a method for printing out all the pairs of inversions in S in O(n+k) time, where k is the number of such inversions.
Let S be a sequence of n elements on which a total order relation is defined. Recall that an inversion in S is a pair of elements x and y such that x appears before y in S but x > y. Describe an algorithm running in O(nlogn) time for determining the number of inversions in S.
Let S1,S2, . . . ,Sk be k different sequenceswhose elements have integer keys in the range [0,N−1], for some parameter N ≥ 2. Describe an algorithm that produces k respective sorted sequences in O(n+N) time, where n denotes the sum of the sizes of those sequences.
Suppose we are given two sequences A and B of n elements, possibly containing duplicates, on which a total order relation is defined. Describe an efficient algorithm for determining if A and B contain the same set of elements. What is the running time of this method?
Show that any comparison-based sorting algorithmcan bemade to be stable without affecting its asymptotic running time.
Consider the voting problem from Exercise C-12.35, but now suppose the integers 1 to k are used to identify k < n candidates. Design an O(n)-time algorithm to determine who wins the election.In ExerciseSuppose we are given an n-element sequence S such that each element in S represents a
Implement a bottom-up merge-sort for a collection of items by placing each item in its own queue, and then repeatedly merging pairs of queues until all items are sorted within a single queue.
Linda claims to have an algorithm that takes an input sequence S and produces an output sequence T that is a sorting of the n elements in S.a. Give an algorithm, isSorted, that tests in O(n) time if T is sorted.b. Explain why the algorithm isSorted is not sufficient to prove a particular output T
Show that the worst-case running time of quick-select on an n-element sequence is Ω(n2).
What is the best algorithm for sorting each of the following: general comparable objects, long character strings, 32-bit integers, double-precision floating-point numbers, and bytes? Justify your answer.
Show that the best-case running time of quick-sort on a sequence of size n with distinct elements is Ω(nlogn).
Give pseudocode descriptions for the retainAll and removeAll methods of the set ADT, assuming we use sorted sequences to implement sets.
Show that the running time of themerge-sort algorithmon an n-element sequence is O(nlogn), even when n is not a power of 2.
Write a program that performs a simple n-body simulation, called “Jumping Leprechauns.” This simulation involves n leprechauns, numbered 1 to n. It maintains a gold value gi for each leprechaun i, which begins with each leprechaun starting out with a million dollars worth of gold, that is, gi =
Draw four different red-black trees that correspond to the same (2,4) tree.
Suppose you set the key for each position p of a binary tree T equal to its preorder rank. Under what circumstances is T a heap?
How long would it take to remove the ⌈logn⌉ smallest elements from a heap that contains n entries, using the removeMin operation?
Write a program that visualizes an Euler tour traversal of a proper binary tree, including themovements from node to node and the actions associated with visits on the left, from below, and on the right. Illustrate your program by having it compute and display preorder labels, inorder labels,
Write a program that can input and display a person’s family tree.
Write a program that draws a general tree.
Write a program that draws a binary tree.
Write a program that takes as input a general tree T and a position p of T and converts T to another tree with the same set of position adjacencies, but now with p as its root.
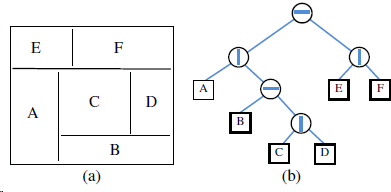
A slicing floor plan divides a rectangle with horizontal and vertical sides using horizontal and vertical cuts. (See Figure 8.23a.) A slicing floor plan can be represented by a proper binary tree, called a slicing tree, whose internal nodes represent the cuts, and whose external nodes represent the
Write a program that takes as input a fully parenthesized, arithmetic expression and converts it to a binary expression tree. Your program should display the tree in some way and also print the value associated with the root. For an additional challenge, allow the leaves to store variables of the
The memory usage for the LinkedBinaryTree class can be streamlined by removing the parent reference from each node, and instead implementing a Position as an object that keeps a list of nodes representing the entire path from the root to that position. Reimplement the LinkedBinaryTree class using
Let T be a binary tree with n positions. Define a Roman position to be a position p in T, such that the number of descendants in p’s left subtree differ from the number of descendants in p’s right subtree by at most 5. Describe a linear-time method for finding each position p of T, such that p
Suppose each position p of a binary tree T is labeled with its value f (p) in a level numbering of T. Design a fast method for determining f (a) for the lowest common ancestor (LCA), a, of two positions p and q in T, given f (p) and f (q). You do not need to find position a, just value f (a).
Design an algorithmfor drawing general trees, using a style similar to the inorder traversal approach for drawing binary trees.
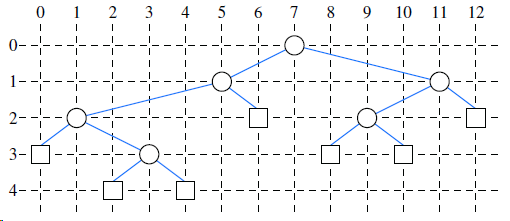
Redo the previous problem for the algorithm postorderDraw that is similar to preorderDraw except that it assigns x(p) to be the number of nodes preceding position p in the postorder traversal.
Algorithm preorderDraw draws a binary tree T by assigning x- and y-coordinates to each position p such that x(p) is the number of nodes preceding p in the preorder traversal of T and y(p) is the depth of p in T. a. Show that the drawing of T produced by preorderDraw has no pairs of crossing
Showing 100 - 200
of 1549
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
Last
Step by Step Answers