New Semester
Started
Get
50% OFF
Study Help!
--h --m --s
Claim Now
Question Answers
Textbooks
Find textbooks, questions and answers
Oops, something went wrong!
Change your search query and then try again
S
Books
FREE
Study Help
Expert Questions
Accounting
General Management
Mathematics
Finance
Organizational Behaviour
Law
Physics
Operating System
Management Leadership
Sociology
Programming
Marketing
Database
Computer Network
Economics
Textbooks Solutions
Accounting
Managerial Accounting
Management Leadership
Cost Accounting
Statistics
Business Law
Corporate Finance
Finance
Economics
Auditing
Tutors
Online Tutors
Find a Tutor
Hire a Tutor
Become a Tutor
AI Tutor
AI Study Planner
NEW
Sell Books
Search
Search
Sign In
Register
study help
computer science
programming language pragmatics
C++ Plus Data Structures 6th Edition Nell Dale, Chip Weems, Tim Richards - Solutions
Implement the Map ADT using the binary search tree as discussed in the chapter.
Why did we define the Map ADT to not allow duplicate key values?
What does the MapADT return when an item is found?
For the Map ADT, ItemType contains a key and a value. When performing a Find operation on a map, we pass it an ItemType object. What should the value field of that object contain?
True or False? When performing a Find operation on a map, if the item is found, the key in the returned ItemType object is the same as what was passed into the function.
True or False? When performing a Find operation on a map, if the item is not present, then the value in the returned ItemType object is the same as what was passed into the function.
How do we tell if a Find operation on a map was successful?
When performing a Store operation on a map, if the item is already present, the map is not changed. If you want to change the value associated with that item’s key, how would you do so?
How could a map be used to implement the Set ADT?
Change the implementation of the Map ADT’s Find operation as discussed in this chapter, so that item is a reference parameter and Find returns a bool result, indicating whether the key was found.
Store the values in a hash table with 20 positions, using the division method of hashing and the linear probing method of resolving collisions.66 47 87 90 126 140 145 153 177 285 393 395 467 566 620 735
Store the values in a hash table with 20 positions, using rehashing as the method of collision resolution. Use key % tableSize as the hash function, and (key + 3) % tableSize as the rehash function.66 47 87 90 126 140 145 153 177 285 393 395 467 566 620 735
Store the values in a hash table with ten buckets, each containing three slots. If a bucket is full, use the next (sequential) bucket that contains a free slot.66 47 87 90 126 140 145 153 177 285 393 395 467 566 620 735
Store the values in a hash table that uses the hash function key % 10 to determine into which of ten chains to put the value.66 47 87 90 126 140 145 153 177 285 393 395 467 566 620 735
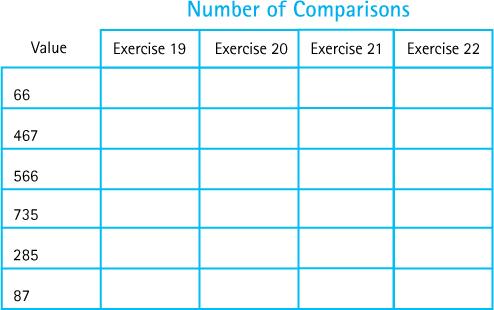
Fill in the following table, showing the number of comparisons needed to find each value using the hashing representations given in Exercises 19–22.Exercises 19–22.19. Store the values in a hash table with 20 positions, using the division method of hashing and the linear probing method of
True or False? Correct any false statements.1. When a hash function is used to determine the placement of elements in an array, the order in which the elements are added does not affect the resulting array.2. When hashing is used, increasing the size of the array always reduces the number of
Choose the answer that correctly completes the following sentence: The number of comparisons required to find an element in a hash table with N buckets, of which M are full,1. is always 1.2. is usually only slightly less than N.3. may be large if M is only slightly less than N.4. is approximately
Show the contents of the array 2. SelectionSort 3. InsertionSort 43 [0] 7 [1] 10 [2] 23 [3] 18. [4] 4 [5] 19 [6] 5 [7] 66 [8] 14 [9]
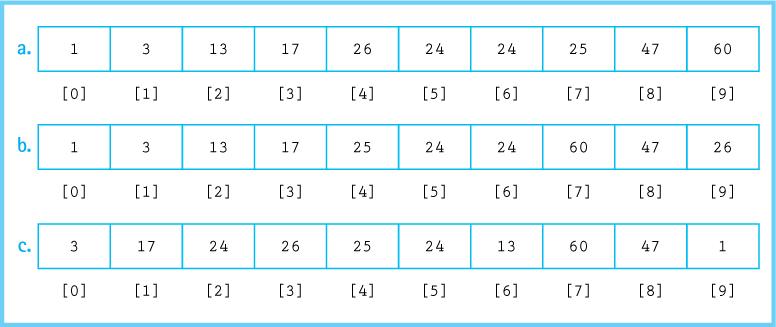
Given the arraytell which sorting algorithm would produce the following results after four iterations: 26 [0] 24 [1] 3 [2] 17 [3] 25 [4] 24 [5] 13 [6] 60 [7] 47 [8] [9]
How many comparisons would be needed to sort an array containing 100 elements using ShortBubble 1. in the worst case? 2. in the best case?
A sorting function is called to sort a list of 100 integers that have been read from a file. If all 100 values are zero, what would the execution requirements (in terms of Big-O notation) be if the sort used was 1. QuickSort, with the first element used as the split value? 2. ShortBubble? 3.
How many comparisons would be needed to sort an array containing 100 elements using SelectionSort if the original array values were already sorted? 1. 10,000 2. 9,900 3. 4,950 4. 99 5. None of the above
A merge sort is used to sort an array of 1,000 test scores in descending order. Which of the following statements is true? 1. The sort is fastest if the original test scores are sorted from smallest to largest. 2. The sort is fastest if the original test scores are in completely random order. 3.
A list is sorted from smallest to largest when a sort algorithm is called. Which of the following sorts would take the longest time to execute, and which would take the shortest time? 1. QuickSort, with the first element used as the split value 2. ShortBubble 3. SelectionSort 4. HeapSort 5.
1. In what cases, if any, is the bubble sort O(N)? 2. In what cases, if any, is the selection sort O(log N)? 3. In what cases, if any, is quick sort O(N )?
A very large array of elements is to be sorted. The program will be run on a personal computer with limited memory. Which sort would be a better choice: a heap sort or a merge sort? Why?
Use the Three-Question Method to verify MergeSort.
True or false? Correct the false statements. 1. MergeSort requires more space to execute than HeapSort. 2. QuickSort (using the first element as the split value) is better for nearly sorted data than HeapSort. 3. The efficiency of HeapSort is not affected by the order of the elements on entrance to
Which of the following is true about QuickSort? 1. A recursive version executes faster than a nonrecursive version. 2. A recursive version has fewer lines of code than a nonrecursive version. 3. A nonrecursive version takes more space on the run-time stack than a recursive version. 4. It can be
What is meant by the statement “Programmer time is an efficiency consideration”? Give an example of a situation in which programmer time is used to justify the choice of an algorithm(possibly at the expense of other efficiency considerations).
Identify one or more correct answers: Reordering an array of pointers to list elements, rather than sorting the elements themselves, is a good idea when 1. the number of elements is very large. 2. the individual elements are large in size. 3. the sort is recursive. 4. there are multiple keys on
Go through the sorting algorithms coded in this chapter and determine which ones are stable as coded. If there are unstable algorithms (other than HeapSort), make them stable.
Give arguments for and against using functions (such as Swap) to encapsulate frequently used code in a sorting routine.
Write a version of the bubble sort algorithm that sorts a list of integers in descending order.
We said that HeapSort is inherently unstable. Explain why.
Sooey County is about to have its annual Big Pig Contest. Because the sheriff’s son, Wilbur, is majoring in computer science, the county hires him to computerize the Big Pig judging. Each pig’s name (string) and weight (integer) are to be read in from the keyboard. The county expects 500
State University needs a listing of the overall SAT percentiles of the 14,226 students it has accepted in the past year. The data are in a text file, with one line per student. That line contains the student’s ID number, SAT overall percentile, math score, English score, and high school grade
Which sorting algorithm would you not use under the following conditions? 1. The sort must be stable. 2. Data are in descending order by key. 3. Data are in ascending order by key. 4. Space is very limited.
Determine the Big-O measure for SelectionSort based on the number of elements moved rather than the number of comparisons 1. for the best case. 2. for the worst case.
Determine the Big-O measure for BubbleSort based on the number of elements moved rather than the number of comparisons 1. for the best case. 2. for the worst case.
Determine the Big-O measure for QuickSort based on the number of elements moved rather than the number of comparisons 1. for the best case. 2. for the worst case.
Determine the Big-O measure for MergeSort based on the number of elements moved rather than the number of comparisons 1. for the best case. 2. for the worst case.
How would you modify the radix sort algorithm to sort the list in descending order?
The radix sort algorithm uses an array of queues. Would an array of stacks work just as well?
On the Web, the Sorts.in file contains a minimal test plan for the sorting algorithms we have studied. Design a more comprehensive test plan and apply it using SortDr.cpp.
Run the parallel merge sort on your own computer, trying various chunk sizes, to see how much speed-up you can obtain from the available parallelism.
The C++ thread library provides a function that returns the number of threads that the hardware is capable of running. Modify the parallel merge sort so that the user specifies a minimum chunk size. The program should then use the number of threads available and MAX_ITEMS to determine the largest
Comparing the results of your experiments in Exercise 31 with the performance obtained from the approach in Exercise 32, does using a thread count that is greater than the number available from the hardware ever produce faster performance? Is it possible to get consistently better performance on
One approach to using parallelism with the radix sort is to divide the array into separate sections and have a separate thread examine each section, taking each value in turn and calling enqueue to place it on the appropriate queue. Can you identify a problem with this approach?
Another way to add parallelism to the radix sort would be to turn the process around and have a thread for each queue. Each thread reads the entire array, looking for the values that should be enqueued on its queue. Thus, all the queues are being filled in parallel. If you implement this approach,
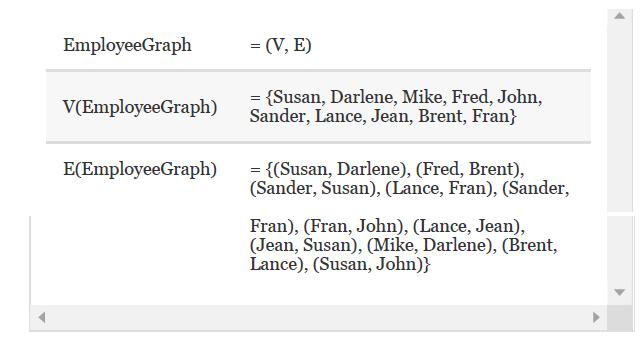
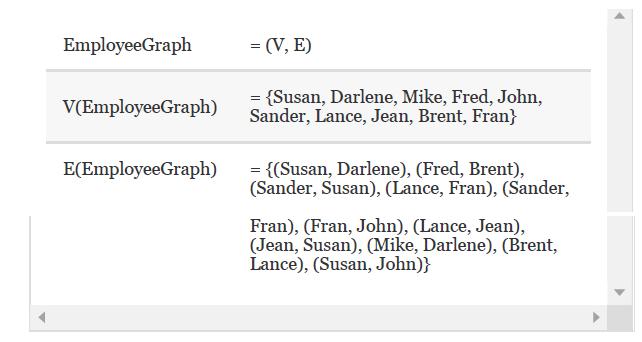
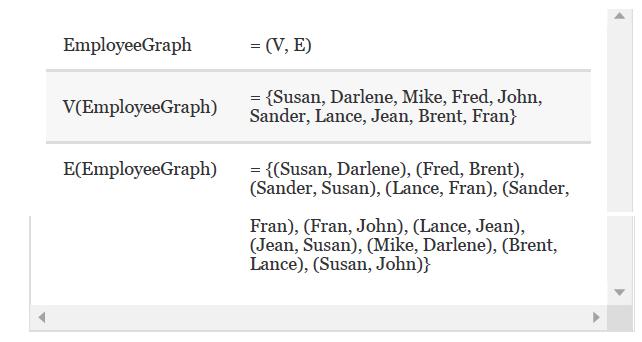
Draw a picture of EmployeeGraph. EmployeeGraph V(EmployeeGraph) E(EmployeeGraph) = (V, E) {Susan, Darlene, Mike, Fred, John, Sander, Lance, Jean, Brent, Fran} = = {(Susan, Darlene), (Fred, Brent), (Sander, Susan), (Lance, Fran), (Sander, Fran), (Fran, John), (Lance, Jean), (Jean, Susan), (Mike,
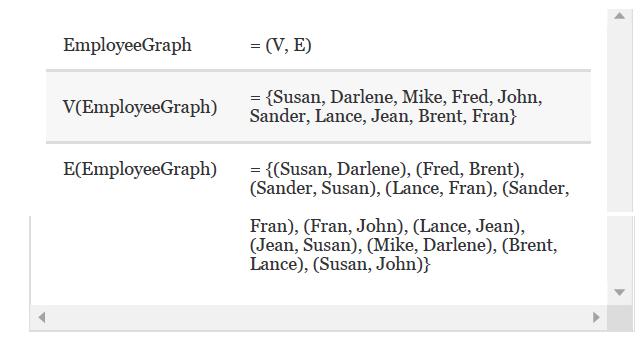
Draw EmployeeGraph, implemented as an adjacency matrix.Store the vertex values in alphabetical order. EmployeeGraph V(EmployeeGraph) E(EmployeeGraph) = (V, E) {Susan, Darlene, Mike, Fred, John, Sander, Lance, Jean, Brent, Fran} = = {(Susan, Darlene), (Fred, Brent), (Sander, Susan), (Lance, Fran),
Using the adjacency matrix for EmployeeGraph from Exercise 12, describe the path from Susan to Lance 1. using a breadth- first strategy. 2. using a depth-first strategy. Exercise 12Extend the class GraphType in this chapter to include a Boolean EdgeExists operation, which determines whether two
Which one of the following phrases best describes the relationship represented by the edges between the vertices in EmployeeGraph? 1. “works for” 2. “is the supervisor of” 3. “is senior to” 4. “works with” EmployeeGraph V(EmployeeGraph) E(EmployeeGraph) = (V, E) {Susan, Darlene,
Draw a picture of ZooGraph. ZooGraph V(ZooGraph) E(ZooGraph) = (V, E) = {dog, cat, animal, vertebrate, oyster, shellfish, invertebrate, crab, poodle, monkey, banana, dalmatian, dachshund} = {(vertebrate, animal), (invertebrate, animal), (dog, vertebrate), (cat, vertebrate), (monkey, vertebrate),
Draw the adjacency matrix for ZooGraph. Store the vertices in alphabetical order. ZooGraph V(ZooGraph) E(ZooGraph) = (V, E) = {dog, cat, animal, vertebrate, oyster, shellfish, invertebrate, crab, poodle, monkey, banana, dalmatian, dachshund} = {(vertebrate, animal), (invertebrate, animal), (dog,
To tell if one element in ZooGraph has relation X to another element, you look for a path between them. Show whether the following statements are true, using the picture or adjacency matrix. 1. dalmatian X dog 2. dalmatian X vertebrate 3. dalmatian X poodle 4. banana X invertebrate 5. oyster X
Which of the following phrases best describes relation X in Exercise 7? 1. “has a” 2. “is an example of” 3. “is a generalization of” 4. “eats”Exercise 7 To tell if one element in ZooGraph has relation X to another element, you look for a path between them. Show whether the
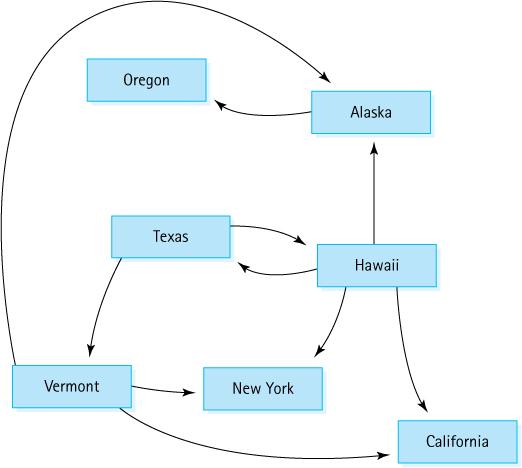
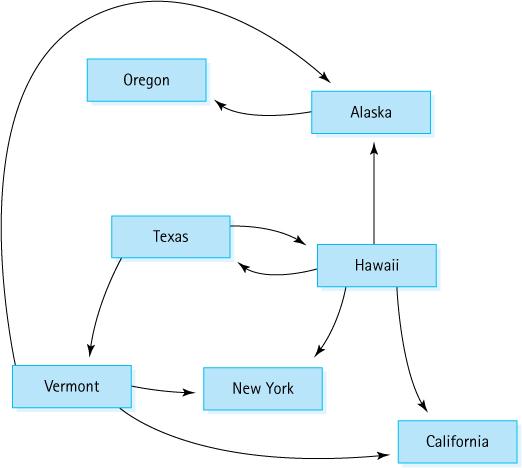
1. Is there a path from Oregon to any other state in the graph? 2. Is there a path from Hawaii to every other state in the graph? 3. From which states in the graph is there a path to Hawaii? Vermont Oregon Texas New York Alaska Hawaii California
1. Show the adjacency matrix that would describe the edges in the graph. Store the vertices in alphabetical order. 2. Show the array-of-pointers adjacency lists that would describe the edges in the graph. Vermont Oregon Texas New York Alaska Hawaii California
Extend the class GraphType in this chapter to include a Boolean EdgeExists operation, which determines whether two vertices are connected by an edge. 1. Write the declaration of this function. Include adequate comments. 2. Using the adjacency matrix implementation developed in the chapter and the
Extend the class GraphType in this chapter to include a DeleteEdge operation, which deletes a given edge. 1. Write the declaration of this function. Include adequate comments. 2. Using the adjacency matrix implementation developed in the chapter and the declaration from part (a), implement the body
Extend the class GraphType in this chapter to include a DeleteVertex operation, which deletes a vertex from the graph.Deleting a vertex from a graph is more complicated than deleting an edge. Discuss why.
The DepthFirstSearch operation can be implemented without a stack by using recursion. 1. Name the base cases. Name the general cases. 2. Write the algorithm for a recursive depth-first search.
Why did we not include traversal operations in GraphType?
Did you notice that we did not include a copy constructor for GraphType? Discuss the issues involved in implementing this copy constructor.
True or False? A binary tree is a type of graph.
True or False? A stack is a type of graph.
True or False? A graph vertex cannot have an edge that connects to itself.
True or False? In an undirected graph, if there is a path from vertex A to vertex B, there is a path from B to A.
True or False? An array representing an adjacency matrix has as many elements as there are edges in the graph.
How many edges are in a complete undirected graph with N vertices?
How many edges are in a complete directed graph with N vertices?
If a graph has 100 vertices and 1,000 edges, what fraction of the array representing its adjacency matrix is filled with NULL_EDGE values?
Explain what we mean by “software engineering.”
Which of these statements is always true? 1. All of the program requirements must be completely defined before design begins. 2. All of the program design must be complete before any coding begins. 3. All of the coding must be complete before any testing can begin. 4. Different development
Name three computer hardware tools that you have used.
Name two software tools that you have used in developing computer programs.
Explain what we mean by “ideaware.”
Explain why software might need to be modified 1. in the design phase. 2. in the coding phase. 3. in the testing phase. 4. in the maintenance phase.
Software quality goal 4 says, “Quality software is completed on time and within budget.” 1. Explain some of the consequences of not meeting this goal for a student preparing a class programming assignment. 2. Explain some of the consequences of not meeting this goal for a team developing a
Functional decomposition is based on a hierarchy of ____________________, and object-oriented design is based on a hierarchy of ____________________.
What is the difference between an object and an object class? Give some examples.
Make a list of potential objects from the description of the ATM scenario given in this chapter.
Have you ever written a programming assignment with an error in the specifications? If so, at what point did you catch the error?How damaging was the error to your design and code?
Explain why the cost of fixing an error is higher the later in the software cycle that the error is detected.
Explain how an expert understanding of your programming language can reduce the amount of time you spend debugging.
Give an example of a run-time error that might occur as the result of a programmer making too many assumptions.
Define “robustness.” How can programmers make their programs more robust by taking a defensive approach?
The following program has three separate errors, each of which would cause an infinite loop. As a member of the inspection team, you could save the programmer a lot of testing time by finding the errors during the inspection. Can you help? void Increment (int); int main() { int count = 1;
Is there any way a single programmer (for example, a student working alone on a programming assignment) can benefit from some of the ideas behind the inspection process?
When is it appropriate to start planning a program’s testing? 1. During design or even earlier 2. While coding 3. As soon as the coding is complete
Differentiate between unit testing and integration testing.
Explain the advantages and disadvantages of the following debugging techniques: 1. Inserting output statements that may be turned off by commenting them out 2. Using a Boolean flag to turn debugging output statements on or off 3. Using a system debugger
Describe a realistic goal-oriented approach to data-coverage testing of the function specified below: FindElement(list, targetltem, index, found) Search list for targetItem. Elements of list are in no particular order; list may be empty. Function: Preconditions: Postconditions: found is true if
A program is to read a numeric score (0 to 100) and display an appropriate letter grade (A, B, C, D, or F). 1. What is the functional domain of this program? 2.Is exhaustive data coverage possible for this program? 3. Devise a test plan for this program.
Explain how paths and branches relate to code coverage in testing.Can we attempt 100% path coverage?
Differentiate between “top-down” and “bottom-up” integration testing.
Explain the phrase “life-cycle verification.”
Write the corrected version of the function Divide.
Showing 100 - 200
of 817
1
2
3
4
5
6
7
8
9
Step by Step Answers