New Semester
Started
Get
50% OFF
Study Help!
--h --m --s
Claim Now
Question Answers
Textbooks
Find textbooks, questions and answers
Oops, something went wrong!
Change your search query and then try again
S
Books
FREE
Study Help
Expert Questions
Accounting
General Management
Mathematics
Finance
Organizational Behaviour
Law
Physics
Operating System
Management Leadership
Sociology
Programming
Marketing
Database
Computer Network
Economics
Textbooks Solutions
Accounting
Managerial Accounting
Management Leadership
Cost Accounting
Statistics
Business Law
Corporate Finance
Finance
Economics
Auditing
Tutors
Online Tutors
Find a Tutor
Hire a Tutor
Become a Tutor
AI Tutor
AI Study Planner
NEW
Sell Books
Search
Search
Sign In
Register
study help
computer science
programming language pragmatics
Programming Language Pragmatics 4th Edition Michael L. Scott - Solutions
Neither Algol 60 nor Algol 68 employs short-circuit evaluation for Boolean expressions. In both languages, however, an if. . . then . . . else construct can be used as an expression. Show how to use if. . . then . . . else to achieve the effect of short-circuit evaluation.
Describe a plausible scenario in which a programmer might wish to avoid short-circuit evaluation of a Boolean expression.
Write an attribute grammar, based on the following context-free grammar, that accumulates jump code for Boolean expressions (with short-circuiting) into a synthesized attribute code of condition, and then uses this attribute to generate code for if statements.You may assume that the code attribute
Consider a language implementation in which we wish to catch every use of an uninitialized variable. In Section 6.1.3 we noted that for types in which every possible bit pattern represents a valid value, extra space must be used to hold an initialized/uninitialized flag. Dynamic checks in such a
In Section 6.1.2 (“Orthogonality”), we noted that C uses = for assignment and == for equality testing. The language designers state: “Since assignment is about twice as frequent as equality testing in typical C programs, it’s appropriate that the operator be half as long”. What do you
Languages that employ a reference model of variables also tend to employ automatic garbage collection. Is this more than a coincidence? Explain.
“For certain values of x, (0.1 + x) * 10.0 and 1.0 + (x * 10.0) can differ by as much as 25%, even when 0.1 and x are of the same magnitude.” Verify this claim. (Warning: If you’re using an x86 processor, be aware that floating-point calculations [even on single-precision variables] are
In Lisp, most of the arithmetic operators are defined to take two or more arguments, rather than strictly two. Thus (* 2 3 4 5) evaluates to 120, and (- 16 9 4) evaluates to 3. Show that parentheses are necessary to disambiguate arithmetic expressions in Lisp (in other words, give an example of an
Translate the following expression into postfix and prefix notation:[−b + sqrt(b × b − 4 × a × c)]/(2 × a)Do you need a special symbol for unary negation?
In Example 6.9 we described a common error in Pascal programs caused by the fact that and and or have precedence comparable to that of the arithmetic operators. Show how a similar problem can arise in the stream-based I/O of C++ (described in Section C 8.7.3). (Consider the precedence of <<
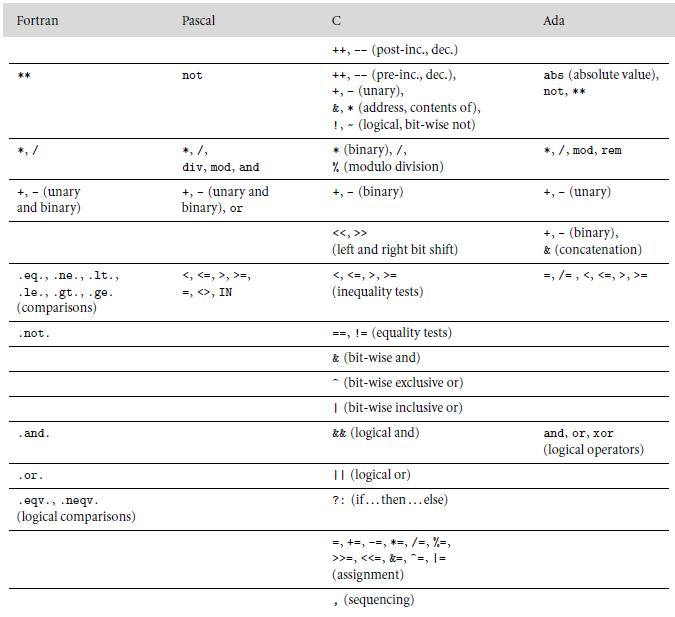
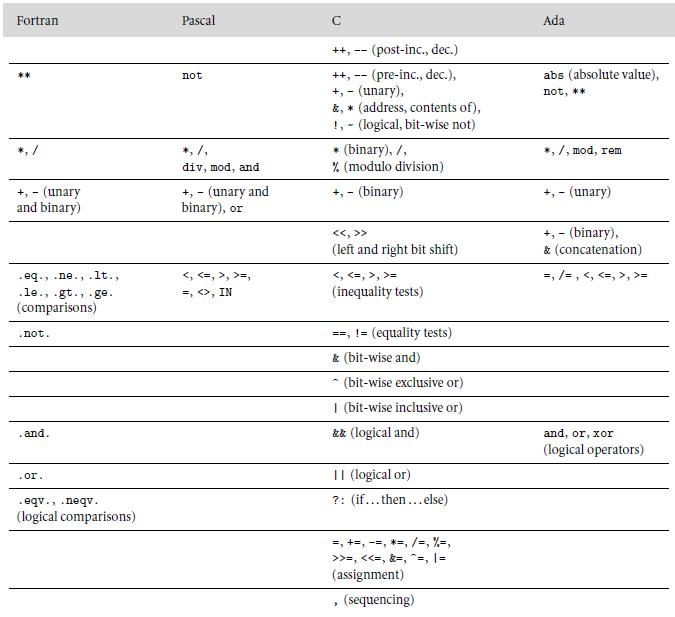
As noted in Figure 6.1, Fortran and Pascal give unary and binary minus the same level of precedence. Is this likely to lead to nonintuitive evaluations of certain expressions? Why or why not?Figure 6.1: Fortran Pascal Ada ++, -- (post-inc., dec.) abs (absolute value), ++, -- (pre-inc., dec.), +, -
We noted in Section 6.1.1 that most binary arithmetic operators are left associative in most programming languages. In Section 6.1.4, however, we also noted that most compilers are free to evaluate the operands of a binary operator in either order. Are these statements contradictory? Why or why not?
One problem with automatic space management for attributes in a top-down parser occurs in lists and sequences. Consider for example the following grammar:block → begin stmt list endstmt list → stmt stmt list tailstmt list tail → ; stmt list | ∈stmt → . . .After predicting the final
Consider the following grammar with action routines:Suppose we are parsing the input IN a, OUT b, and that our compiler uses an automatically maintained attribute stack to hold the active slice of the parse tree. Show the contents of this attribute stack immediately before the parser predicts the
Rewrite the grammar for declarations without the requirement that your attribute flow be L-attributed. Try to make the grammar as simple and elegant as possible (you shouldn’t need to accumulate lists of identifiers).
Repeat Exercise 4.7 using ad hoc attribute space management. Instead of accumulating the translation into a data structure, write it to a file on the fly.Data From Exercise 4.7:Suppose that we want to translate constant expressions into the postfix, or “reverse Polish” notation of logician Jan
Your solution to the previous exercise probably doesn’t generalize to languages with nontrivial scoping rules. Explain how an AG such as that in Figure 4.14 might be modified to use a global symbol table similar to the one described in Section C 3.4.1. Among other things, you should consider
A potential objection to the tree attribute grammar of Example 4.17 is that it repeatedly copies the entire symbol table from one node to another. In this particular tiny language, it is easy to see that the referencing environment never shrinks: the symbol table changes only with the addition of
Explain the need for the A : B notation on the left-hand sides of productions in a tree grammar. Why isn’t similar notation required for context-free grammars?
Modify the CFG and attribute grammar of Figures 4.11 and 4.14 to permit mixed integer and real expressions, without the need for float and trunc. You will want to add an annotation to any node that must be coerced to the opposite type, so that the code generator will know to generate code to do so.
Augment the attribute grammar of Figure 4.5, Figure 4.6, or Exercise 4.21 to initialize a synthesized attribute in every syntax tree node that indicates the location (line and column) at which the corresponding construct appears in the source program. You may assume that the scanner initializes the
Write an attribute grammar based on the CFG of Figure 4.11 that will build a syntax tree with the structure described in Figure 4.14.Figure 4.11:Figure 4.14: program stmt list $$ stmt list + stmt list decl | stmt list stmt | e decl int id real id stmt → id := expr | read id write expr + term |
Write an algorithm to determine whether the rules of an arbitrary attribute grammar are noncircular. (Your algorithm will require exponential time in the worst case [JOR75].)
(a) Write a context-free grammar for case or switch statements in the style of Pascal or C. Add semantic functions to ensure that the same label does not appear on two different arms of the construct.(b) Replace your semantic functions with action routines that can be evaluated during parsing.
(a) Write a context-free grammar for polynomials in x. Add semantic functions to produce an attribute grammar that will accumulate the polynomial’s derivative (as a string) in a synthesized attribute of the root of the parse tree.(b) Replace your semantic functions with action routines that can
Write an LL(1) grammar with action routines and automatic attribute space management that generates the reverse Polish translation described in Exercise 4.7.Data From Exercise 4.7:Suppose that we want to translate constant expressions into the postfix, or “reverse Polish” notation of logician
Building, modify the remainder of the recursive descent parser of Figure 2.17 to build syntax trees for programs in the calculator language.Figure 2.17 (a) Base case A B (b) Concatenation АВ A A|B (c) Alternation A (d) Kleene closure A*
A CFG-based attribute evaluator capable of handling non-L-attributed attribute flow needs to take a parse tree as input. Explain how to build a parse tree automatically during a top-down or bottom-up parse (i.e., without explicit action routines).
Consider the following attribute grammar for variable declarations, based on the CFG:Show a parse tree for the string A, B : C;. Then, using arrows and textual description, specify the attribute flow required to fully decorate the tree. → ID decl_tail decl.t := decl_tail.t decl - decl_tail.in_tab
One potential criticism of the obvious solution to the previous problem is that the values in internal nodes of the parse tree do not reflect the value, in context, of the fringe below them. Create an alternative solution that addresses this criticism. More specifically, create your grammar in such
Consider the following CFG for floating-point constants, without exponential notation. (Note that this exercise is somewhat artificial: the language in question is regular, and would be handled by the scanner of a typical compiler.)C → digits . digitsdigits → digit more digitsmore digits →
To reduce the likelihood of typographic errors, the digits comprising most credit card numbers are designed to satisfy the so-called Luhn formula, standardized by ANSI in the 1960s, and named for IBM mathematician Hans Peter Luhn. Starting at the right, we double every other digit (the second to-
Consider the following grammar for reverse Polish arithmetic expressions:E → E E op | idop → + | - | * | /Assuming that each id has a synthesized attribute name of type string, and that each E and op has an attribute val of type string, write an attribute grammar that arranges for the val
Repeat the previous exercise using the underlying CFG of Figure 4.3.Figure 4.3 1. Е — ТT TT.st := T.val E.val := TT.val 2. ТTi + T T. + T TT2 TT2.st := TT1.st + T.val • TT1.val := TT2.val %3D 3. TTi — - Т T TT2 TT2.st := TT1.st – T.val • TT1.val := TT2.val 4. TT TT.val := TT.st 5. T +
Suppose that we want to translate constant expressions into the postfix, or “reverse Polish” notation of logician Jan Łukasiewicz. Postfix notation does not require parentheses. It appears in stack-based languages such as Postscript, Forth, and the P-code and Java bytecode intermediate forms
Refer back to the context-free grammar. Add attribute rules to the grammar to accumulate into the root of the tree a count of the maximum depth to which parentheses are nested in the program string. For example, given the string f1(a, f2(b * (c + (d - (e - f))))), the stmt at the root of the tree
Lisp has the unusual property that its programs take the form of parenthesized lists. The natural syntax tree for a Lisp program is thus a tree of binary cells (known in Lisp as cons cells), where the first child represents the first element of the list and the second child represents the rest of
Write an S-attributed attribute grammar, based on the CFG of, that accumulates the value of the overall expression into the root of the tree. You will need to use dynamic memory allocation so that individual attributes can hold an arbitrary amount of information.
Give two examples of reasonable semantic rules that cannot be checked at reasonable cost, either statically or by compiler-generated code at run time.
Modify the grammar of Figure 2.25 so that it accepts only programs that contain at least one write statement. Make the same change in the solution to Exercise 2.17. Based on your experience, what do you think of the idea of using the CFG to enforce the rule that every function in C must contain at
Basic results from automata theory tell us that the language L = anbncn = ∈, abc, aabbcc, aaabbbccc, . . . is not context free. It can be captured, however, using an attribute grammar. Give an underlying CFG and a set of attribute rules that associates a Boolean attribute ok with the root R of
Modula-2 provides no way to divide the header of a module into a public part and a private part: everything in the header is visible to the users of the module. Is this a major shortcoming? Are there disadvantages to the public/private division (e.g., as in Ada)?
Consider the following file from some larger C program:int a;extern int b;static int c;void foo() { int a; static int b; extern int c; extern int d;}static int b;extern int c;For each variable declaration, indicate whether the variable has
Consider the following tiny program in C:void hello() { printf("Hello, world\n");}int main() { hello();}(a) Split the program into two separately compiled files, tiny.c and hello.c. Be sure to create a header file hello.h and include it
Repeat the previous exercise for a central reference table.Data From Previous Exercises:Show a trace of the contents of the referencing environment A-list during execution of the program in(a) Figure 3.9. Assume that a positive value is read at line 8.Figure 3.9:(b) Exercise 3.14.Data From Exercise
Show a trace of the contents of the referencing environment A-list during execution of the program in(a) Figure 3.9. Assume that a positive value is read at line 8.Figure 3.9:(b) Exercise 3.14.Data From Exercise 3.14:Consider the following pseudocode:What does this programprint if the language uses
Consider the visibility of class members (fields and methods) in an object-oriented language, as discussed near the end of Section C 3.4.1. Describe a mechanism that could be used to check visibility after first locating the member in a more traditional symbol table.
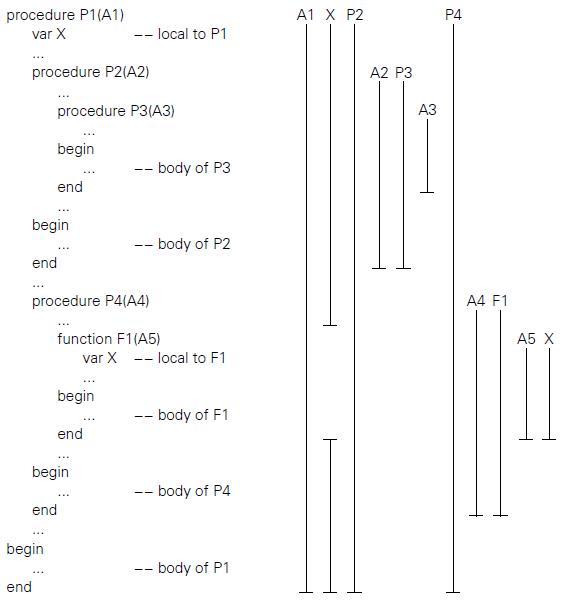
Show the contents of a LeBlanc-Cook style symbol table that captures the referencing environment of function F1 in Figure 3.4.Figure 3.4: procedure P1(A1) A1 X P2 P4 var X -- local to P1 procedure P2(A2) A2 P3 procedure P3(A3) АЗ begin -- body of P3 end ... begin -- body of P2 end ... procedure
Assuming a LeBlanc-Cook style symbol table, explain how the compiler finds the symbol table information (e.g., the type) of a complicated reference such as my_firm->revenues[1999].
Can you write a macro in standard C that “returns” the greatest common divisor of a pair of arguments, without calling a subroutine? Why or why not?
In an imperative language with lambda expressions (e.g., C#, Ruby, C++, or Java), write the following higher-level functions. (A higher-level function, as we shall see in Chapter 11, takes other functions as argument and/or returns a function as a result.)compose(g, f)—returns a function h such
In a language that supports operator overloading, build support for rational numbers. Each number should be represented internally as a (numerator, denominator) pair in simplest form, with a positive denominator. Your code should support unary negation and the four standard arithmetic operators.
Consider mathematical operations in a language like C++, which supports both overloading and coercion. In many cases, it may make sense to provide multiple, overloaded versions of a function, one for each numeric type or combination of types. In other cases, we might use a single version—
Consider the following pseudocode:x : integer := 1y : integer := 2procedure add() x := x + yprocedure second(P : procedure) x : integer := 2 P()procedure first y : integer := 3 second(add)first()write integer(x)(a) What does this
Consider the following pseudocode:x : integer –– globalprocedure set x(n : integer)x := nprocedure print x()write integer(x)procedure foo(S, P : function; n : integer)x : integer := 5if n in {1, 3}set x(n)elseS(n)if n in {1, 2}print x()elsePset x(0); foo(set x, print x, 1); print x()set x(0);
If you are familiar with structured exception handling, as provided in Ada, C++, Java, C#,ML, Python, or Ruby, consider how this mechanismrelates to the issue of scoping. Conventionally, a raise or throw statement is thought of as referring to an exception, which it passes as a parameter to a
As noted, C# has unusually sophisticated support for firstclass subroutines. Among other things, it allows delegates to be instantiated from anonymous nested methods, and gives local variables and parameters unlimited extent when theymay be needed by such a delegate. Consider the implications of
The principal argument in favor of dynamic scoping is that it facilitates the customization of subroutines. Suppose, for example, that we have a library routine print integer that is capable of printing its argument in any of several bases (decimal, binary, hexadecimal, etc.). Suppose further that
Consider the following pseudocode:What does this programprint if the language uses static scoping? What does it print with dynamic scoping? Why? x: integer -- global procedure set xln : integer) x:= n procedure print.x() write.integer(x) procedure firstl) setx(1) print xl) procedure second() x :
Consider the following program in Scheme:What does this programprint? What would it print if Scheme used dynamic scoping and shallow binding? Dynamic scoping and deep binding? Explain your answers. (define A (lambda () (let* ((x 2) (C (lambda (P) (let ((x 4)) (P)))) (D (lambda (() x)) (B (lambda ()
Write a simple program in Scheme that displays three different behaviors, depending on whether we use let, let*, or letrec to declare a given set of names.
Consider the design of a Fortran 77 compiler that uses static allocation for the local variables of subroutines. Expanding on the solution to the previous question, describe an algorithm to minimize the total space required for these variables. You may find it helpful to construct a call graph data
Consider the following fragment of code in C:(a) Assume that each integer variable occupies four bytes. How much total space is required for the variables in this code?(b) Describe an algorithm that a compiler could use to assign stack frame offsets to the variables of arbitrary nested blocks, in a
Rewrite Figures 3.6 and 3.7 in C. You will need to use separate compilation for name hiding.Figures 3.6Figures 3.7 #include namespace rand_mod { unsigned int seed = time (0); // initialize from current time of day const unsigned int a = 48271; const unsigned int m = 0x7ffffff: void set_seed
As part of the development team at MumbleTech.com, Janet has written a list manipulation library for C that contains, among other things, the code in Figure 3.16.(a) Accustomed to Java, new team member Brad includes the following code in the main loop of his program:Sadly, after running for a
Consider the following pseudocode, assuming nested subroutines and static scope:(a) What does this program print?(b) Show the frames on the stack when A has just been called. For each frame, show the static and dynamic links.(c) Explain how A finds g. procedure main() g: integer procedure Bla :
Consider the following pseudocode:1. procedure main()2. a : integer := 13. b : integer := 24. procedure middle()5. b : integer := a6. procedure inner()7. print a, b8. a : integer := 39. –– body of middle10. inner()11. print a, b12. –– body of main13. middle()14. print a, bSuppose this was
Give three concrete examples drawn from programming languages with which you are familiar in which a variable is live but not in scope.
Give two examples in which it might make sense to delay the binding of an implementation decision, even though sufficient information exists to bind it early.
Indicate the binding time (when the language is designed, when the program is linked, when the program begins execution, etc.) for each of the following decisions in your favorite programming language and implementation. Explain any answers you think are open to interpretation.The number of
Prove that the languages in Figure C 2.39 lie in the regions claimed.Figure 2.39
In Fortran 77, local variables were typically allocated statically. In Algol and its descendants (e.g., Ada and C), they are typically allocated in the stack. In Lisp they are typically allocated at least partially in the heap. What accounts for these differences? Give an example of a program in
Prove that regular expressions and left-linear grammars are equally powerful. A left-linear grammar is a context-free grammar in which every right-hand side contains at most one nonterminal, and then only at the left-most end.
Prove that the grammars in Figure C 2.37 lie in the regions claimed.Figure 2.37 LL(2) but not SLL: SLL(k) and SLR(k) but not LR(k 1): S - A at- b | B a- c k-1 S → a A a| b A b a A + be k-1 A E SLL(k) but not LL(k – 1): S - a- b | a k-1 LALR(1) but not SLR: S - bA b|A c|ab A + a LR(0) but not
Extend your solution to exercise 2.21 to implement exception-based syntax error recovery, as in Example C 2.49.Data From Exercise 2.21:Build a complete recursive descent parser for the calculator language. As output, have it print a trace of its matches and predictions.
Extend your solution to exercise 2.21 to implement Wirth’s syntax error recovery mechanism (a) with global FOLLOW sets, as in Example C 2.45. (b) with local FOLLOW sets, as in Example C 2.47 (c) with avoidance of “starter symbol” deletion, as in Example C 2.48.Data From Exercise 2.21:Build a
Give an example of an erroneous program fragment in which the “best” correction would require one to “back up” the parser (i.e., to undo recent predictions/ matches or shifts/reductions).
Give an example of an erroneous program fragment in which consideration of semantic information (e.g., types) might help one make a good choice between two plausible “corrections” of the input.
Consider the following grammar for a declaration list:decl list → decl list decl ; | decl ;decl → id : typetype → int | real | char → array const .. const of type → record decl list endConstruct the CFSM for this grammar. Use it to
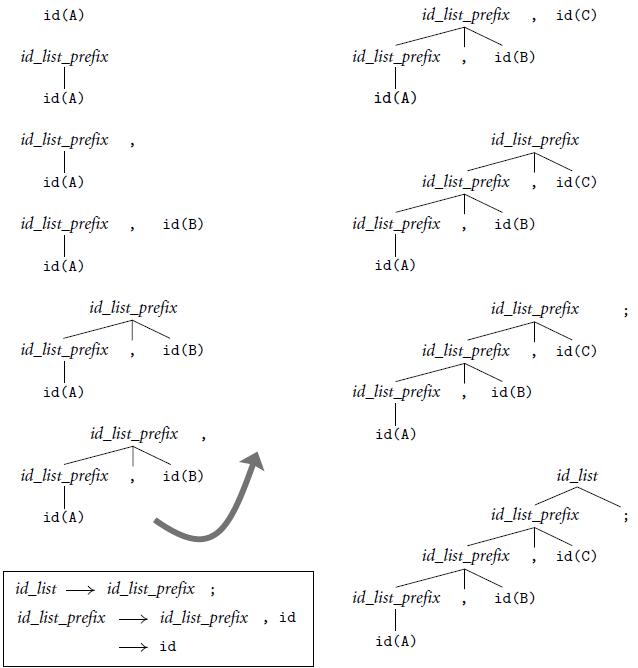
Repeat Example 2.36 using the grammar of Figure 2.15.Figure 2.15: id(A) id_list_prefix id(C) id_list_prefix id_list_prefix id(B) id(A) id(A) id_list_prefix id_list_prefix id(A) id_list_prefix id(C) id_list_prefix id(B) id_list_prefix id(B) id(A) id(A) id_list_prefix id_list_prefix id_list_prefix
Modify the grammar in Exercise 2.27 to allow an id list to be empty. Is the grammar still LR(0)?Data From Exercise 2.27:Construct the CFSM for the id list grammar in Example 2.20 and verify that it can be parsed bottom-up with zero tokens of look-ahead.
Construct the CFSM for the id list grammar in Example 2.20 and verify that it can be parsed bottom-up with zero tokens of look-ahead.
In some languages an assignment can appear in any context in which an expression is expected: the value of the expression is the right-hand side of the assignment, which is placed into the left-hand side as a side effect. Consider the following grammar fragment for such a language. Explain why it
Flesh out the details of an algorithmto eliminate left recursion and common prefixes in an arbitrary context-free grammar.
The dangling else problem of Pascal was not shared by its predecessor Algol 60. To avoid ambiguity regarding which then is matched by an else, Al-gol 60 prohibited if statements immediately inside a then clause. The Pascal fragmentif C1 then if C2 then S1 else S2had to be written as eitherif C1
Extend your solution to Exercise 2.21 to build an abstract syntax tree directly, without constructing a parse tree first.Data From exercise 2.21:Build a complete recursive descent parser for the calculator language. As output, have it print a trace of its matches and predictions.
Prove that the following grammar is LL(1):decl → ID decl taildecl tail → , decl → : ID ;(The final ID is meant to be a type name.)
Expanding on Example 1.25, trace an interpretation of the gcd program on the inputs 12 and 8. Which syntax tree nodes are visited, in which order?Example 1.25Many interpreters use an annotated syntax tree to represent the running program: “execution” then amounts to tree traversal. In our GCD
Why is it difficult to tell whether a program is correct? How do you go about finding bugs in your code? What kinds of bugs are revealed by testing? What kinds of bugs are not? (For more formal notions of program correctness.)
Extend your solution to Exercise 2.21 to build an explicit parse tree.Data From Exercise 2.21:Build a complete recursive descent parser for the calculator language. As output, have it print a trace of its matches and predictions.
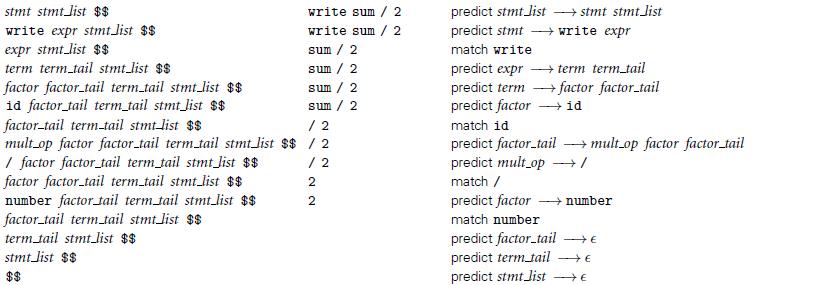
Build a complete recursive descent parser for the calculator language. As output, have it print a trace of its matches and predictions.
Suppose that the expression grammar in Example 2.8 were to be used in conjunction with a scanner that did not remove comments from the input, but rather returned them as tokens. How would the grammar need to be modified to allow comments to appear at arbitrary places in the input?
Write top-down and bottom-up grammars for the language consisting of all well-formed regular expressions. Arrange for all operators to be left associative. Give Kleene closure the highest precedence and alternation the lowest precedence.
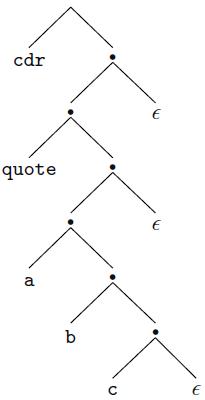
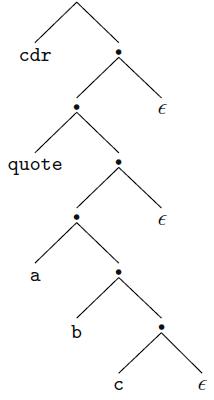
Consider the following LL(1) grammar for a simplified subset of Lisp:P → E $$E → atom → ’ E → ( E Es )Es → E Es →(a) What is FIRST(Es)? FOLLOW(E)? PREDICT(Es → ∈)?(b) Give a parse tree for the string (cdr ‚(a b c)) $$.(c) Show the left-most
Extend the grammar of Figure 2.25 to include if statements and while loops, along the lines suggested by the following examples:abs := nif n < 0 then abs := 0 - abs fisum := 0read countwhile count > 0 do read n sum := sum + n
Give a grammar that captures all levels of precedence for arithmetic expressions in C.
Consider the following context-free grammar.G → G B → G N → ∈B → ( E )E → E ( E ) → ∈N → ( L ]L → L E → L ( → ∈(a) Describe, in English, the language generated by this grammar. (Your description should be a
Consider the language consisting of all strings of properly balanced parentheses and brackets.(a) Give LL(1) and SLR(1) grammars for this language.(b) Give the corresponding LL(1) and SLR(1) parsing tables.(c) For each grammar, show the parse tree for ([]([]))[](()).(d) Give a trace of the actions
Consider the following grammar:stmt → assignment → subr_callassignment → id := exprsubr call → id ( arg list )expr → primary expr tailexpr tail → op expr → ∈primary → id
Consider the following grammar:G → S $$S → A MM → S | ∈A → a E | b A AE → a B | b A | ∈B → b E | a B B(a) Describe in English the language that the grammar generates.(b) Show a parse tree for the string a b a a.(c) Is the grammar LL(1)? If so, show the parse table; if not, identify
Showing 700 - 800
of 817
1
2
3
4
5
6
7
8
9
Step by Step Answers