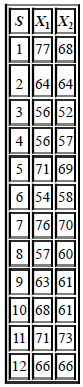
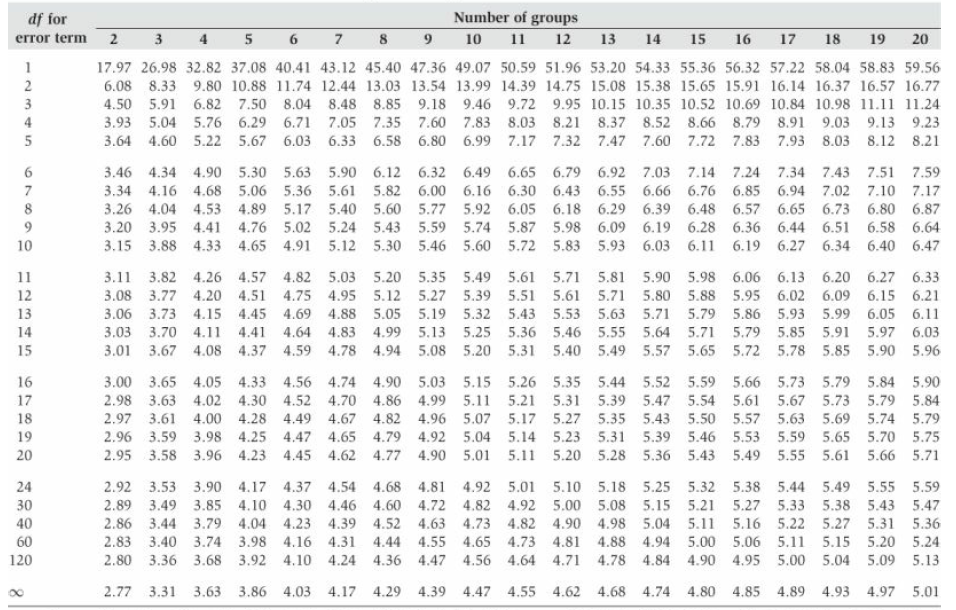
Introductory Statistics For The Behavioral Sciences 7th Edition Joan Welkowitz, Barry H. Cohen, R. Brooke Lea - Solutions
Discover comprehensive support for "Introductory Statistics For The Behavioral Sciences 7th Edition" by Joan Welkowitz, Barry H. Cohen, and R. Brooke Lea. Our platform offers an extensive collection of resources, including an online answers key, solutions manual, and solutions PDF to aid your understanding. Dive into solved problems with step-by-step answers, questions and answers, and access the test bank for thorough preparation. Explore chapter solutions and the instructor manual for in-depth insights into the textbook material. Enjoy the convenience of free download options, ensuring all your study needs are met efficiently and effectively.