

Question: I have an ordinal regression predictive model (screenshots below). I want to edit this model to incorporate BERT. Basically, I want to perform an ordinal
I have an ordinal regression predictive model (screenshots below). I want to edit this model to incorporate BERT. Basically, I want to perform an ordinal regression using BERT and transformers to predict a [0-5] rating.
Mainly, I just want a better accuracy score than the model below- hopefully, incorporating BERT achieves this, if not, let me know a way!
Note, the code below is only a reference and can be edited as much as needed :)
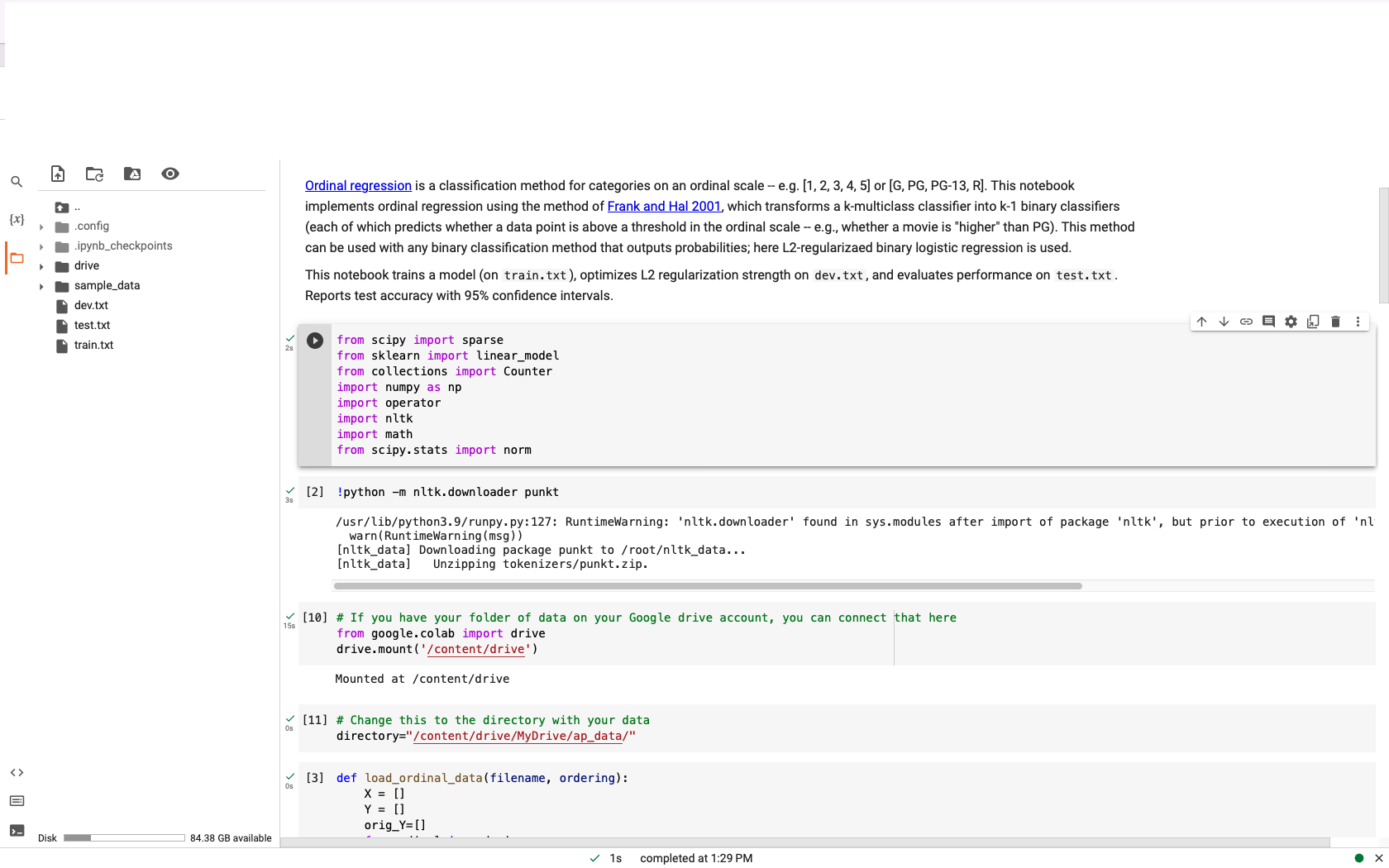
![an ordinal scale -- e.g. [1, 2, 3, 4, 5] or [G,](https://dsd5zvtm8ll6.cloudfront.net/si.experts.images/questions/2024/02/65c3592fb6f86_16765c3592f8ba22.jpg)
![PG, PG-13, R]. This notebook implements ordinal regression using the method of](https://dsd5zvtm8ll6.cloudfront.net/si.experts.images/questions/2024/02/65c35930279ba_16865c3593004a01.jpg)
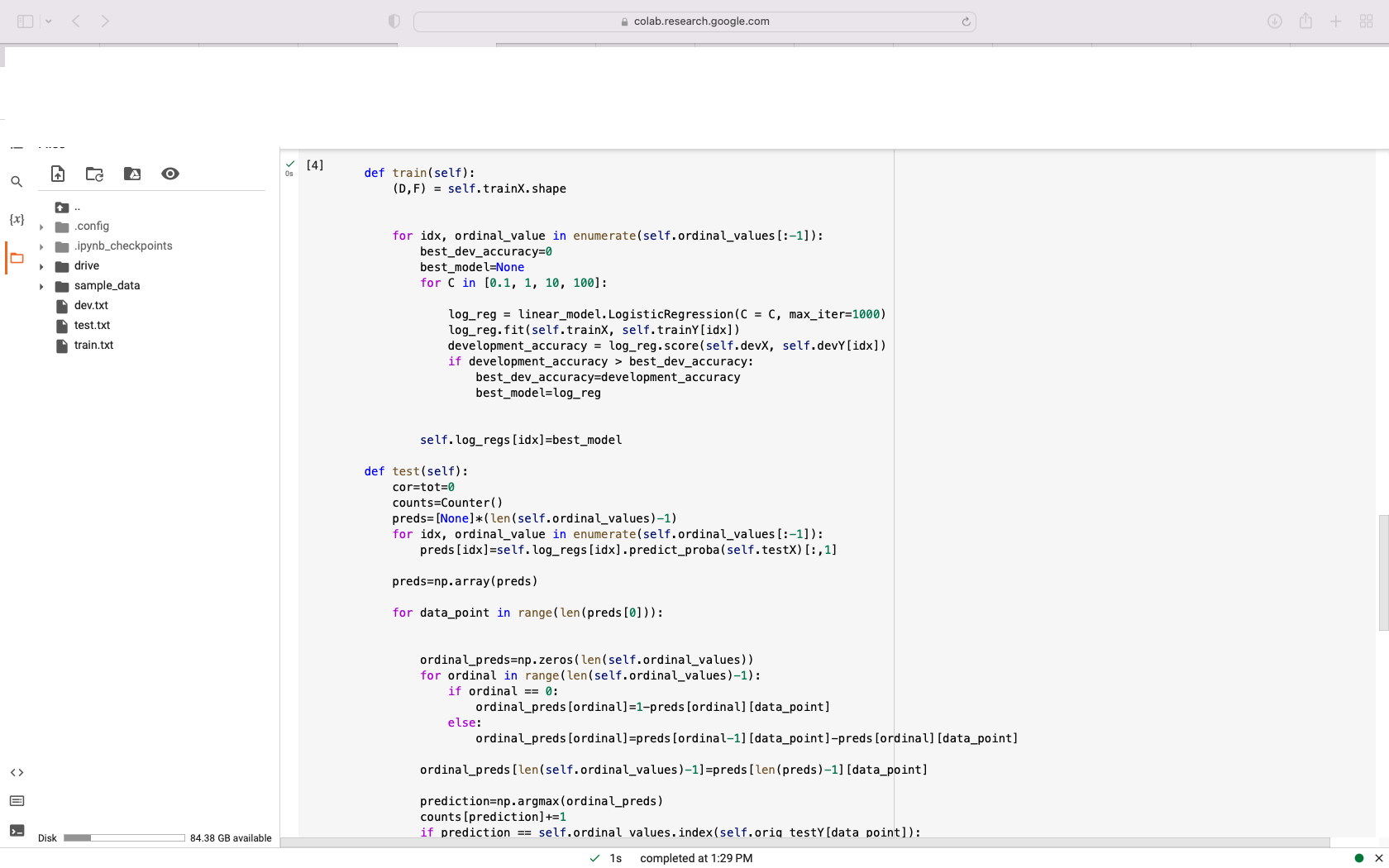
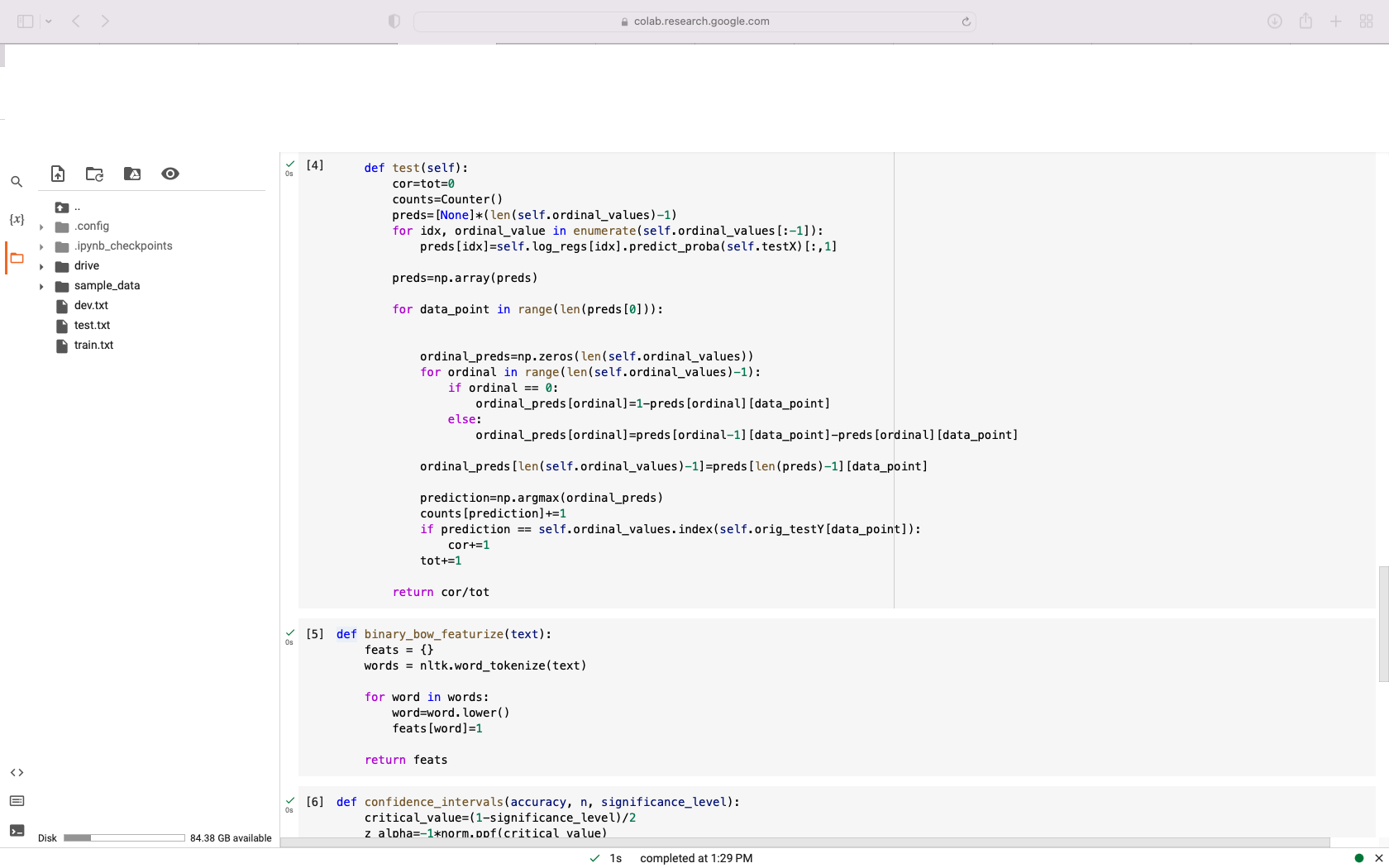
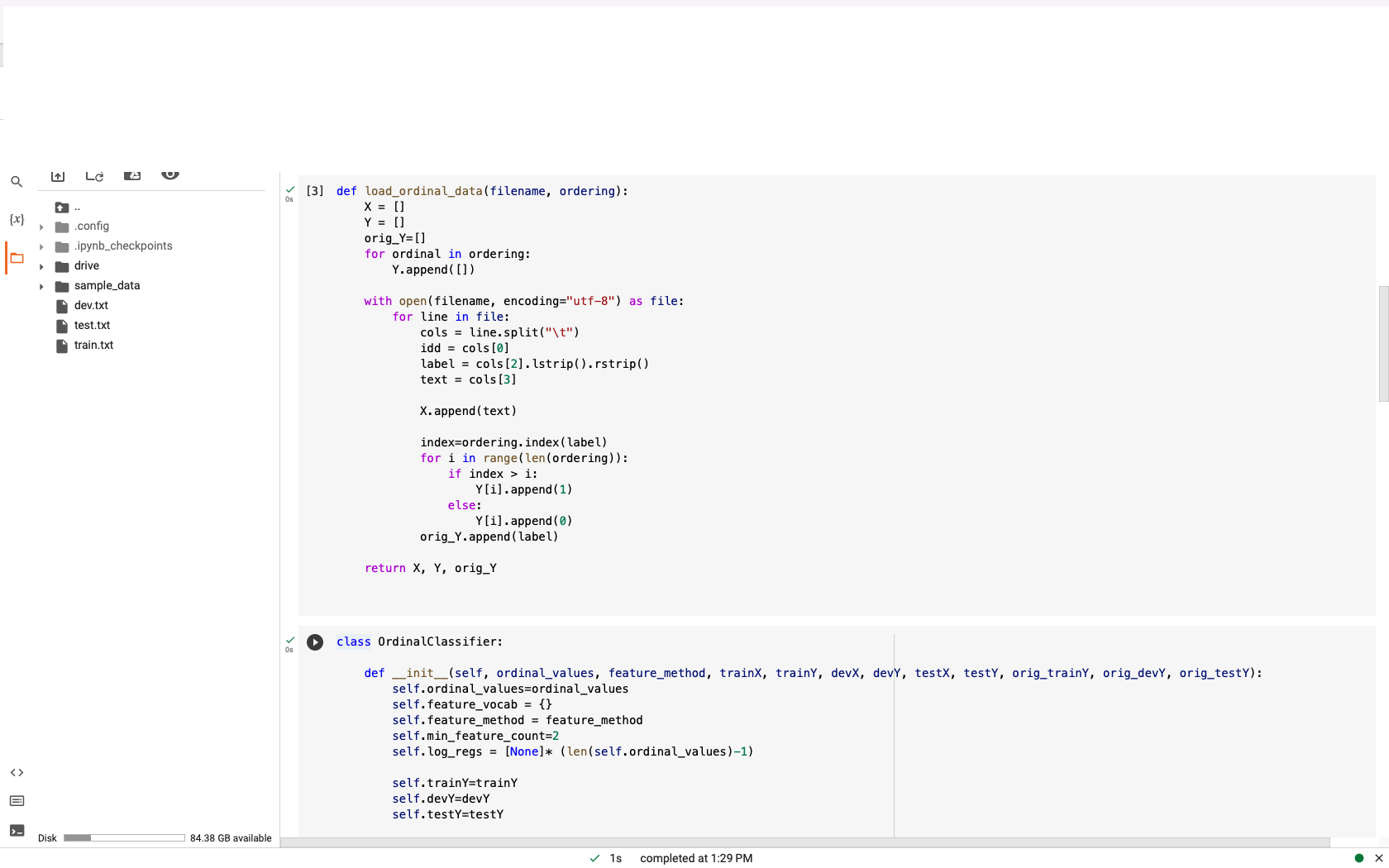
{x} POPII. Disk .config .ipynb_checkpoints drive sample_data dev.txt test.txt train.txt 84.38 GB available 158 Os Ordinal regression is a classification method for categories on an ordinal scale -- e.g. [1, 2, 3, 4, 5] or [G, PG, PG-13, R]. This notebook implements ordinal regression using the method of Frank and Hal 2001, which transforms a k-multiclass classifier into k-1 binary classifiers (each of which predicts whether a data point is above a threshold in the ordinal scale -- e.g., whether a movie is "higher" than PG). This method can be used with any binary classification method that outputs probabilities; here L2-regularizaed binary logistic regression is used. This notebook trains a model (on train.txt), optimizes L2 regularization strength on dev. txt, and evaluates performance on test.txt. Reports test accuracy with 95% confidence intervals. from scipy import sparse from sklearn import linear_model from collections import Counter import numpy as np import operator import nltk import math from scipy.stats import norm [nltk_data] Downloading package punkt to /root/nltk_data... [nltk_data] Unzipping tokenizers/punkt.zip. [2] !python -m nltk.downloader punkt /usr/lib/python3.9/runpy.py: 127: RuntimeWarning: 'nltk.downloader' found in sys.modules after import of package 'nltk', but prior to execution of 'nl warn (RuntimeWarning (msg)) [10] # If you have your folder of data on your Google drive account, you can connect that here from google.colab import drive drive.mount('/content/drive') Mounted at /content/drive [11] # Change this to the directory with your datal directory="/content/drive/MyDrive/ap_data/" [3] def load_ordinal_data(filename, ordering): X = [] Y = [] orig_Y= [] 1s completed at 1:29 PM X
Step by Step Solution
There are 3 Steps involved in it

Get step-by-step solutions from verified subject matter experts