

Question: Issue with python code used for correlation (person) using databricks. This is what I'm receiving: **I have to use df = spark.read.format(csv).option(header, False).load ** CODE
Issue with python code used for correlation (person) using databricks.
This is what I'm receiving:
**I have to use df = spark.read.format("csv").option("header", "False").load **
CODE
import pandas as pd
## DataFrameReader
df = spark.read.format("csv").option("header", "False").load("dbfs:/FileStore/tables/users_no_labels.txt").toPandas()
##find correlation
correlation = df.corr(method = 'pearson')
##to display full correlation dataframe
with pd.option_context('display.max_rows', None, 'display.max_columns', None):
print(correlation)
**********************************************************************************
users_no_labels.txt Data:
0 , 1 , 0 1 , 0 , 0 1 , 1 , 0 0 , 1 , 1 1 , 0 , 1 0 , 1 , 1
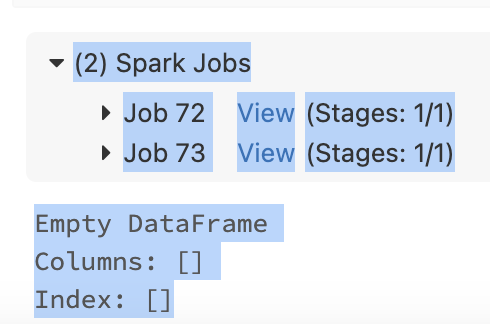
(2) Spark Jobs - Job 72 View (Stages: 1/1) - Job 73 View (Stages: 1/1) Empty DataFrame Columns: [] Index: []
Step by Step Solution
There are 3 Steps involved in it

Get step-by-step solutions from verified subject matter experts