

Question: What is the baseline performance (in cycles, per loop iteration) of the code sequence in Figure 3.47 if no new instructions execution could be initiated
What is the baseline performance (in cycles, per loop iteration) of the code sequence in Figure 3.47 if no new instructions execution could be initiated until the previous instructions execution had completed? Ignore front-end fetch and decode. Assume for now that execution does not stall for lack of the next instruction, but only one instruction/cycle can be issued. Assume the branch is taken, and that there is a one-cycle branch delay slot.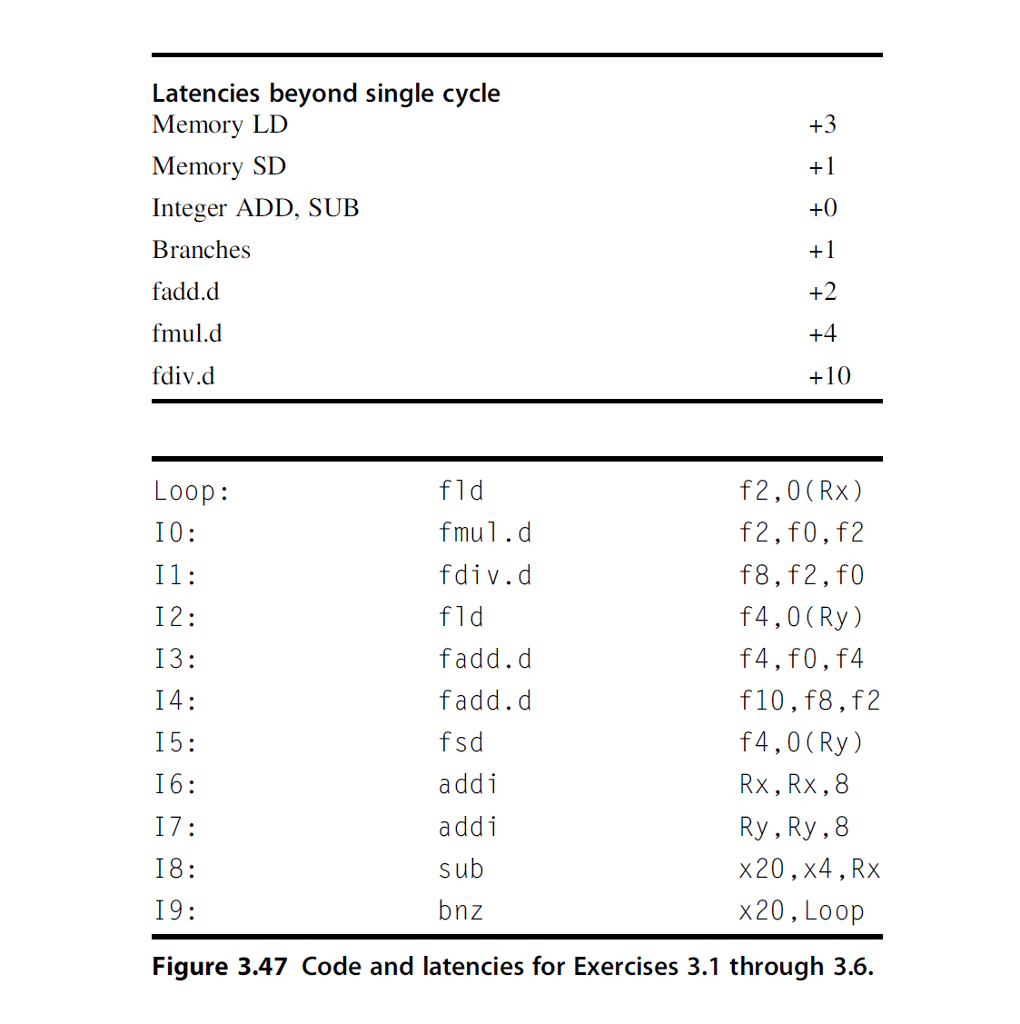
Latencies beyond single cycle Memory LD Memory S Integer ADD, SUB Branche:s fadd.d fmul.d fdiv.d fld fmul.d fdiv.d fld fadd.d fadd.d f2,0 (Rx) f2,f0,f2 f8,f2,fO f4,0 (Ry) f4,f0,f4 f10,f8,f2 f4,0 (Ry) Rx, Rx,8 Ry, Ry,8 x20,x4, Rx x20, Loop oop: IO: I2 13: addi add sub bnz 18: 19: Figure 3.47 Code and latencies for Exercises 3.1 through 3.6
Step by Step Solution
There are 3 Steps involved in it

Get step-by-step solutions from verified subject matter experts