New Semester
Started
Get
50% OFF
Study Help!
--h --m --s
Claim Now
Question Answers
Textbooks
Find textbooks, questions and answers
Oops, something went wrong!
Change your search query and then try again
S
Books
FREE
Study Help
Expert Questions
Accounting
General Management
Mathematics
Finance
Organizational Behaviour
Law
Physics
Operating System
Management Leadership
Sociology
Programming
Marketing
Database
Computer Network
Economics
Textbooks Solutions
Accounting
Managerial Accounting
Management Leadership
Cost Accounting
Statistics
Business Law
Corporate Finance
Finance
Economics
Auditing
Tutors
Online Tutors
Find a Tutor
Hire a Tutor
Become a Tutor
AI Tutor
AI Study Planner
NEW
Sell Books
Search
Search
Sign In
Register
study help
computer sciences
artificial intelligence
Artificial Intelligence A Modern Approach 2nd Edition Stuart J. Russell and Peter Norvig - Solutions
Show that the statement P (A, B│C) = P (A│C) P (D│C) is equivalent to either of the statements P (A│B, C) = P (A│C) and P (B│A, C) = P (B│C).
Suppose you are given a bag containing n unbiased coins. You are told that n — 1 of these coins are normal, with heads on one side arid tails on the other, whereas one coin is a fake, with heads on both sides.a. Suppose you reach into the bag, pick out a coin uniformly at random, flip it, and get
In this exercise, you will complete the normalization calculation for the meningitis example. First, make up a suitable value for P(S —M), and use it to calculate un-normalized values for P (M│S) and P (—’M│S) (i.e., ignoring the P (S) term in the Bayes’ rule expression). Now normalize
This exercise investigates the way in which conditional independence relationships affect the amount of information needed for probabilistic calculations.a. Suppose we wish to calculate P (h│e1, e2) and we have no conditional independence information. Which of the following sets of numbers are
Let X, Y, Z be Boolean random variables. Label the eight entries in the joint distribution P (X. Y, Z) as a through h. Express the statement that X and Y are conditionally independent given Z as a set of equations relating a through h. How many non-redundant equations are there?
(Adapted from Pearl (1988)) Suppose you are a witness to a nighttime hit-and-run accident involving a taxi in Athens. All taxis in Athens are blue or green. You swear, under oath, that the taxi was blue. Extensive testing shows that, under the dim lighting conditions, discrimination between blue
(Adapted from Pearl (1988)) Three prisoners, A, B, and C, are locked in their cells. It is common knowledge that one of them will be executed the next day and the others pardoned. Only the governor knows which one will be executed. Prisoner A asks the guard a favor. “Please ask the governor who
Write out a general algorithm for answering queries of the form P (Cause│e), using a naive Bayes distribution. You should assume that the evidence e may assign values to any subset of the effect variables.
Text categorization is the task of assigning a given document to one of a fixed set of categories, on the basis of the text it contains. Naive Bayes models are often used for this task in these models, the query variable is the document category, and the ‘effect” variables are the presence or
In our analysis of the wumpus world, we used the fact that each square contains a pit with probability 0.2, independently of the contents of the other squares. Suppose instead that exactly N/5 pits are scattered uniformly at random among the N squares other than [1, 1]. Are the variables P and P i,
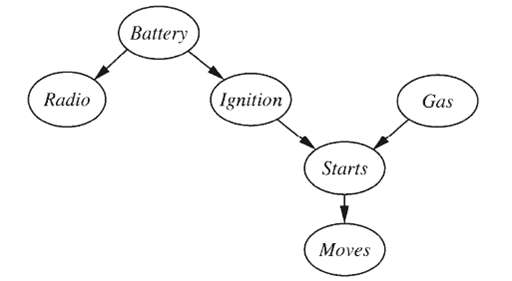
Consider the network for car diagnosis shown in Figure. a. Extend the network with the Boolean variables Icy Weather and Starter Motor. b. Give reasonable conditional probability tables for all the nodes. c. How many independent values are contained in the joint probability distribution for eight
In your local nuclear power station, there is an alarm that senses when a temperature gauge exceeds a given threshold. The gauge measures the temperature of the core. Consider the Boolean variables A (alarm sounds), FA (alarm is faulty), and FG (gauge is faulty) and the multi-valued nodes G (gauge
Two astronomers in different parts of the world make measurements M1 and M2 of the number of stars N in some small region of the sky, using their telescopes. Normally, there is a small possibility e of error by up to one star in each direction. Each telescope can also (with a much smaller
Consider the family of linear Gaussian networks, as illustrated.a. In a two-variable network, let X1 he the parent of X2, let X1 have a Gaussian prior, and let P (X2, X1) be a linear Gaussian distribution. Show that the joint distribution P(X1, X2) is a multivariate Gaussian, and calculate its
The probit distribution defined, describes the probability distribution for a Boolean child, given a single continuous parent.a. How might the definition be extended to cover multiple continuous parents?b. How might it be extended to handle a multivalued child variable? Consider both cases where
This exercise is concerned with the variable elimination algorithm in Figure. a. Section 14.4 applies variable elimination t the query P (Burglary?JohnCalls = true, Mary Calls = true). Perform the calculations indicated and check the answer is correct. b. Count the number of arithmetic operations
Investigate the complexity of exact inference in general Bayesian networks:a. Prove that any 3-SAT problem can be reduced to exact inference in a Bayesian network constructed to represent the particular problem and hence that exact inference is NP- hard.b. The problem of counting the number of
Consider the problem of generating a random sample Iron, a specified distribution on a single variable. You can assume that a random number generator is available that returns a random number uniformly distributed between 0 and 1.(a). Let X be a discrete variable with P (X = xi) = pi for I Є
The Markov blanket of a variable is defined.a. Prove that a variable is independent of all other variables in the network, given its Markov blanket.b. Derive Equation (14.11).
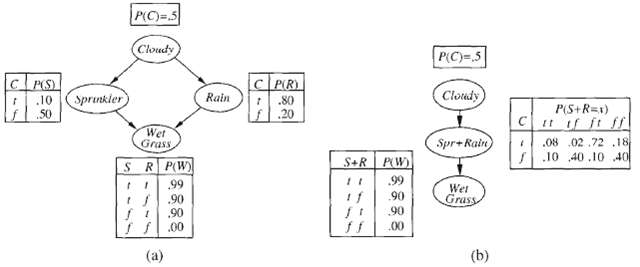
Consider the query P (Rain?Sprinkler = true, Wet-Grass = true) in Figure (a) and how MCMC can answer it. a. How many states does the Markov chain have? b. Calculate the transition matrix Q containing q (y ? y?) for all y. y?. c. What does Q2, the square of the transition matrix, represent? d. What
Three soccer teams A. B, and C, play each other once. Each match is between two (earns, and can be won, drawn, or lost. Each team has a fixed, unknown degree of quality— an integer ranging from 0 to 3—and the outcome of a match depends probabilistically on the difference in quality between the
Show that any second-order Markov process can be rewritten as a first-order Markov process with an augmented set of state variables. Can this always he done parsimoniously that is, without increasing the number of parameters needed to specify the transition model?
In this exercise, we examine what happens to the probabilities in the umbrella world iii (tie limit of lung time sequences.a. Suppose we observe an unending sequence of days on which the umbrella appears. Show that, as the days go by, the probability of rain on the current day increases
This exercise develops a space-efficient variant of the forward'backward algorithm described in Figure. We wish to compute P (X k?e l; t) for k = 1... t. This will be done with a divide-and-conquer approach. a. Suppose, for simplicity, that t is odd, and let the halfway point he h = (t + 1)/2. Show
We outlined a flawed procedure for finding the most likely state sequence, given an observation sequence. The procedure involves finding the most likely state at each time step, using smoothing, and returning the sequence composed of these slates. Show that, for some temporal probability models and
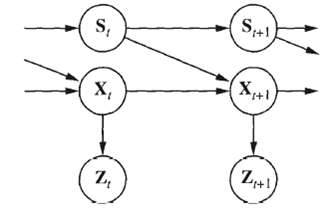
Often, we wish to monitor a Continuous-state system whose behavior switches unpredictably among a set of k distinct ?modes.? For example, an aircraft trying to evade a missile can execute a series of distinct maneuvers that the missile may attempt to track. A Bayesian network representation of such
Complete the missing step in the derivation of Equation (15.17), the first update step for the one-dimensional Kalman filter.
Let us examine the behavior of the variance update in Equation (15.1).a. Plot the value of σ2t as a function of t, given various values for σ2x and σ2z.b. Show that the update has a fixed point u σ2 such that σ2t →, σ2 as t →∞ and calculate the value of σ2c. Give a qualitative
Show how to represent an HMM as a recursive relational probabilistic model, as suggested in Section 14.6.
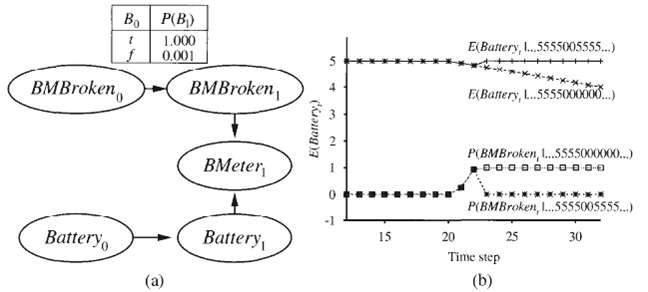
In this exercise, we analyze in more detail the persistent-failure model for the battery sensor in Figure (a). a. Figure (b) stops at t = 32. Describe qualitatively what should happen as t ? ? if the sensor continues to read 0. b. Suppose that the external temperature affects the battery sensor in
Consider applying the variable elimination algorithm to the umbrella DBN unrolled for three slices, where the query is P( R3│U1,U2,U3), Show that the complexity of the algorithm—the size of the largest factor—is the same, regardless of whether the rain variables are eliminated in forward or
The model of “tomato” in Figure allows for a coarticulation on the first vowel by giving two possible phones. An alternative approach is to use a tri-phone model in which the [ow (t, m)] phone automatically includes the change in vowel sound. Draw a complete tri-phone model for “tomato,”
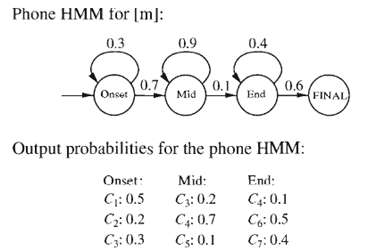
Calculate the most probable path through the HMM in Figure for the output sequence [C1, C2, C3, C4, C4, C6, and C 7]. Also give itsprohahi1ity
Tickets to a lottery cost $1. There are two possible prizes: a $10 payoff with probability 1/50, and a $1,000,000 payoff with probability 1/2,000,000. What is the expected monetary value of a lottery ticket? When (if ever) is it rational to buy a ticket? Be precise—show an equation involving
In 1738, J. Bernoulli investigated the St. Petersburg paradox, which works as follows. You have the opportunity to play a game in which a fair coin is tossed repeatedly until it conies up heads. If the first heads appears on the n.th toss, you win 2n dollars.a. Show that the expected monetary value
Assess your own utility for different incremental amounts of money by running a series of preference tests between some definite amount M1 and a lottery [p, M2; (1—p), 0]. Choose different values of M1 and M2 vary p until you are in different between the two choices. Plot the resulting utility
Write a computer program to automate the process in Exercise 16.4. Try your program out on several people of different net worth and political outlook. Comment on the consistency of your results, both for an individual and across individuals.
How much is a micro-mort worth to you? Devise a protocol to determine this. Ask questions based both on paying to avoid risk and being paid to accept risk.
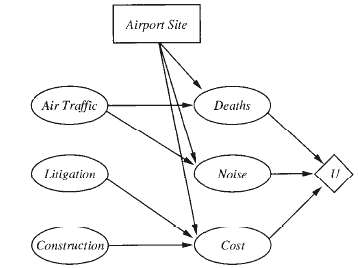
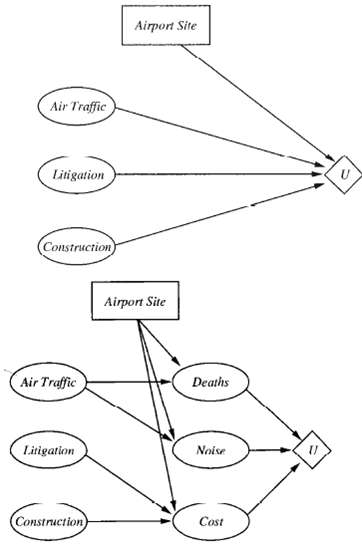
This exercise completes the analysis of the airport-sitting problem in Figure. a. Provide reasonable variable domains, probabilities, and utilities for the network, assuming that there are three possible sites. b. Solve the decision problem. c. What happens if changes in technology mean that each
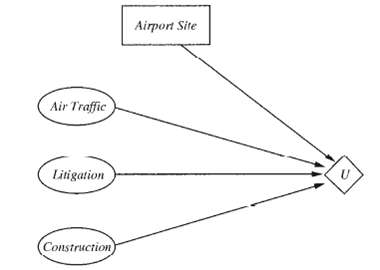
Repeat Exercise 16.8, using the action-utility representation shown inFigure.
For either of the airport-sitting diagrams from Exercises 16.8 and 16.9, to which conditional probability table entry is the utility most sensitive, given the availableevidence?
(Adapted from Pearl (1988)) A used-car buyer can decide to carry out various tests with various costs (e.g., kick the tires, take the car to a qualified mechanic) and then, depending on the outcome of the tests, decide which car to buy. We will assume that the buyer is deciding whether to buy car
Prove that the value of information is nonnegative and order-independent, as stated in Section 16.6. Explain how it is that one can make a worse decision after receiving information than one would have made before receiving it.
Modify and extend the Bayesian network code in the code repository to provide for creation and evaluation of decision networks and the calculation of information value.
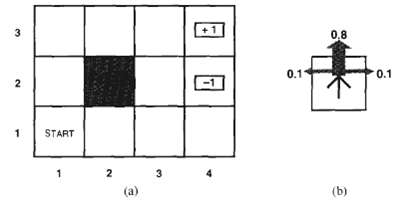
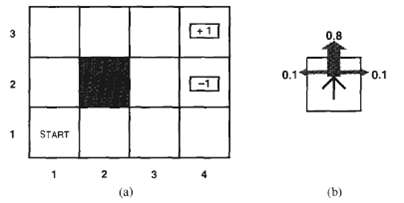
For the 4 x 3 world shown in Figure, calculate which squares can he reached from (1, 1) by the action sequence (Up, Up, Right, Right, Right and with what probabilities. Explain how this computation is related to the task of projecting a hidden Markovmodel.
Suppose that we define the utility of a state sequence to be the maximum reward obtained in any state in the sequence. Show that this utility function does not result in stationary preferences between state sequences. Is it still possible to define a utility function on states such that MEU
Can any finite search problem be translated exactly into a Markov decision problem such that an optimal solution of the latter is also an optimal solution of the former? If so, explain precisely how to translate the problem and how to translate the solution back; if not, explain precisely why not
Consider an undiscounted MDP having three states, (1, 2, 3), with rewards —1, —2, 0 respectively. State 3 is a terminal stale. In states I and 2 there are two possible actions: a and b. The transition model is as follows:• In state 1, action a moves the agent to state 2 with probability 0.8
Sometimes MDPs are formulated with a reward function R(s, a) that depends on the action taken or a reward function R (s, a, s’) that also depends on the outcome state.a. Write the Bellman equations for these formulations.b. Show how an MDP with reward function R (s. a. s’) can be transformed
Consider the 4 x 3 world shown in Figure. a. Implement an environment simulator for this environment, such that the specific geography of the environment is easily altered. Some code for doing this is already in the online code repository. b. Create an agent that uses policy iteration, and measure
In this exercise we will consider two-player MDPs that correspond to zero-sum, turn- taking games like those in Chapter 6. Let the players he A and B, and let R (s) be the reward for player A in s. (The reward for B is always equal and opposite.)a. Let UA (s) be the utility of state s when it is
Show that dominant strategy equilibrium is Nash equilibrium, hut not vice versa.
In the children’s game of rock-paper-scissors each player reveals at the same time a choice of rock, paper, or scissors. Paper wraps rock, rock blunts scissors, and scissors cut paper. In the extended version rock—paper—scissors—fire—water, fire beats rock, paper and scissors; rock, paper
Solve the game of three-finger Morra.
Prior to 1999, teams in the National Hockey League received 2 points for a win, 1 for a tie, and 0 for a loss. Is this a constant-sum game? In 1999, the rules were amended so that a team receives 1 point for a loss in overtime. The winning team still gets 2 points. 1-low does this modification
The following payoff matrix, from Blinder (1983) by way of Bernstein (1996), shows a game between politicians and the Federal Reserve. Politicians can expand or contract fiscal policy, while the Fed can expand or contract monetary policy. (And of course either side can choose to do nothing.) Each
Consider the problem faced by an infant learning to speak and understand a language. Explain how this process fits into the general learning model, identifying each of the components of the model as appropriate.
Repeat Exercise 18.1 for the case of learning to play tennis (or some other sport with which you are familiar) is this supervised learning or reinforcement learning?
Draw a decision tree for the problem of deciding whether to move forward at a road intersection, given that the light has just turned green.
We never test the same attribute twice along one path in a decision tree. Why not?
Suppose we generate a training set from a decision tree and then apply decision-tree learning to that training set. Is it the case that the learning algorithm will eventually return the correct tree as the training set size goes to infinity? Why or why not’?
A good straw man” learning algorithm is as follows: create a table Out of all the training examples identify which output occurs most often among the training examples; call it d. Then when given an input that is not in the table, just return d. For inputs that are in the table, return the output
Suppose you are running a learning experiment on a new algorithm. You have a data set consisting of 2 examples of each of two classes. Yon plan to use leave-one-nut cross-validation. As a baseline, you run your experimental setup on a simple majority classifier. (A majority classifier is given a
In the recursive construction of decision trees, it sometimes happens that a mixed set of positive and negative examples remains at a leaf node, even after all the attributes have been used. Suppose that we have p positive examples and r negative examples.a. Show that the solution used by
Suppose that a learning algorithm is trying to find a consistent hypothesis when the classifications of examples are actually random. There are u Boolean attributes, and examples are drawn uniformly from the set of 2n possible examples. Calculate the number of examples required before the
Suppose that an attribute splits the set of examples E into subsets E i and that each subset has p, positive examples and n negative examples. Show that the attribute has strictly positive information gain unless the ratio pi/ (p i + n i) is the same for all i.
In the chapter we noted that attributes with many different possible values can cause problems with the gain measure. Such attributes tend to split the examples into numerous small classes or even singleton classes, thereby appearing to be highly relevant according to the gain measure. The gain
This exercise concerns the expressiveness of decision lists (Section 18.5).a. Show that decision lists can represent any Boolean function, if the size of the tests is not limited.b. Show that if the tests can contain at most k literals each, then decision lists can represent any function that can
Show, by translating into conjunctive normal form and applying resolution, that the conclusion drawn concerning Brazilians is sound.
For each of the following determinations write down the logical representation and explain why the determination is true (if it is):a. Zip code determines the state (U.S.).b. Design and denomination determine the mass of a coin.c. For a given program, input determines output.d. Climate, food
Would a probabilistic version of determinations be useful? Suggest a definition.
Fill in the missing values for the clauses C1 or C2 (or both) in the following sets of clauses, given that C is the re solvent of C1 and C2:a. C = True → P (A, B), C1 = P (x, y) → Q(x, y), C2 =??b. C = True → P (A, B), C1 = ?? C2 =??.c. C = P(x, y) → P(x, f(y)), C1 = ?? C2 =??.If there is
Suppose one writes a logic program that carries out a resolution inference step. That is, let Resolve (c1, c2, c) succeed if c is the result of resolving cl and c2. Normally Resolve would be used as part of a theorem prover by calling it with c1 and c2 instantiated to particular clauses, thereby
Suppose that FOIL is considering adding a literal to a clause using a binary predicate P and those previous literals (including the head of the clause) contain five different variables.a. How many functionally different literals can be generated? Two literals are functionally identical if they
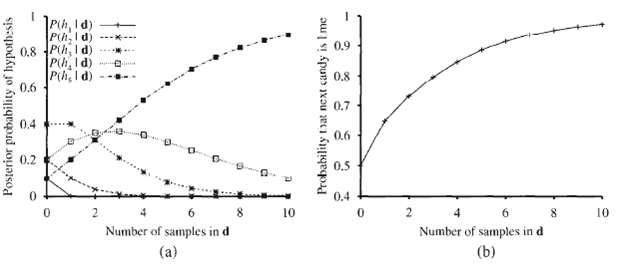
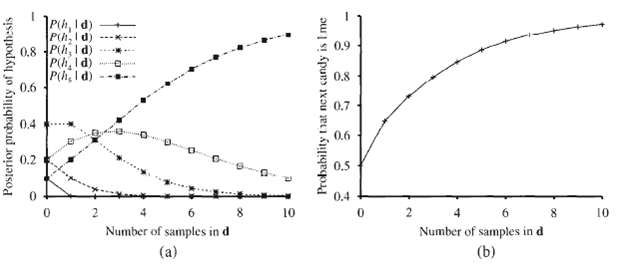
The data used for Figure can be viewed as being generated by h5. For each of the other four hypotheses, generate a data set of length 100 and plot the corresponding graphs for P (hi?d1... dm) and P (D m + 1 = lime?d1. . . dm). Comment on your results.
Repeat Exercise 20.1, this time plotting the values of P (D m+1 = lime│h MAP) and P (D m+1 = lime│hML).
Suppose that Ann’s utilities for cherry and lime candies are c A and l A, whereas Bob’s utilities are c B and l B. (But once Ann has un-wrapped a piece of candy. Bob won’t buy it.) Presumably, if Bob likes lime candies much more than Ann, it would be wise to sell for Ann to sell her bag of
Two statisticians go to the doctor and are both given the same prognosis: A 40% chance that the problem is the deadly disease A. and a 60% chance of the fatal disease B. Fortunately, there are anti-A and anti-B drugs that are inexpensive, 100% effective, and free of side-effects. The statisticians
Explain how to apply the boosting method naive Bayes learning. Test the performance of the resulting algorithm on the restaurant learning problem.
Consider m data points (x j, y j), where the y j s are generated from the x j s according to the linear Gaussian model in Equation (20.5). Find the values of θ1, θ2 and σ that maximize the conditional log likelihood of the data.
Consider the noisy-OR model for fever described in Section 14.3. Explain how to apply maximum-likelihood learning to fit the parameters of such a model to a set of complete data.
This exercise investigates properties of the Beta distribution defined in Equation (20.6).a. Dy integrating over the range [0, 1], show that the normalization constant for the distribution beta [a, b] is given by α = Г (x + 1) = Г (a + b)/ Г (a) Г (b) where Г (x) is the Gamma function,
Consider an arbitrary Bayesian network, a complete data set for that network, and the likelihood for the data set according to the network. Give a simple proof that the likelihood of the data cannot decrease if we add a new link to the network and re-compute the maximum likelihood parameter values.
Consider the application of EM to learn the parameters for the network in Figure (a), given the true parameters in Equation (20.7). a. Explain why the EM algorithm would not work if there were just two attributes in the model rather than three. b. Show the calculations for the first iteration of EM
Construct a support vector machine that computes the XOR function. It will be convenient to use values of 1 and —1 instead of I and 0 for the inputs and for the outputs. So an example looks like ([—1. ii, 1) or ([—1, —1], —1). It is typical to map an input x into a space consisting of
A simple perceptron cannot represent XOR (or, generally, the parity function of its inputs). Describe what happens to the weights of a four-input, step-function perceptron, and beginning with all weights set to 0.1, as examples of the parity function arrive.
Recall from that there are 22n distinct Boolean functions of n inputs. How many of these are representable by a threshold perceptron?
Consider the following set of examples, each with six inputs and one target output: a. Run the perception learning rule on these data and show the final weights. b. Run the decision tree learning rule, and show the resulting decision tree. c. Comment on yourresults.
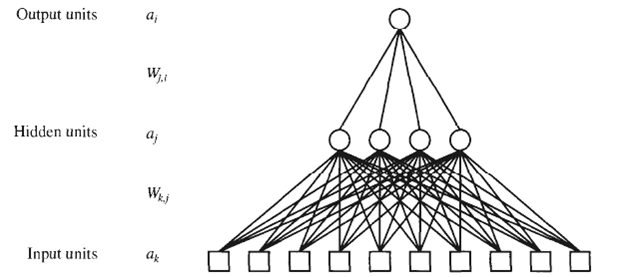
Starting from Equation (20.13), show that δ I, / δ W j = Err x a j.
Suppose you had a neural network with linear activation functions. That is, for each unit the output is some constant times the weighted sum of the inputs.a. Assume that the network has one hidden layer. For a given assignment to the weights W, write down equations for the value of the units in the
Implement a data structure for layered, feed-forward neural networks, remembering to provide the information needed for both forward evaluation and backward propagation. Using this data structure, write a function NEURAL-NETWORK-OUTPUT that takes an example and a network and computes the
Suppose that a training set contains only a single example, repeated 100 times. In 80 of the 100 cases, the single output value is I; in the other 20, it is 0. What will a back- propagation network predict for this example, assuming that it has been trained and reaches a global optimum?
The network in Figure has four hidden nodes. This number was chosen somewhat arbitrarily. Run systematic experiments to measure the learning curves for networks with different numbers of hidden nodes. What is the optimal number? Would it be possible to use a cross-validation method to find the best
Consider the problem of separating N data points into positive and negative examples using a linear separator. Clearly, this can always be done for N = 2 points on a line of dimension d = 1, regardless of how the points are labelled or where they are located (unless the points are in the same
Defined a proper policy for an MDP as one that is guaranteed to reach a terminal state, show that it is possible for a passive ADP agent to learn a transition model for which its policy π is improper even if π is proper for the true MDP with such models, the value determination step may fail if
Starting with the passive ADP agent modify it to use an approximate ADP algorithm us discussed in the text. Do this in two steps:a. Implement a priority queue for adjustments to the utility estimates. Whenever a state is adjusted, all of its predecessors also become candidates for adjustment and
The direct utility estimation method in Section 21.2 uses distinguished terminal states to indicate the end of a trial. How could it be modified for environments with discounted rewards and no terminal states?
How can the value determination algorithm be used to calculate the expected loss experienced by an agent using a given set of utility estimates U and an estimated model M, compared with an agent using correct values?
Adapt the vacuum world for reinforcement learning by including rewards for picking up each piece of dirt and for getting home and switching off. Make the world accessible by providing suitable percepts. Now experiment with different reinforcement learning agents. Is function approximation necessary
Showing 200 - 300
of 976
1
2
3
4
5
6
7
8
9
10
Step by Step Answers


![(a) Word model with dialect variation: (eyl 0.5 1.0 1.0 1.0 (ow] 1.0 (t) [m] [ow] (1) 1.0 (aa] (b) Word model with coart](https://dsd5zvtm8ll6.cloudfront.net/si.question.images/images/question_images/1548/9/1/1/7625c5284922872d1548911763509.jpg)