New Semester
Started
Get
50% OFF
Study Help!
--h --m --s
Claim Now
Question Answers
Textbooks
Find textbooks, questions and answers
Oops, something went wrong!
Change your search query and then try again
S
Books
FREE
Study Help
Expert Questions
Accounting
General Management
Mathematics
Finance
Organizational Behaviour
Law
Physics
Operating System
Management Leadership
Sociology
Programming
Marketing
Database
Computer Network
Economics
Textbooks Solutions
Accounting
Managerial Accounting
Management Leadership
Cost Accounting
Statistics
Business Law
Corporate Finance
Finance
Economics
Auditing
Tutors
Online Tutors
Find a Tutor
Hire a Tutor
Become a Tutor
AI Tutor
AI Study Planner
NEW
Sell Books
Search
Search
Sign In
Register
study help
computer sciences
databases
Database System Concepts 4th Edition Henry F. Korth, S. Sudarshan - Solutions
Given the three goals of relational-database design, is there any reason to design a database schema that is in 2NF, but is in no higher-order normal form?
Give an example of a relation schema R and a set of dependencies such that R is in BCNF, but is not in 4NF.
Explain why 4NF is a normal form more desirable than BCNF.
Explain how dangling tuplesmay arise. Explain problems that theymay cause.
For each of the following application areas, explain why a relational database system would be inadequate. List all specific system components that would need to be modified.a. Computer-aided designb. Multimedia databases
How does the concept of an object in the object-oriented model differ from the concept of an entity in the entity-relationship model?
A car-rental company maintains a vehicle database for all vehicles in its current fleet. For all vehicles, it includes the vehicle identification number, license number, manufacturer,model, date of purchase, and color. Special data are included for certain types of vehicles:• Trucks: cargo
Explain why ambiguity potentially exists with multiple inheritances. Illustrate your explanation with an example.
Explain how the concept of object identity in the object-oriented model differs from the concept of tuple equality in the relational model.
Explain the distinction in meaning between edges in a DAG representing inheritance and a DAG representing object containment.
Why do persistent programming languages allow transient objects? Might it be simpler to use only persistent objects, with unneeded objects deleted at the end of an execution? Explain your answer.
Using ODMG C++a. Give schema definitions corresponding to the relational schema shown in Figure, using references to express foreign-key relationships.b. Write programs to compute each of the queries in Exercise 3.10.
Using ODMG C++, give schema definitions corresponding to the E-R diagram in Figure, using references to implement relationships.
Explain, using an example, how to represent a ternary relationship in an objectoriented data model such as ODMG C++.
Explain how a persistent pointer is implemented. Contrast this implementation with that of pointers as they exist in general-purpose languages, such as C or Pascal.
If an object is created without any references to it, howcan that object be deleted?
Consider a system that provides persistent objects. Is such a system necessarily a database system? Explain your answer.
Consider the database schema Emp = (ename, set of(Children), setof(Skills)) Children = (name, Birthday) Birthday = (day, month, year) Skills = (type, set of(Exams)) Exams = (year, city) Assume that attributes of type set of(Children), set of(Skills), and setof(Exams), have attribute names
Redesign the database of Exercise 9.1 into first normal form and fourth normal form. List any functional or multivalued dependencies that you assume. Also list all referential-integrity constraints that should be present in the first- and fourth-normal-form schemas.
Consider the schemas for the table people, and the table’s students and teachers, which were created under people, in Section 9.3.Give a relational schema in third normal form that represents the same information. Recall the constraints on subtables, and give all constraints that must be imposed
A car-rental company maintains a vehicle database for all vehicles in its current fleet. For all vehicles, it includes the vehicle identification number, license number, manufacturer, model, date of purchase, and color. Special data are included for certain types of vehicles:• Trucks: cargo
Explain the distinction between a type x and a reference type ref(x). Underwhat circumstances would you choose to use a reference type?
Consider the E-R diagramin Figure, which contains composite, multivalued and derived attributes. a. Give an SQL: 1999 schema definition corresponding to the E-R diagram. Use an array to represent the multivalued attribute, and appropriate SQL: 1999 constructs to represent the other attribute
Give an SQL: 1999 schema definition of the E-R diagram in Figure below, which contains specializations.
Consider the relational schema shown in Figure below. a. Give a schema definition in SQL: 1999 corresponding to the relational schema, but using references to express foreign-key relationships. b. Write each of the queries in Exercise 3.10 on the above schema, using SQL:1999.
Consider an employee database with two relations employee (employee-name, street, and city) works (employee-name, company-name, salary) where the primary keys are underlined. Write a query to find companies whose employees earn a higher salary, on average, than the average salary at First Bank
Rewrite the query in Section 9.6.1 that returns the titles of all books that have more than one author, using the with clause in place of the function.
Compare the use of embedded SQL with the use in SQL of functions defined in a general-purpose programming language. Under what circumstances would you use each of these features?
Suppose that you have been hired as a consultant to choose a database system for your client’s application. For each of the following applications, state what type of database system (relational, persistent-programming-language–based OODB, object relational; do not specify a commercial product)
Give an alternative representation of bank information containing the same data as shown in figure but using attributes instead of subelements. Also give the DTD for this representation.<bank> <account><account-number> A-101 </account-number><branch-name> Downtown
Show, by giving a DTD, how to represent the books nested-relation from Section 9.1, using XML
Give the DTD for an XML representation of the following nested-relational schema Emp = (ename, ChildrenSet setof (Children), SkillsSet setof (Skills))Children = (name, Birthday)Birthday = (day, month, year)Skills = (type, ExamsSet setof (Exams))Exams = (year, city)
Write the following queries in XQuery, assuming the DTD from exercise.a. Find the names of all employees who have a child who has a birthday in March.b. Find those employees who took an examination for the skill type “typing” in the city “Dayton”.c. List all skill types in Emp.
Write queries in XSLT and in XPath on the DTD of Exercise 10.3 to list all skill types in Emp.Emp = (ename, ChildrenSet setof (Children), SkillsSet setof (Skills))Children = (name, Birthday)Birthday = (day, month, year)Skills = (type, ExamsSet setof (Exams))Exams = (year, city)
Write a query in XQuery on the XML representation as shown below to find the total balance, across all accounts, at each branch. <bank><account><account-number> A-101 </account-number><branch-name> Downtown </branch-name><balance> 500
Write a query in XQuery on the XML representation as shown below to compute the left outer join of customer elements with account elements. <!DOCTYPE bank-2 [<!ELEMENT account ( branch, balance )><!ATTLIST accountaccount-number ID #REQUIREDowners IDREFS #REQUIRED ><!ELEMENT
Give a query in XQuery to flip the nesting of data as shown below. That is, at the outermost level of nesting the outputmust have elements corresponding to authors, and each such element must have nested within it items corresponding to all the books written by the author.EMP = (ename, setof
Write queries in XSLT and XQuery to output customer elements with associated account elements nested within the customer elements, given the bank information representation using ID and IDREFS as shown below.<!DOCTYPE bibliography [<!ELEMENT book (title, author+, year, publisher,
Consider as shown below, and suppose that authors could also appear as top level elements. What change would have to be done to the relational schema?<!DOCTYPE bibliography [<!ELEMENT book (title, author+, year, publisher, place?)><!ELEMENT article (title, author+, journal, year,
Consider as shown below, and suppose that authors could also appear as top level elements. What change would have to be done to the relational schema?<!DOCTYPE bibliography [<!ELEMENT book (title, author+, year, publisher, place?)><!ELEMENT article (title, author+, journal, year,
Write queries in XQuery on the bibliography DTD fragment as shown below to do the following.a. Find all authors who have authored a book and an article in the same year.b. Display books and articles sorted by year.c. Display books with more than one author.<!DOCTYPE bibliography [<!ELEMENT
Consider the following recursive DTD.<!DOCTYPE parts [<!ELEMENT part (name, subpartinfo*)><!ELEMENT subpartinfo (part, quantity)><!ELEMENT name ( #PCDATA )><!ELEMENT quantity ( #PCDATA )>] >a. Give a small example of data corresponding to the above DTD.b. Show how to
List the physical storage media available on the computers you use routinely. Give the speed with which data can be accessed on each medium.
How does the remapping of bad sectors by disk controllers affect data-retrieval rates?
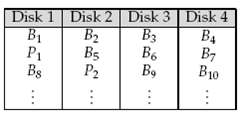
Consider the following data and parity-block arrangement on four disks: The Bi?s represent data blocks; the Pi?s represent parity blocks. Parity block Pi is the parity block for data blocks B4i?3?to B4i. What, if any, problem might this arrangement present?
A power failure that occurs while a disk block is being written could result in the block being only partially written. Assume that partially written blocks can be detected. An atomic block write is one where either the disk block is fully written or nothing is written (i.e., there are no partial
RAID systems typically allow you to replace failed disks without stopping access to the system. Thus, the data in the failed disk must be rebuilt and written to the replacement disk while the system is in operation. With which of the RAID levels is the amount of interference between the rebuild and
Give an example of a relational-algebra expression and a query-processing strategy in each of the following situations:a. MRU is preferable to LRU.b. LRU is preferable to MRU.
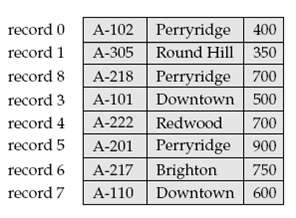
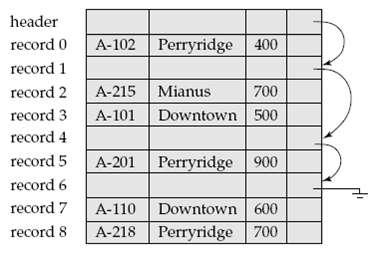
Consider the deletion of record 5 from the file as shown below compare the relative merits of the following techniques for implementing the deletion: a. Move record 6 to the space occupied by record 5, and move record 7 to the space occupied by record 6. b. Move record 7 to the space occupied by
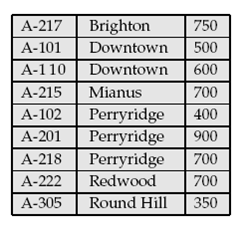
Show the structure of the file as shown below after each of the following steps: a. Insert (Brighton, A-323, 1600). b. Delete record 2. c. Insert (Brighton, A-626, 2000).
Give an example of a database application in which the reserved-spacemethod of representing variable-length records is preferable to the pointer method. Explain your answer.
Give an example of a database application in which the pointer method of representing variable-length records is preferable to the reserved-space method. Explain your answer.
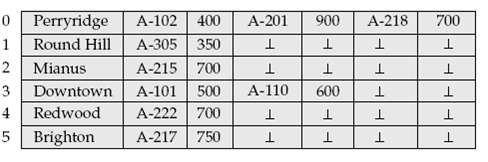
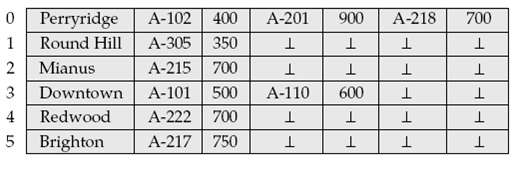
Show the structure of the file of Figure after each of the following steps: a. Insert (Mianus, A-101, 2800). b. Insert (Brighton, A-323, 1600). c. Delete (Perryridge, A-102,400).
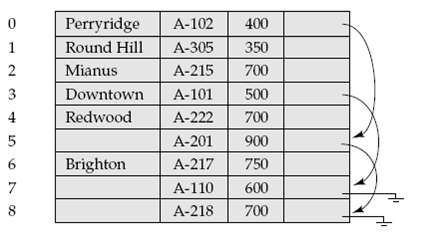
What happens if you attempt to insert the record (Perryridge, A-929, 3000) into the file of as shownbelow?
Show the structure of the file of Figure after each of the following steps: a. Insert (Mianus, A-101, 2800). b. Insert (Brighton, A-323, 1600). c. Delete (Perryridge, A-102,400).
Explain why the allocation of records to blocks affects database-system performance significantly.
If possible, determine the buffer-management strategy used by the operating system running on your local computer system, and what mechanisms it provides to control replacement of pages. Discuss how the control on replacement that it provides would be useful for the implementation of database
In the sequential file organization, why is an overflow block used even if there is, at the moment, only one overflow record?
List two advantages and two disadvantages of each of the following strategies for storing a relational database:a. Store each relation in one file.b. Store multiple relations (perhaps even the entire database) in one file.
Consider a relational database with two relations: course (course-name, room instructor) enrollment (course-name, student-name, grade) Define instances of these relations for three courses, each of which enrolls five students. Give a file structure of these relations that uses clustering.
Consider the following bitmap technique for tracking free space in a file. For each block in the file, two bits are maintained in the bitmap. If the block is between 0 and 30 percent full the bits are 00, between 30 and 60 percent the bits are 01, between 60 and 90 percent the bits are 10, and
Give a normalized version of the Index-meta data relation, and explain why using the normalized version would result in worse performance.
Explain why a physical OID must contain more information than a pointer to a physical storage location.
If physical OIDs are used, an object can be relocated by keeping a forwarding pointer to its new location. In case an object gets forwarded multiple times, what would be the effect on retrieval speed? Suggest a technique to avoid multiple accesses in such a case.
Define the term dangling pointer. Describe how the unique-id scheme helps in detecting dangling pointers in an object-oriented database.
Consider the example on page 435, which shows that there is no need for deswizzling if hardware swizzling is used. Explain why, in that example, it is safe to change the short identifier of page 679.34278 from 2395 to 5001. Can some other page already have short identifier 5001? If it could, how
When is it preferable to use a dense index rather than a sparse index? Explain your answer.
Since indices speed query processing, why might they not be kept on several search keys? List as many reasons as possible.
When is it preferable to use a dense index rather than a sparse index? Explain your answer. Discuss.
Since indices speed query processing, why might they not be kept on several search keys? List as many reasons as possible. Discuss.
What is the difference between a primary index and a secondary index?
Is it possible in general to have two primary indices on the same relation for different search keys? Explain your answer.
Construct a B+-tree for the following set of key values: (2, 3, 5, 7, 11, 17, 19, 23, 29, 31) Assume that the tree is initially empty and values are added in ascending order. Construct B+-trees for the cases where the number of pointers that will fit in one node is as follows:a. Fourb. Sixc. Eight
For each B+-tree as shown below show the steps involved in the following queries:a. Find records with a search-key value of 11.b. Find records with a search-key value between 7 and 17, inclusive.(2, 3, 5, 7, 11, 17, 19, 23, 29, 31)
For each B+-tree as shown below show the form of the tree after each of the following series of operations:a. Insert 9.b. Insert 10.c. Insert 8.d. Delete 23.e. Delete 19.Construct a B+-tree for the following set of key values: (2, 3, 5, 7, 11, 17, 19, 23, 29, 31) Assume that the tree is initially
Consider the modified redistribution scheme for B+-trees described in page 463. What is the expected height of the tree as a function of n?
Repeat as shown below for a B-tree.Construct a B+-tree for the following set of key values: (2, 3, 5, 7, 11, 17, 19, 23, 29, 31) Assume that the tree is initially empty and values are added in ascending order. Construct B+-trees for the cases where the number of pointers that will fit in one node
Explain the distinction between closed and open hashing. Discuss the relative merits of each technique in database applications.
What are the causes of bucket overflow in a hash file organization? What can be done to reduce the occurrence of bucket overflows?
Suppose that we are using extendable hashing on a file that contains records with the following search-key values: 2, 3, 5, 7, 11, 17, 19, 23, 29, 31 Show the extendable hash structure for this file if the hash function is h(x) = x mod 8 and buckets can hold three records.
Show how the extendable hash structure of Exercise changes as the result of each of the following steps:a. Delete 11.b. Delete 31.c. Insert 1.d. Insert 15.Suppose that we are using extendable hashing on a file that contains records with the following search-key values: 2, 3, 5, 7, 11, 17, 19, 23,
Give pseudocode for deletion of entries from an extendable hash structure, including details of when and how to coalesce buckets. Do not bother about reducing the size of the bucket address table.
Suggest an efficient way to test if the bucket address table in extendable hashing can be reduced in size, by storing an extra count with the bucket address table. Give details of how the count should be maintained when buckets are split, coalesced or deleted. (Note: Reducing the size of the bucket
Why is a hash structure not the best choice for a search key on which range queries are likely?
Consider a grid file in which we wish to avoid overflow buckets for performance reasons. In cases where an overflow bucket would be needed, we instead reorganize the grid file. Present an algorithm for such a reorganization.
Consider the account relation as shown below. a. Construct a bitmap index on the attributes branch-name and balance, dividing balance values into 4 ranges: below 250, 250 to below 500, 500 to below 750, and 750 and above. b. Consider a query that requests all accounts in Downtown with a balance of
Show how to compute existence bitmaps from other bitmaps. Make sure that your technique works even in the presence of null values, by using a bitmap for the value null.
How does data encryption affect index schemes? In particular, how might it affect schemes that attempt to store data in sorted order?
Why is it not desirable to force users to make an explicit choice of a queryprocessing strategy? Are there cases in which it is desirable for users to be aware of the costs of competing query-processing strategies? Explain your answer.
Consider the following SQL query for our bank database select T.branch-name from branch T, branch S where T.assets > S.assets and S.branch-city = “Brooklyn” Write an efficient relational-algebra expression that is equivalent to this query. Justify your choice.
What are the advantages and disadvantages of hash indices relative to B+-tree indices? How might the type of index available influence the choice of a query processing strategy?
Assume (for simplicity in this exercise) that only one tuple fits in a block and memory holds at most 3 page frames. Show the runs created on each pass of the sort-merge algorithm, when applied to sort the following tuples on the first attribute: (kangaroo, 17), (wallaby, 21), (emu, 1), (wombat,
Let relations r1 (A, B, C) and r2 (C, D, E) have the following properties: r1 has 20,000 tuples, r2 has 45,000 tuples, 25 tuples of r1 fit on one block, and 30 tuples of r2 fit on one block. Estimate the number of block accesses required, using each of the following join strategies for r1 Θ r2:a.
Design a variant of the hybrid merge–join algorithm for the case where both relations are not physically sorted, but both have a sorted secondary index on the join attributes.
The indexed nested-loop join algorithm described in Section 13.5.3 can be inefficient if the index is a secondary index, and there are multiple tuples with the same value for the join attributes. Why is it inefficient? Describe a way, using sorting, to reduce the cost of retrieving tuples of the
Estimate the number of block accesses required by your solution to Exercise for r1 Θ r2, where r1 and r2 are as defined in Exercise.
The indexed nested-loop join algorithm described in Section 13.5.3 can be inefficient if the index is a secondary index, and there are multiple tuples with the same value for the join attributes. Why is it inefficient? Describe a way, using sorting, to reduce the cost of retrieving tuples of the
Suppose that a B + - tree index on branch-city is available on relation branch, and that no other index is available. List different ways to handle the following selections that involve negation?a. σ ¬ ((branch-city <“Brooklyn”)(branch)b. σ ¬ (branch-city=“Brooklyn”)(branch)c. σ ¬
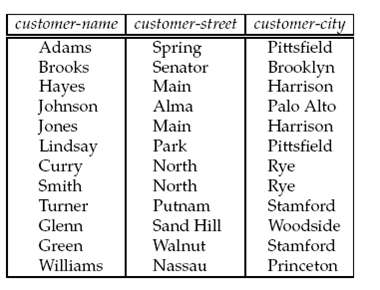
The hash join algorithm as described in Section computes the natural join of two relations. Describe how to extend the hash join algorithm to compute the natural left outer join, the natural right outer join and the natural full outer join. Try out your algorithm on the customer and
Write pseudocode for an iterator that implements indexed nested-loop join, where the outer relation is pipelined. Use the standard iterator functions in your pseudocode. Show what state information the iterator must maintain between calls.
Showing 200 - 300
of 3228
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
Last
Step by Step Answers