New Semester
Started
Get
50% OFF
Study Help!
--h --m --s
Claim Now
Question Answers
Textbooks
Find textbooks, questions and answers
Oops, something went wrong!
Change your search query and then try again
S
Books
FREE
Study Help
Expert Questions
Accounting
General Management
Mathematics
Finance
Organizational Behaviour
Law
Physics
Operating System
Management Leadership
Sociology
Programming
Marketing
Database
Computer Network
Economics
Textbooks Solutions
Accounting
Managerial Accounting
Management Leadership
Cost Accounting
Statistics
Business Law
Corporate Finance
Finance
Economics
Auditing
Tutors
Online Tutors
Find a Tutor
Hire a Tutor
Become a Tutor
AI Tutor
AI Study Planner
NEW
Sell Books
Search
Search
Sign In
Register
study help
computer sciences
databases
Database System Concepts 4th Edition Henry F. Korth, S. Sudarshan - Solutions
Design sorting based and hashing algorithms for computing the division operation.
Clustering indices may allow faster access to data than a nonclustering index affords. When must we create a nonclustering index, despite the advantages of a clustering index? Explain your answer.
Consider the relations r1 (A, B, C), r2 (C, D, E), and r3 (E, F), with primary keys A, C, and E, respectively. Assume that r1 has 1000 tuples, r2 has 1500 tuples, and r3 has 750 tuples. Estimate the size of r1 Θ r2 Θ r3, and give an efficient strategy for computing the join.
Consider the relations r1 (A, B, C), r2 (C, D, E), and r3 (E, F) of Exercise. Assume that there are no primary keys, except the entire schema. Let V (C, r1) be 900, V (C, r2) be 1100, V (E, r2) be 50, and V (E, r3) be 100. Assume that r1 has 1000 tuples, r2 has 1500 tuples, and r3 has 750 tuples.
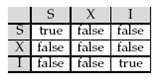
Suppose that a B+-tree index on branch-city is available on relation branch, and that no other index is available. What would be the best way to handle the following selections that involve negation?a. σ ¬ (branch-city<“Brooklyn”)(branch)b. σ ¬ (branch-city=“Brooklyn”)(branch)c. σ
Suppose that a B+-tree index on (branch-name, branch-city) is available on relation branch. What would be the best way to handle the following selection?σ (branch-city<“Brooklyn”) ∧ (assets<5000)∧(branch-name=“Downtown”)(branch)
Show that the following equivalences hold. Explain how you can apply then to improve the efficiency of certain queries:a. E1 Θθ (E2 − E3) = (E1 Θθ E2 − E1 Θθ E3).b. σθ (AGF (E)) = AGF (σθ (E)), where θ uses only attributes from A.c. σθ (E1 Θ E2) = σθ(E1) Θ E2 where θ uses
Show how to derive the following equivalences by a sequence of transformations using the equivalence rules in Section 14.3.1.a. σθ1 ∧ θ2 ∧ θ3 (E) = σθ1 (σθ2 (σθ3 (E)))b. σθ1 ∧ θ2(E1 1θ3 E2) = σθ1 (E1 1θ3 (σθ2 (E2))), where θ2 involves only attributes from E2
For each of the following pairs of expressions, give instances of relations that show the expressions are not equivalent.a. ΠA(R − S) and Π A (R) – ΠA (S)b. σB < 4(AGmax(B)(R)) and AGmax(B)(σB<4(R))c. In the preceding expressions, if both occurrences of max were replaced by min would
SQL allows relations with duplicates.a. Define versions of the basic relational-algebra operations σ, Π, ×, Π, −, ∪, and ∩ that work on relationswith duplicates, in a way consistent with SQL.b. Check which of the equivalence rules 1 through 7.b hold for the multiset version of the
Show that, with n relations, there are (2(n − 1))! / (n−1)! Different join orders. If you wish, you can derive the formula for the number of complete binary trees with n nodes from the formula for the number of binary trees with n nodes. The number of binary trees with n nodes is 1/n+1 (2n n);
Show that the lowest-cost join order can be computed in time O(3n). Assume that you can store and look up information about a set of relations (such as the optimal join order for the set, and the cost of that join order) in constant time. (If you find this exercise difficult, at least show the
Show that, if only left-deep join trees are considered, as in the System R optimizer, the time taken to find themost efficient join order is around n2n.Assume that there is only one interesting sort order.
A set of equivalence rules is said to be complete if, whenever two expressions are equivalent, one can be derived from the other by a sequence of uses of the equivalence rules. Is the set of equivalence rules that we considered in Section 14.3.1 complete?
Decorrelation:a. Write a nested query on the relation account to find for each branch with name starting with “B”, all accounts with the maximum balance at the branch.b. Rewrite the preceding query, without using a nested subquery; in other words, decorrelate the query.c. Give a procedure
Describe how to incrementally maintain the results of the following operations, on both insertions and deletions.a. Union and set differenceb. Left outer join
Give an example of an expression defining a materialized view and two situations (sets of statistics for the input relations and the differentials) such that incremental view maintenance is better than recomputation in one situation and recomputation is better in the other situation.
List the ACID properties. Explain the usefulness of each.
Suppose that there is a database system that never fails. Is a recovery manager required for this system?
Consider a file system such as the one on your favorite operating system.a. What are the steps involved in creation and deletion of files, and in writing data to a file?b. Explain how the issues of atomicity and durability are relevant to the creation and deletion of files, and to writing data to
Database-system implementers have paid much more attention to the ACID properties than have file-system implementers. Why might this be the case?
During its execution, a transaction passes through several states, until it finally commits or aborts. List all possible sequences of states through which a transaction may pass. Explain why each state transition may occur.
Justify the following statement: Concurrent execution of transactions is more important when data must be fetched from (slow) disk or when transactions are long, and is less important when data is in memory and transactions are very short.
Explain the distinction between the terms serial schedule and serializable schedule.
Consider the following two transactions:T1: read (A); read (B); if A = 0then B: = B + 1; write (B).T2: read (B); read (A); if B = 0 then A: = A + 1; write (A).Let the consistency requirement be A = 0 ∨ B = 0, with A = B = 0 the initial values.a. Show that every serial execution involving these
Since every conflict-serializable schedule is view serializable, why do we emphasize conflict serializability rather than view serializability?
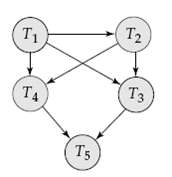
Consider the precedence graph of Figure is the corresponding schedule conflict serializable? Explain your answer.
What is a recoverable schedule? Why is recoverability of schedules desirable? Are there any circumstances under which it would be desirable to allow nonrecoverable schedules? Explain your answer.
What is a cascade less schedule? Why is cascadelessness of schedules desirable? Are there any circumstances under which it would be desirable to allow non-cascadeless schedules? Explain your answer.
Consider the following two transactions:T31: read (A); read (B);If A = 0 then B: = B + 1; write (B).T32: read (B); read (A);If B = 0 then A: = A + 1; write (A).Add lock and unlock instructions to transactions T31 and T32, so that they observe the two-phase locking protocol. Can the execution of
What benefit does strict two-phase locking provide? What disadvantages result?
What benefit does rigorous two-phase locking provide? How does it compare with other forms of two-phase locking?
Most implementations of database systems use strict two-phase locking. Suggest three reasons for the popularity of this protocol.
Consider a database organized in the form of a rooted tree. Suppose that we insert a dummy vertex between each pair of vertices. Show that, if we follow the tree protocol on the new tree, we get better concurrency than if we follow the tree protocol on the original tree
Show by example that there are schedules possible under the tree protocol that is not possible under the two-phase locking protocol, and vice versa.
Consider the following extension to the tree-locking protocol, which allows both shared and exclusive locks:• A transaction can be either a read-only transaction, in which case it can request only shared locks, or an update transaction, in which case it can request only exclusive locks.• Each
Consider the following graph-based locking protocol, which allows only exclusive lock modes, and which operates on data graphs that are in the form of a rooted directed acyclic graph.• A transaction can lock any vertex first.• To lock any other vertex, the transaction must be holding a lock on
Consider the following graph-based locking protocol that allows only exclusive lock modes, and that operates on data graphs that are in the form of a rooted directed acyclic graph.• A transaction can lock any vertex first.• To lock any other vertex, the transaction must have visited all the
Consider a variant of the tree protocol called the forest protocol. The database is organized as a forest of rooted trees. Each transaction Ti must follow the following rules:• The first lock in each tree may be on any data item.• The second, and all subsequent, locks in a tree may be requested
Locking is not done explicitly in persistent programming languages. Rather, objects (or the corresponding pages) must be locked when the objects are accessed. Most modern operating systems allow the user to set access protections (no access, read, writes) on pages, and memory access that violate
In timestamp ordering, W-timestamp (Q) denotes the largest timestamp of any transaction that executed write (Q) successfully. Suppose that, instead, we defined it to be the timestamp of the most recent transaction to execute write (Q) successfully.Would this change in wording make any difference?
When a transaction is rolled back under timestamp ordering, it is assigned a new timestamp. Why can it not simply keep its old timestamp?
In multiple-granularity locking, what is the difference between implicit and explicit locking?
Although SIX mode is useful in multiple-granularity locking, an exclusive and intend-shared (XIS) mode is of no use. Why is it useless?
Use of multiple-granularity locking may require more or fewer locks than an equivalent system with a single lock granularity. Provide examples of both situations, and compare the relative amount of concurrency allowed.
Consider the validation-based concurrency-control scheme of Section 16.3. Show that by choosing Validation (Ti), rather than Start (Ti), as the timestamp of transaction Ti, we can expect better response time provided that conflict rates among transactions are indeed low.
Show that there are schedules that are possible under the two-phase locking protocol, but are not possible under the timestamp protocol, and vice versa.
For each of the following protocols, describe aspects of practical applications that would lead you to suggest using the protocol, and aspects that would suggest not using the protocol:• Two-phase locking• Two-phase locking with multiple-granularity locking• The tree protocol• Timestamp
Under a modified version of the timestamp protocol, we require that a commit bit be tested to see whether a read request must wait. Explain how the commit bit can prevent cascading abort. Why is this test not necessary for write requests?
Under what conditions is it less expensive to avoid deadlock than to allow deadlocks to occur and then to detect them?
If deadlock is avoided by deadlock avoidance schemes, is starvation still possible? Explain your answer.
Explain the phantom phenomenon. Why may this phenomenon lead to an incorrect concurrent execution despite the use of the two-phase locking protocol?
Devise a timestamp-based protocol that avoids the phantom phenomenon.
Suppose that we use the tree protocol of Section 16.1.5 to manage concurrent access to a B+-tree. Since a split may occur on an insert that affects the root, it appears that an insert operation cannot release any locks until it has completed the entire operation. Under what circumstances is it
Explain the difference between the three storage types—volatile, nonvolatile, and stable—in terms of I/O cost.
Stable storage cannot be implemented.a. Explain why it cannot be.b. Explain how database systems deal with this problem.
Compare the deferred- and immediate-modification versions of the log-based recovery scheme in terms of ease of implementation and overhead cost.
Assume that immediate modification is used in a system. Show, by an example, how an inconsistent database state could result if log records for a transaction are not output to stable storage prior to data updated by the transaction being written to disk.
Explain the purpose of the checkpoint mechanism. How often should checkpoints be performed? How does the frequency of checkpoints affect• System performance when no failure occurs• The time it takes to recover from a system crash• The time it takes to recover from a disk crash
When the system recovers from a crash, it constructs an undo-list and a redo-list. Explainwhy log records for transactions on the undolist must be processed in reverse order, while those log records for transactions on the redo-list are processed in a forward direction.
Compare the shadow-paging recovery scheme with the log-based recovery schemes in terms of ease of implementation and overhead cost.
Consider a database consisting of 10 consecutive disk blocks (block 1, block 2, . . ., block 10). Show the buffer state and a possible physical ordering of the blocks after the following updates, assuming that shadow paging is used, that the buffer in main memory can hold only three blocks, and
Explain how the buffer manager may cause the database to become inconsistent if some log records pertaining to a block are not output to stable storage before the block is output to disk.
Explain the benefits of logical logging. Give examples of one situation where logical logging is preferable to physical logging and one situation where physical logging is preferable to logical logging.
Explain the reasons why recovery of interactive transactions is more difficult to deal with than is recovery of batch transactions. Is there a simple way to deal with this difficulty?
Sometimes a transaction has to be undone after it has commited, because it was erroneously executed, for example because of erroneous input by a bank teller.a. Give an example to show that using the normal transaction undo mechanism to undo such a transaction could lead to an inconsistent state.b.
Logging of updates is not done explicitly in persistent programming languages. Describe how page access protections provided by modern operating systems can be used to create before and after images of pages that are updated.
Explain the difference between a system crash and a “disaster.”
For each of the following requirements, identify the best choice of degree of durability in a remote backup system:a. Data loss must be avoided but some loss of availability may be tolerated.b. Transaction commit must be accomplished quickly, even at the cost of loss of some committed transactions
Why is it relatively easy to port a database from a single processor machine to a multiprocessor machine if individual queries need not be parallelized?
Transaction server architectures are popular for client-server relational databases, where transactions are short. On the other hand, data server architectures are popular for client-server object-oriented database systems, where transactions are expected to be relatively long. Give two reasons why
Instead of storing shared structures in shared memory, an alternative architecture would be to store them in the local memory of a special process, and access the shared data by interprocess communication with the process. What would be the drawback of such architecture?
In typical client–server systems the server machine is much more powerful than the clients; that is, its processor is faster, it may have multiple processors, and it has more memory and disk capacity. Consider instead a scenario where client and server machines have exactly the same power.Would
Consider an object-oriented database system based on a client-server architecture, with the server acting as a data server.a. What is the effect of the speed of the interconnection between the client and the server on the choice between object and page shipping?b. If page shipping is used, the
What is lock de-escalation, and under what conditions is it required why is it not required if the unit of data shipping is an item?
Suppose you were in charge of the database operations of a company whose main job is to process transactions. Suppose the company is growing rapidly each year, and has outgrown its current computer system. When you are choosing a new parallel computer, what measure is most relevant—speedup, batch
Suppose a transaction is written in C with embedded SQL, and about 80 percent of the time is spent in the SQL code, with the remaining 20 percent spent in C code. How much speedup can one hope to attain if parallelism is used only for the SQL code? Explain.
What are the factors that can work against linear scaleup in a transaction processing system? Which of the factors are likely to be themost important in each of the following architectures: shared memory, shared disk, and shared nothing?
Consider a bank that has a collection of sites, each running a database system. Suppose the only way the databases interact is by electronic transfer of money between one another. Would such a system qualify as a distributed database why?
Consider a network based on dial-up phone lines, where sites communicate periodically, such as every night. Such networks are often configured with a server site and multiple client sites. The client sites connect only to the server, and exchange data with other clients by storing data at the
Discuss the relative advantages of centralized and distributed databases.
Explain how the following differ: fragmentation transparency, replication transparency, and location transparency.
How might a distributed database designed for a local-area network differ from one designed for a wide-area network?
When is it useful to have replication or fragmentation of data? Explain your answer.
Explain the notions of transparency and autonomy. Why are these notions desirable from a human-factors stand point?
To build a highly available distributed system, you must know what kinds of failures can occur.a. List possible types of failure in a distributed system.b. Which items in your list from part a are also applicable to a centralized system?
Consider a failure that occurs during 2PC for a transaction. For each possible failure that you listed in Exercise 19.6a, explain how 2PC ensures transaction atomicity despite the failure.
Consider a distributed system with two sites, A and B. Can site A distinguish among the following?• B goes down.• The link between A and B goes down.• B is extremely overloaded and response time is 100 times longer than normal. What implications does your answer have for recovery in
The persistent messaging scheme described in this chapter depends on timestamps combined with discarding of received messages if they are too old. Suggest an alternative scheme based on sequence numbers instead of timestamps.
Give an example where the read one, write all available approach leads to an erroneous state.
If we apply a distributed version of the multiple-granularity protocol of Chapter to a distributed database, the site responsible for the root of the DAG may become a bottleneck. Suppose we modify that protocol as follows:• Only intention-mode locks are allowed on the root.• All transactions
Explain the difference between data replication in a distributed system and the maintenance of a remote backup site.
Give an example where lazy replication can lead to an inconsistent database state even when updates get an exclusive lock on the primary (master) copy.
Discuss the advantages and disadvantages of the two methods that we presented in Section 19.5.2 for generating globally unique timestamps.
Consider the following deadlock-detection algorithm. When transaction Ti, at site S1, requests a resource from Tj, at site S3, a request message with timestamp n is sent. The edge (Ti, Tj, n) is inserted in the local wait-for of S1. The edge (Ti, Tj, n) is inserted in the local wait-for graph of S3
Consider a relation that is fragmented horizontally by plant-number:Employee (name, address, salary plant-number) assumes that each fragment has two replicas: one stored at the New York site and one stored locally at the plant site. Describe a good processing strategy for the following queries
Consider the relations employee (name, address, salary plant-number) machine (machine-number, type plant-number) Assume that the employee relation is fragmented horizontally by plant-number, and that each fragment is stored locally at its corresponding plant site. Assume that the machine relation
For each of the strategies of Exercise 19.18, state how your choice of a strategy depends on:a. The site at which the querywas enteredb. The site at which the result is desired
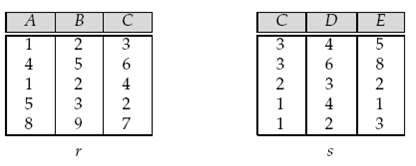
Compute r x s for the relations as shown below.
Given that the LDAP functionality can be implemented on top of a database system, what is the need for the LDAP standard?
Showing 300 - 400
of 3228
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
Last
Step by Step Answers