Operating Systems Internals and Design Principles 8th edition William Stallings - Solutions
Discover comprehensive solutions for "Operating Systems Internals and Design Principles" by William Stallings. Our online platform provides a detailed answers key and solution manual, ensuring you have access to solved problems and step-by-step answers. Explore chapter solutions and enhance your understanding with our extensive questions and answers section. Access our test bank and instructor manual to prepare thoroughly. Whether you're a student or instructor, our textbook resources, including free download options, offer invaluable insights into operating systems. Unlock the full potential of your studies with our solutions PDF and excel in your coursework.
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
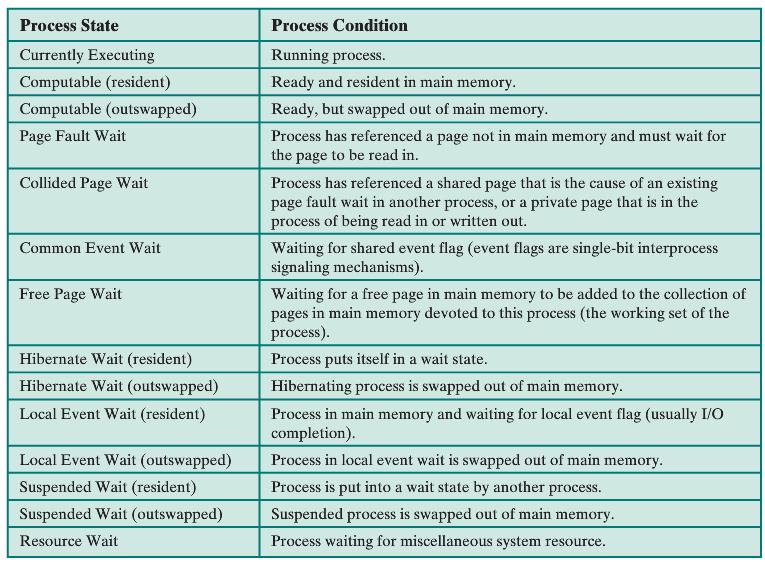
.png)
.png)
.png)
.png)




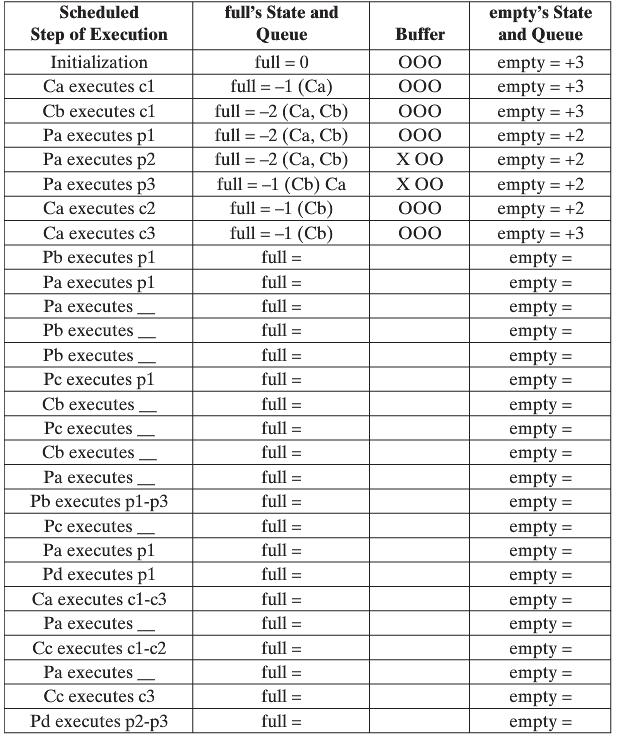
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
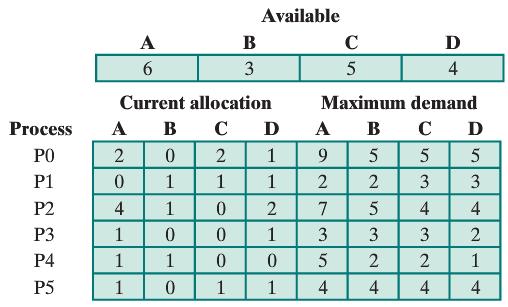
.png)


.png)

