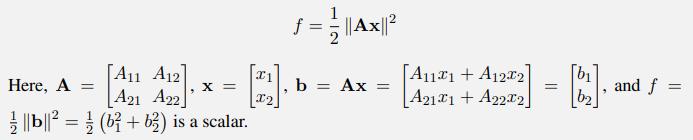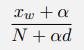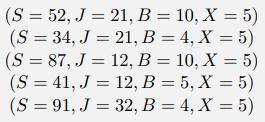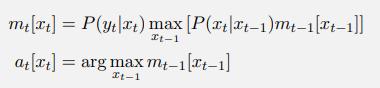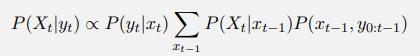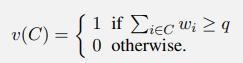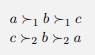New Semester
Started
Get
50% OFF
Study Help!
--h --m --s
Claim Now
Question Answers
Textbooks
Find textbooks, questions and answers
Oops, something went wrong!
Change your search query and then try again
S
Books
FREE
Study Help
Expert Questions
Accounting
General Management
Mathematics
Finance
Organizational Behaviour
Law
Physics
Operating System
Management Leadership
Sociology
Programming
Marketing
Database
Computer Network
Economics
Textbooks Solutions
Accounting
Managerial Accounting
Management Leadership
Cost Accounting
Statistics
Business Law
Corporate Finance
Finance
Economics
Auditing
Tutors
Online Tutors
Find a Tutor
Hire a Tutor
Become a Tutor
AI Tutor
AI Study Planner
NEW
Sell Books
Search
Search
Sign In
Register
study help
computer science
artificial intelligence a modern approach
Artificial Intelligence A Modern Approach 4th Edition Stuart Russell, Peter Norvig - Solutions
You would like to train a neural network to classify digits. Your network takes as input an image and outputs probabilities for each of the 10 classes, 0-9. The network’s prediction is the class that it assigns the highest probability to. From the following functions, select all that would be
In this question we will perform the backward pass algorithm on the formulaa. Calculate the following partial derivatives of f.(i) b. Calculate the following partial derivatives of b1.(i)(ii)(iii)c. Calculate the following partial derivatives of f.(i)(ii)(iii)d. Now we consider the general
This exercise asks you to implement the beginnings of a simple deep learning package.a. Implement a data structure for general computation graphs, as described in Section 21.1, and define the node types required to support feed-forward neural networks with a variety of activation functions. b.
Implement a passive learning agent in a simple environment, such as the 4 × 3 world. For the case of an initially unknown environment model, compare the learning performance of the direct utility estimation, TD, and ADP algorithms. Do the comparison for the optimal policy and for several random
Consider a text corpus consisting of N tokens of d distinct words and the number of times each distinct word w appears is given by xw. We want to apply a version of Laplace smoothing that estimates a word’s probability as: for some constant α (Laplace recommended α = 1, but other values
Implement an exploring reinforcement learning agent that uses direct utility estimation. Make two versions—one with a tabular representation and one using the function approxi-mator in Equation (22.9). Compare their performance in three environments:a. The 4 × 3 world described in the
Create a test set of ten queries, and pose them to two different Web search engines. Evaluate each one for precision at the top 1, 3, and 10 documents. Can you explain the differences between engines?
Estimate how much storage space is necessary for the index to a 100 billion-page corpus of Web pages. Show the assumptions you made.
Collect some examples of time expressions, such as “two o’clock,” “midnight,” and “12:46.” Also think up some examples that are ungrammatical, such as “thirteen o’clock” or “half past two fifteen.” Write a grammar for the time language.
In this exercise you will transform E0 into Chomsky Normal Form (CNF). There are five steps: (a) Add a new start symbol, (b) Eliminate ϵ rules, (c) Eliminate multiple words on right-hand sides, (d) Eliminate rules of the form (X → Y), (e) Convert long right-hand sides
Write a regular expression or a short program to extract company names. Test it on a corpus of business news articles. Report your recall and precision.
This exercise explores the quality of the n-gram model of language. Find or create a monolingual corpus of 100,000 words or more. Segment it into words, and compute the frequency of each word. How many distinct words are there? Also count frequencies of bigrams (two consecutive words) and trigrams
An HMM grammar is essentially a standard HMM whose state variable is N (nonterminal, with values such as Det, Adjective, Noun and so on) and whose evidence variable is W (word, with values such as is, duck, and so on). The HMM model includes a prior P(N0), a transition model P(Nt+1|Nt), and a
Consider the following PCFG for simple verb phrases: 0.1 : V P → Verb 0.2 : V P → Copula Adjective 0.5 : V P → Verb the Noun 0.2 : V P → V P Adverb 0.5 : Verb → is 0.5 : Verb → shoots 0.8 : Copula → is 0.2 : Copula → seems 0.5 : Adjective
Consider the following PCFG: S → NP VP [1.0] NP → Noun [0.6] | Pronoun [0.4] VP → Verb NP [0.8] | Modal Verb [0.2] Noun → can [0.1] | fish [0.3] | . . . Pronoun → I [0.4] | . . . Verb → can [0.01] | fish [0.1] | . . . Modal → can [0.3] | . . .The
Select five sentences and submit them to an online translation service. Translate them from English to another language and back to English. Rate the resulting sentences for grammaticality and preservation of meaning. Repeat the process; does the second round of iteration give worse results or the
Consider the following simple PCFG for noun phrases: 0.6 : NP → Det AdjString Noun 0.4 : NP → Det NounNounCompound 0.5 : AdjString → Adj AdjString 0.5 : AdjString → Λ 1.0 : NounNounCompound → Noun Noun 0.8 : Det → the 0.2 : Det → a 0.5 : Adj
Zipf ’s law of word distribution states the following: Take a large corpus of text, count the frequency of every word in the corpus, and then rank these frequencies in decreasing order. Let fI be the Ith largest frequency in this list; that is, f1 is the frequency of the most common word (usually
Without looking back at Exercise 23.TXUN, answer the following questions:a. What are the four steps that are mentioned? b. What step is left out? c. What is “the material” that is mentioned in the text? d. What kind of mistake would be expensive? e. Is it better to do too
In this exercise you will develop a classifier for authorship: given a text, the classifier predicts which of two candidate authors wrote the text. Obtain samples of text from two different authors. Separate them into training and test sets. Now train a language model on the training set. You can
This exercise concerns the classification of spam email. Create a corpus of spam email and one of non-spam mail. Examine each corpus and decide what features appear to be useful for classification: unigram words? bigrams? message length, sender, time of arrival? Then train a classification
Some linguists have argued as follows:Children learning a language hear only positive examples of the language and no negative examples. Therefore, the hypothesis that “every possible sentence is in the language” is consistent with all the observed examples. Moreover, this is the simplest
Run a notebook such as www.tensorflow.org/hub/tutorials/tf2_text_ classification that loads a pre-trained text embedding as the first layer and does transfer learning for the domain, which in this case is text classification of movie reviews. How well does the transfer learning work?
Choose a dataset from paperswithcode.com/task/question-answering and report on the NLP Question-Answering model that performs best on that dataset. It will be easier if you choose a dataset for which both a paper and code are available. What made the highest-scoring model succesful and how does it
Run a word embedding visualization tool such as projector.tensorflow.org/ and try to get a feel for how the embeddings work: what words are near each other? Are there surprises for unrelated words that are near or related words that are far apart? Report on your findings. Consider: a. Common
So far we’ve concentrated on word embeddings to represent the fundamental units of text. But it is also possible to have a character-level model. Read Andrej Karpathy’s 2015 article The Unreasonable Effectiveness of Recurrent Neural Networks and download his char-rnn code (the PyTorch version
This exercise is about the difficulty of translation, but does not use a large corpus, nor any complex algorithms–just your own ingenuity. A rare language spoken by only about a hundred people has an unusal number system that is not base ten. Below are the translations of the first ten cube
Since the publication of the textbook, a new architecture called Perceiver was introduced by Jaegle et al. in their article Perceiver: General Perception with Iterative Attention arxiv. org/abs/2103.03206. Read the article and say which of the following are true or false. a. Perceiver is a
Run a notebook such as www.tensorflow.org/tutorials/text/word2vec that learns word embeddings from a corpus using the skip-gram approach. Train the model on a corpus of Shakespeare, and separately on a corpus of contemporary language. Then test the resulting word embeddings on a downstream task
Experiment with a large-scale NLP text generation system. Pretrained online versions come and go; you could try 6b.eleuther.ai/ or transformer.huggingface. co/doc/distil-gpt2 or search for another one. Give the system some prompts and evaluate the text it generates. a. Is the generated text
Run a notebook to generate a word embedding model such as www.tensorflow. org/text/guide/word_embeddings, which trains an embedding model based on a corpus of IMDB movie reviews. Create the embedding model and visualize the embeddings. Then create another model based on a different text corpus and
Which of the following are true or false? a. A RNN is designed specifically for processing word sequences. b. A RNN is designed to process any time-series data. c. An RNN has a limit on how far into the past it can remember. d. An n-gram model has a limit on how far into the
Experiment with online sequence-to-sequence neural machine translation model, such as translate.google.com/ or www.bing.com/translator or www.deepl. com/translator. If you know two languages well, look at translations between them. If you don’t translate into a language and then back to the
Run a tutorial notebook such as www.tensorflow.org/text/tutorials/ transformer to train a Transformer model on a bilingual corpus to do machine translation. Test it to see how it performs. How does it handle unknown words?
Read medium.com/@melaniemitchell.me/can-gpt-3-make-analogies-16436Melanie Mitchell’s account of trying to replicate her 1980s work on analogy-making with a standard GPT-3 model. Mitchell’s 1980s program used symbolic AI to answer questions like “If a b c changes to a b d, what does i j k
Examine how well word embedding models can answer analogy questions of the form “A is to B as C is to [what]?” (e.g. “Athens is to Greece as Oslo is to Norway”) using vector arithmetic. Create your own embeddings or use an online site such as lamyiowce. github.io/word2viz/ or
Apply an RNN to the task of part of speech tagging. Run a notebook (such as www.kaggle.com/tanyadayanand/pos-tagging-using-rnn or github. com/roemmele/keras-rnn- notebooks/tree/master/pos_tagging), train the model on some tagged sentences, and evaluate it on some test data. Compare the results to a
Besides machine translation, describe some other tasks that can be solved by sequenceto-sequence models.
We have considered recurrent models that work a word at a time, and models that work a character at a time. It is also possible to use a subword representation, in which, say, the word “searchability” is represented as two tokens, the word “search” followed by the suffix “-ability.”Run
Apply an RNN to the task of text classification, in particular binary sentiment analysis: classifying movie reviews on IMDB as either positive or negative. Run a notebook such as www.tensorflow.org/text/tutorials/text_classification_rnn and report on your results. a. What level of accuracy can
Which of the following are true assertions about the variable elimination algorithm, and which are false? a. When changing a Bayes net by removing a parent from a variable, the maximum factor size (where size is the number of non-fixed variables involved in the factor) generated during the
Exercise 13.MRBL askes you to prove that removing an observed variable Y from a Bayes net has no effect on the posterior disribution of any variable X that is outside Y ’s Markov blanket, provided that every variable in Y ’s markov blanket is observed. In this question, we consider the effect
Alice, Bob, Carol, and Dave are being given some money, but they have to share it in a very particular way: • First, Alice will be given an integer number of dollars A, chosen uniformly at random between 1 and 100 (inclusive).• Then Bob receives from Alice an integer number of dollars B,
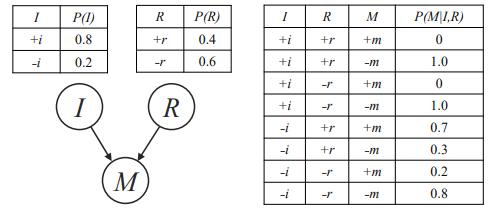
We are running Gibbs sampling in the Bayes net shown in Figure S13.47 for the query P(B, C | + h, +i, +j). The current state is +a, +b, +c, +d, +e, +f, +g, +h, +i, +j, +k. Write out an expression for the Gibbs sampling distribution for each of A, F, and K in terms of conditional probabilities
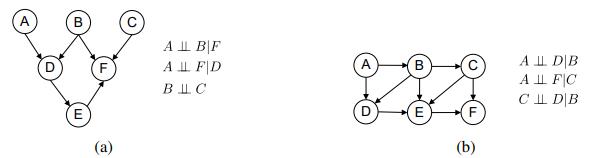
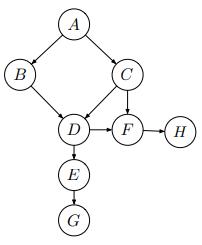
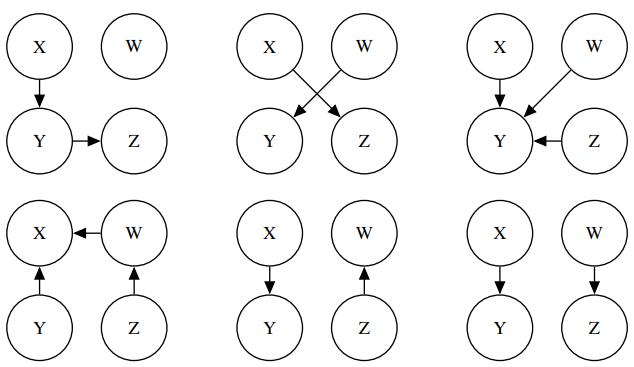
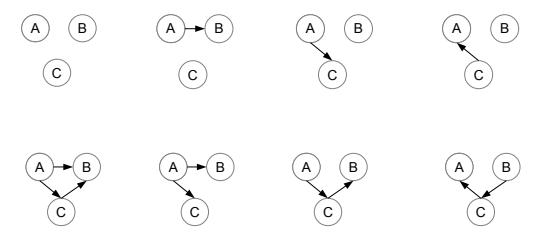
For the graphs in Figure S13.3, what is the minimal set of edges that must be removed such that the corresponding independence relations are guaranteed to be true? Figure S13.3 E (a) A B|F AFD BIC B E A D|B ALL FIC C D B
For the following Bayes nets, add the minimal number of arrows such that the resulting structure is able to represent all distributions that satisfy the stated independence and nonindependence constraints (note these are constraints on the Bayes net structure, so each nonindependence constraint
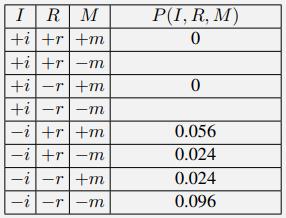
Cheating dealers have become a serious problem at the mini-Blackjack tables. A miniBlackjack deck has 3 card types (5,10,11) and an honest dealer is equally likely to deal each of the 3 cards. When a player holds 11, cheating dealers deal a 5 with probability 1/4 , 10 with probability 1/2 , and 11
In the Bayes net in Figure S13.14, state whether each of the following assertions is necessarily true, necessarily false, or undetermined. a. B is absolutely independent of C. b. B is conditionally independent of C given G. c. B is conditionally independent of C given H. d. A is
In the Bayes net in Figure S13.15, state whether each of the following assertions is necessarily true, necessarily false, or undetermined.a. A is absolutely independent of C. b. A is conditionally independent of C given E. c. A is conditionally independent of C given G. d. A is
In the Bayes net in Figure S13.16, which of the following are necessarily true? a. P(X, Y, Z) = P(X)P(Y |X)P(Z|X, Y). b. P(X, Y, Z) = P(X)P(Y |X)P(Z|Y). c. P(X, Y, Z) = P(X)P(Y |Z)P(Z|X). d. P(X, Y, Z) = P(Z)P(Y |Z)P(X|Y, Z). e. P(X, Y, Z) = P(Z)P(Y |Z)P(X|Y).Figure S13.16
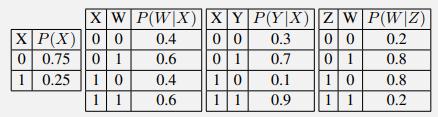
You are given the following conditional distributions that connect the binary variables W, X, Y , Z: Which of the Bayes nets in Figure S13.17 can represent a joint distribution that is consistent with these conditional distributions? Of those, which are minimal, in the sense that no edge can
Label the blank nodes in the Bayes net below with the variables {A, B, C, E} such that the following independence assertions are true: • A is conditionally independent of B given D, E; • E is conditionally independent of D given B; • E is conditionally independent of C given A,
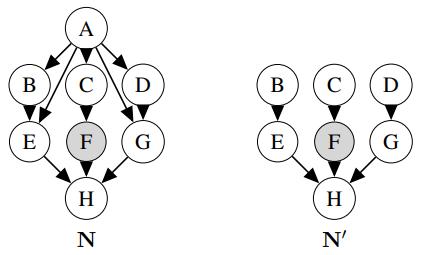
a. Consider answering P(H | + f) by variable elimination in the Bayes nets N and N' shown in Figure S13.44, where the elimination order is alphabetical and all variables are binary. How large are the largest factors made during variable elimination for N and N' ?b. Borrowing an idea from cutset
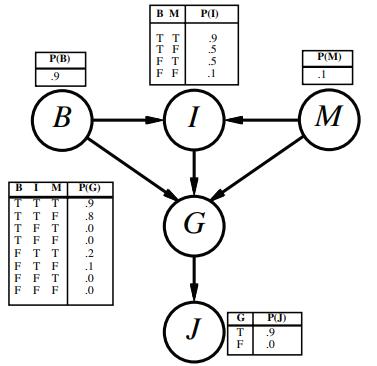
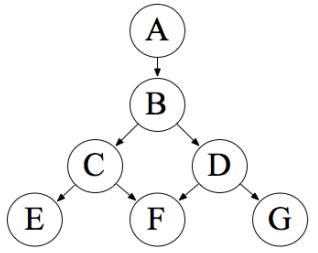
Consider the Bayes net shown in Figure S13.12.a. Which of the following are asserted by the network structure? (i) P(B, I, M) = P(B)P(I)P(M). (ii) P(J | G) = P(J | G, I). (iii) P(M | G, B, I) = P(M | G, B, I, J). b. Calculate the value of P(b, i, m, ¬g, j). c. Calculate
In the Bayes net in Figure S13.13, state whether each of the following assertions is necessarily true, necessarily false, or undetermined. a. A is absolutely independent of E. b. B is conditionally independent of C given A. c. F is conditionally independent of C given A. d. B is
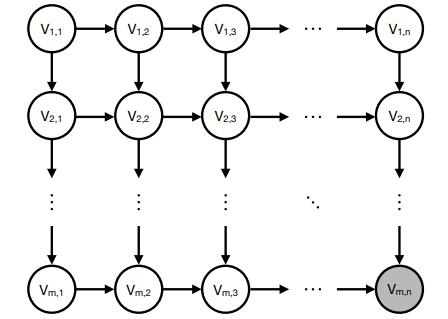
Consider doing inference in an m x n lattice Bayes net, as shown in Figure S13.43. The network consists of mn binary variables Vi,j , and you have observed that Vm,n = +vm,n.You wish to calculate P(V1,1 | + vm,n) using variable elimination. To maximize computational efficiency, you wish to use a
The probit distribution defined on page 424 describes the probability distribution for a Boolean child, given a single continuous parent. a. How might the definition be extended to cover multiple continuous parents? b. How might it be extended to handle a multivalued child variable?
a. Consider the Bayes net in Figure S13.19. (i) Given B, what variable(s) is E guaranteed to be independent of? (ii) Given B and F, what variable(s) is G guaranteed to be independent of?b. Now we’d like to formulate d-separation as a search problem. Specifically, you’re given a
Which of the following are true, and which are false? a. Bayes nets are organized into layers with connections only between adjacent layers. b. The topology of a Bayes net can assert that some variables are not conditionally independent. c. Some Bayes nets require as many parameters
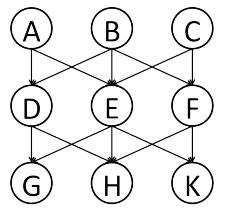
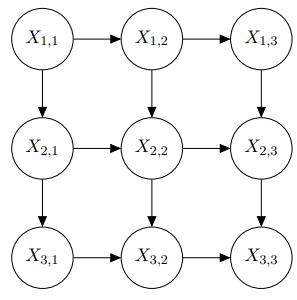
Consider the Bayes net below in Figure S13.22 with 9 variables: a. Which random variables are independent of X3,1?b. Which random variables are conditionally independent of X3,1 given X1,1? c. Which random variables are conditionally independent of X3,1 given X1,1 and X3,3?Figure S13.22
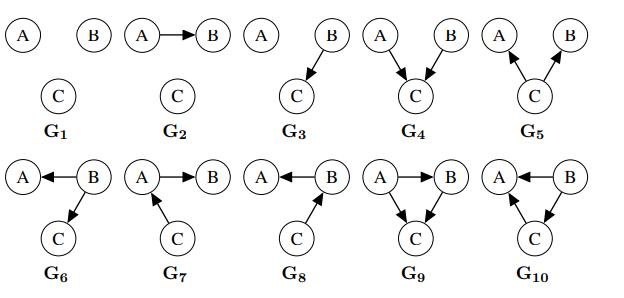
Assume we are given the ten Bayes nets in Figure S13.26, labeled G1 to G10. Assume we are also given the three Bayes nets in Figure S13.27, labeled B1 to B3. a. Assume we know that a joint distribution d1 (over A, B, C) can be represented by Bayes net B1. Which of G1 through G10 are guaranteed
There has been an outbreak of mumps in your college. You feel fine, but you’re worried that you might already be infected. You decide to use Bayes nets to analyze the probability that you’ve contracted the mumps.You first think about the following two factors:• You think you have immunity
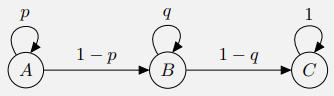
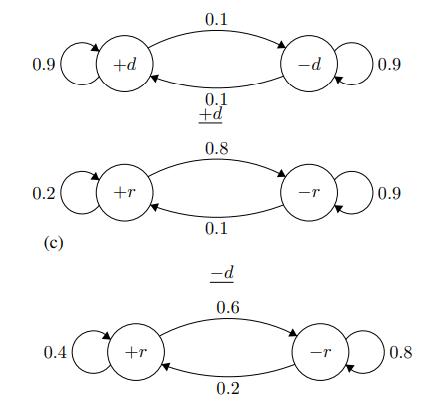
Suppose that an object is moving according to the following transition model: Here, 0 < p < 1 and 0 < q < 1 are arbitrary probabilities. At time 0, the object is known to be in state A. a. What is the probability that the object is in A at time n ≥ 0? b. What is the
Let P be a probability distribution over random variables A, B, C. Let Q be another probability distribution over the same variables, defined by a Bayes net in which B and C are conditionally independent given A. We are given that Q(A) = P(A), Q(B|A) = P(B|A), and Q(C|A) = P(C|A). Which if the
Consider a Markov chain with 3 states and transition probabilities as shown below: Compute the stationary distribution. That is, compute P∞(A), P∞(B), P∞(C). 0.25 CC A 0.75 0.75 B 0.25 0.5 C D 0.5
In which of the Bayes nets in Figure S13.25 does the equation P(A, B)P(C) = P(A)P(B, C) necessarily hold?Figure S13.25 A A B B A B В A В A B
Consider the vacuum worlds of Figure 4.18 (perfect sensing) and Figure 14.7 (noisy sensing). Suppose that the robot receives an observation sequence such that, with perfect sensing, there is exactly one possible location it could be in. Is this location necessarily the most probable location under
For the Bayes net structures in Figure S?? and Figure S?? that are missing a direction on their edges, assign a direction to each edge such that the Bayes net structure implies the stated conditional independences and does not imply the conditional independences stated not to hold. a.
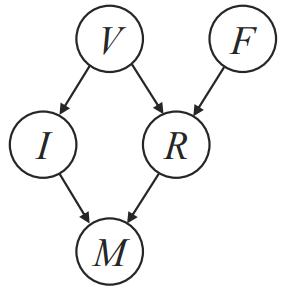
Transportation researchers are trying to improve traffic in the city but, in order to do that, they first need to estimate the location of each of the cars in the city. They need our help to model this problem as an inference problem of an HMM. For this question, assume that only one car is being
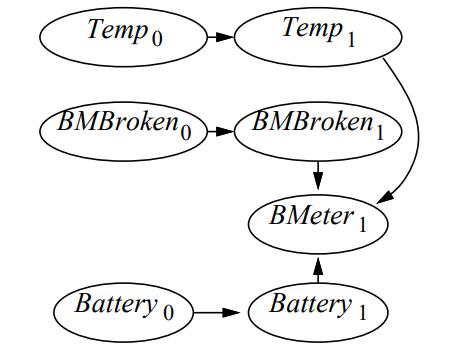
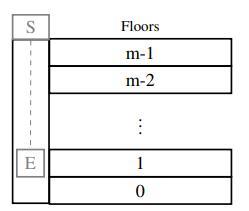
Assume the elevator of the Disney Tower of Terror E follows a Markovian process and has m floors at which it can stop. In the dead of night, you install a sensor S at the top of the shaft that gives approximate distance measurements, quantized into n different distance bins. Assume that the
Computing the evidence likelihood L1:t = P(e1:t) in a temporal sequence can be done using a recursive computation similar to the filtering algorithm. Show that the likelihood message ℓ1:t(Xt) = P(Xt , e1:t) satisfies the same recursive relationship as the filtering message; that is, ℓ1:t+1 =
Consider two particle filtering implementations: Implementation 1: Initialize particles by sampling from initial state distribution and assigning uniform weights. 1. Propagate particles, retaining weights 2. Resample according to weights 3. Weight according to
Consider the Bayes net obtained by unrolling the DBN in Figure 14.20 to time step t.Use the conditional independence properties of this network to show that P(Dirt 1,0.t..., Dirt 42,0:t | DirtSensor 1:t, WallSensor 1:t, Location 1:t) P(Dirtį,0t | DirtSensor 1:t, Location 1:t). =
In California, whether it rains or not from each day to the next forms a Markov chain (note: this is a terrible model for real weather). However, sometimes California is in a drought and sometimes it is not. Whether California is in a drought from each day to the next itself forms a Markov chain,
(iv) [true or false] With a deterministic transition model and a stochastic observation model, as time goes to infinity, when running a particle filter we will end up with all identical particles.(v) [true or false] With a deterministic observation model, all particles might end up having zero
In which settings is particle filtering better than exact HMM inference? • Large vs. Small state spaces. • Prioritizing runtime vs. accuracy.
Consider an HMM with state variables {Xi} and emission variables {Yi}. (i) [True or false] Xi is always conditionally independent of Yi+1 given Xi+1. (ii) [True or false] There exists an HMM where Xi is conditionally independent of Yi given Xi+1. (iii) [True or false] If Yi = Xi with
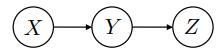
Consider a probability model P(X, Y, Z, E), where Z is a single query variable and evidence E = e is given. A basic Monte Carlo algorithm generates N samples (ideally) from P(X, Y, Z | E = e) and estimates the query probability P(Z = z | E = e) from those samples. This gives an unbiased estimate
Equation (17.11) shown below states that the Bellman operator is a contraction. a. Show that, for any functions f and g,b. Write out an expression for |(B Ui − B U'i)(s)| and then apply the result from (a) to complete the proof that the Bellman operator is a contraction. | max f(a) - max
In this exercise we explore the application of UCT to Tetris. a. Create an implementation the Tetris MDP as described in Figure 17.5. Each action simply places the current piece in any reachable location and orientation. b. Estimate the reward for a purely random policy by running
Value iteration: (i) Is a model-free method for finding optimal policies. (ii) Is sensitive to local optima. (iii) Is tedious to do by hand. (iv) Is guaranteed to converge when the discount factor satisfies 0 < γ < 1.
a. Please indicate if the following statements are true or false. (i) Let A be the set of all actions and S the set of states for some MDP. Assuming that |A| << |S|, one iteration of value iteration is generally faster than one iteration of policy iteration that solves a linear system
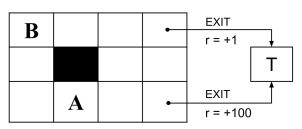
Pacman finds himself inside the grid world MDP depicted in Figure S17.5. Each rectangle represents a possible state. At each state, Pacman can take actions up, down, left or right. If an action moves him into a wall, he will stay in the same state. At states A and B, Pacman can take the exit action
Please indicate whether the following statements are true of false a. If the only difference between two MDPs is the value of the discount factor then they must have the same optimal policy. b. When using features to represent the Q-function (rather than having a tabular representation) it is
Consider an (N + 1) × (N + 1) × (N + 1) cubic gridworld. Luckily, all the cells are empty – there are no walls within the cube. For each cell, there is an action for each adjacent facing open cell (no corner movement), as well as an action stay. The actions all move into the corresponding cell
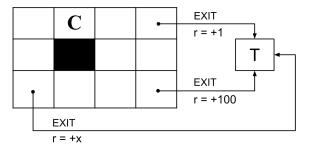
Suppose we run value iteration in an MDP with only non-negative rewards (that is, R(s, a, s') ≥ 0 for any (s, a, s')). Let the values on the kth iteration be Vk(s) and the optimal values be V∗ (s). Initially, the values are 0 (that is, V0(s) = 0 for any s).a. Mark all of the options that are
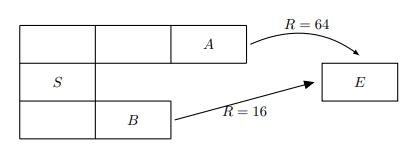
Recall that a weighted voting game is a cooperative game defined by a structure G = [q; w1, . . . , wn] where q is the quota, the players are N = {1, . . . , n}, the value wi is the weight of player i, and the characteristic function of the game is defined as follows:Compute the players’ Shapley
Consider the following deterministic MDP with 1-dimensional continuous states and actions and a finite task horizon:State Space S: RAction Space A: RReward Function: R(s, a, s') = −qs2 − ra2 where r > 0 and q ≥ 0 Deterministic Dynamics/Transition Function: s' = cs + da (i.e., the next
Suppose we are given a cooperative game G = ({1, 2}, v) with characteristic function v defined by:Show that weighted voting games cannot capture this “singleton” game: we will not be able to find a quota q and weights wi such that for all coalitions C, Σi∈C wi ≥ q iff C contains exactly
Define the following in your own words: a. Multiagent system b. Multibody planning c. Coordination problem d. Agent design e. Mechanism design f. Cooperative game
Give some examples, from movies or literature, of bad guys with a formidable army (robotic or otherwise) that inexplicably is under centralized control rather than more robust multiagent control, so that all the good guys have to do is defeat the one master controller in order to win.
In the Landowner and Workers game there is a landowner ℓ and n workers w1, . . . , wn. A group of workers may lease the land from the landowner and grow vegetables on it. Their productivity depends on the group size: a group of k workers can grow f(k) tons of vegetables, where f is an increasing
Consider the following scenario:Five pirates wish to divide the loot of a 100 gold pieces. They are democratic pirates, in their own way, and it is their custom to make such divisions in the following manner: The fiercest pirate makes a proposal about the division and everybody (including the
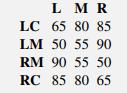
In the game of football (“soccer” in the US), a player who is awarded a penalty kick scores about 3/4 of the time. Suppose we model a penalty kick as a game between two players, the shooter, S, and the goalkeeper, G. The shooter has 4 possible actions:LC: Aim for left corner of the goal.LM: Aim
Consider the following scenario:Two players (N = {1, 2}) must choose between three outcomes Ω = {a, b, c}. The rule they use is the following: Player 1 goes first, and vetoes one of the outcomes. Player two then chooses one of the remaining two outcomes. Suppose that player preferences
Consider a 2 player game in which player 1 can choose A or B. The game ends if she chooses A, while it continues to player 2 if he chooses B. Player 2 can then choose C or D with the game ending if C is chosen, and continuing again to player 1 if D is chosen. Player 1 can then choose E or F, with
Consider the following scenario:There are two pirates operating among three islands A, B, and C. On each island, two treasures are buried: a large one worth 2 and another smaller one worth 1. The prevailing winds in the area are such that from island A you can only reach island B, from island B
Avi and Bailey are friends, and enjoy a night out together in the pub. They each will independently decide to go either to the Turf or the Rose.Avi mildly prefers the Rose over the Turf and would get a utility of 2 from going to the Rose with Bailey, but only 1 from the Turf.Bailey has a very
Define the following machine-learning terms in your own words a. Training setb. Hypothesisc. Biasd. Variance
Indicate which of answer(s) in parentheses are correct for each question: a. For binary class classification, does logistic regression always produce a linear decision boundary? (Yes; No) b. You train a linear classifier on 1,000 training points and discover that the training accuracy is
Showing 100 - 200
of 303
1
2
3
4
Step by Step Answers