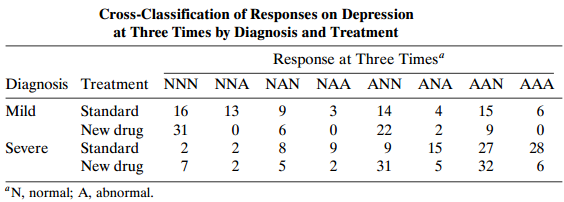
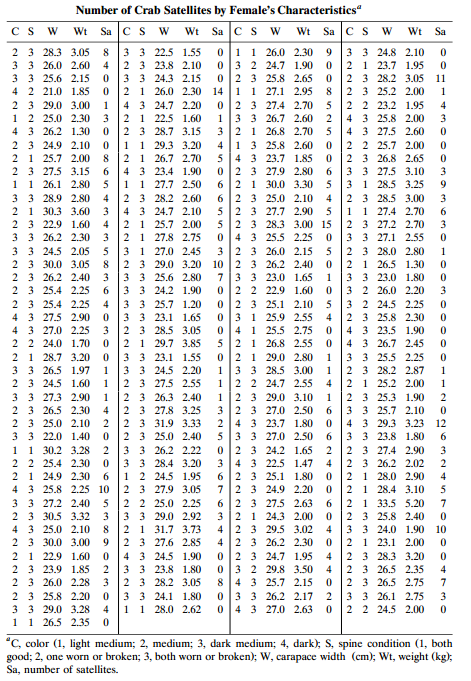
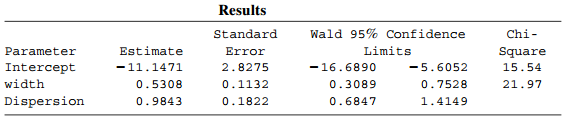
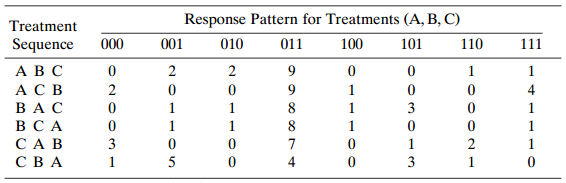
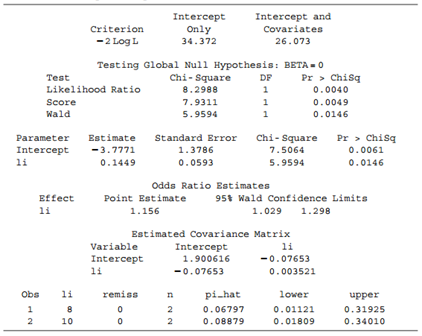
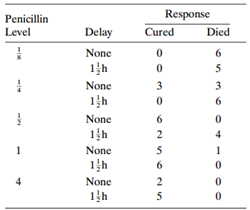
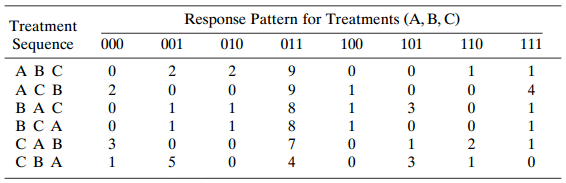
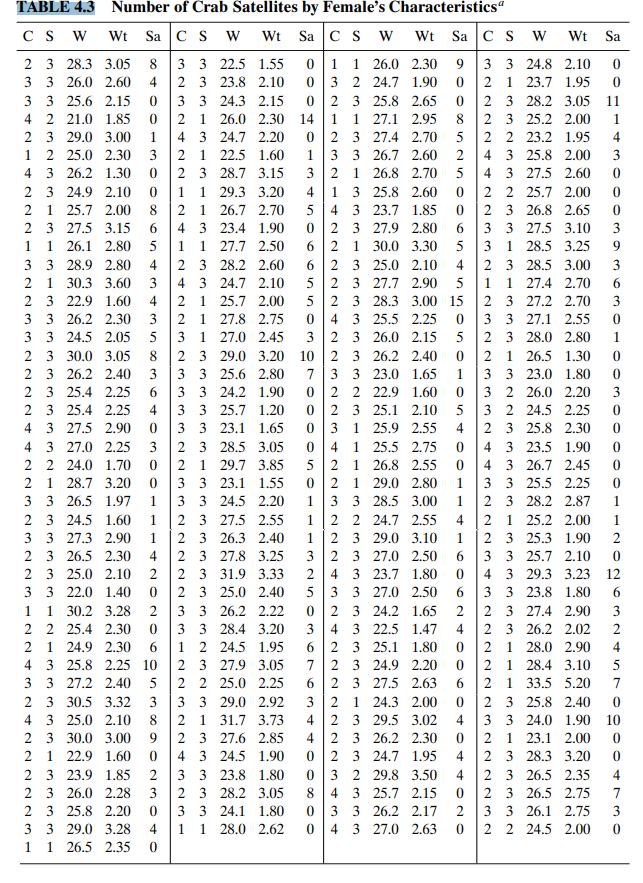
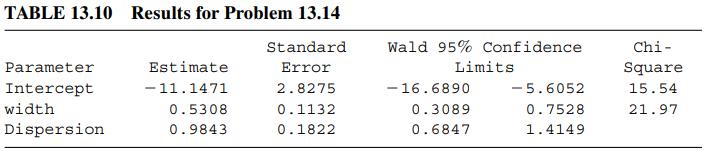
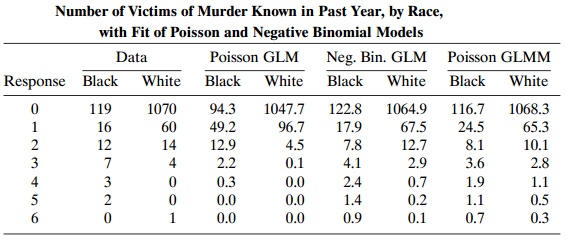
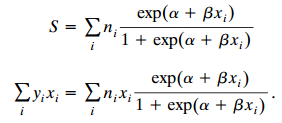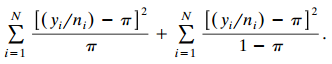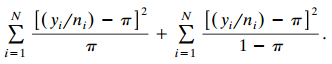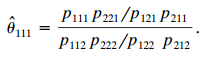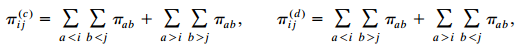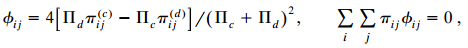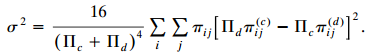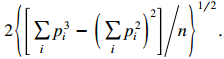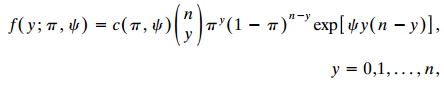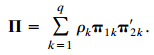Categorical Data Analysis 2nd Edition Alan Agresti - Solutions
Looking to master "Categorical Data Analysis 2nd Edition" by Alan Agresti? Dive into our comprehensive solutions manual that provides step-by-step answers to all textbook questions. Whether you're seeking the answers key, solved problems, or chapter solutions, our resources have you covered. Explore our online platform for a free download of the solutions PDF, which includes an extensive test bank and instructor manual. Enhance your understanding with our detailed questions and answers, designed to support both students and instructors in their academic journey. Access top-quality content to excel in your studies today!