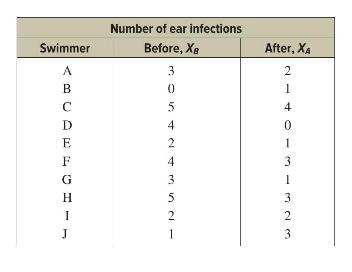
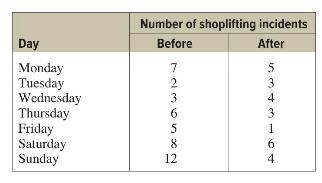
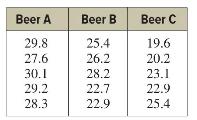
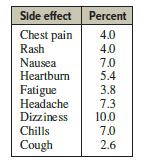
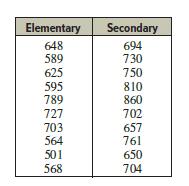
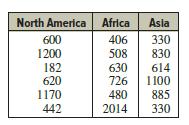
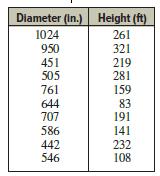
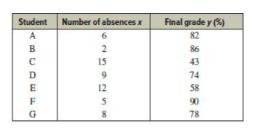
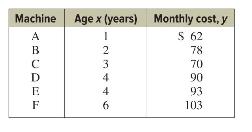
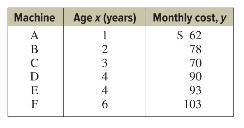
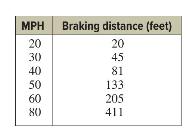
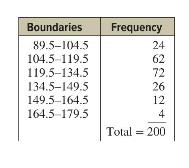
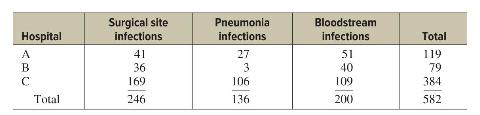
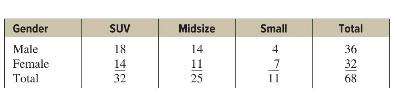
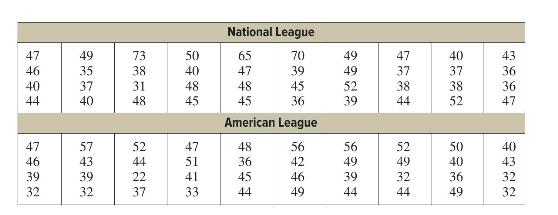
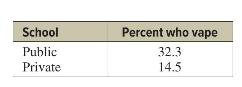
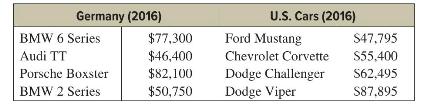
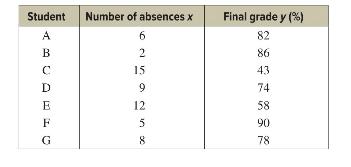
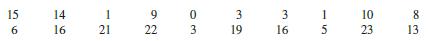Elementary Statistics A Step By Step Approach 11th Edition Allan Bluman - Solutions
Discover comprehensive resources for "Elementary Statistics A Step By Step Approach 11th Edition" by Allan Bluman. Access the online answers key and solutions manual, complete with solutions in PDF format. Explore solved problems and detailed questions and answers, offering a clear understanding of each chapter. Benefit from the test bank and chapter solutions, with step-by-step answers that simplify complex concepts. Ideal for instructors, the instructor manual and textbook solutions enhance teaching and learning experiences. Enjoy the convenience of a free download, making statistical learning accessible to all.