New Semester
Started
Get
50% OFF
Study Help!
--h --m --s
Claim Now
Question Answers
Textbooks
Find textbooks, questions and answers
Oops, something went wrong!
Change your search query and then try again
S
Books
FREE
Study Help
Expert Questions
Accounting
General Management
Mathematics
Finance
Organizational Behaviour
Law
Physics
Operating System
Management Leadership
Sociology
Programming
Marketing
Database
Computer Network
Economics
Textbooks Solutions
Accounting
Managerial Accounting
Management Leadership
Cost Accounting
Statistics
Business Law
Corporate Finance
Finance
Economics
Auditing
Tutors
Online Tutors
Find a Tutor
Hire a Tutor
Become a Tutor
AI Tutor
AI Study Planner
NEW
Sell Books
Search
Search
Sign In
Register
study help
computer science
computer organization design
Computer Organization And Design The Hardware Software Interface 4th Revised Edition David A. Patterson, John L. Hennessy - Solutions
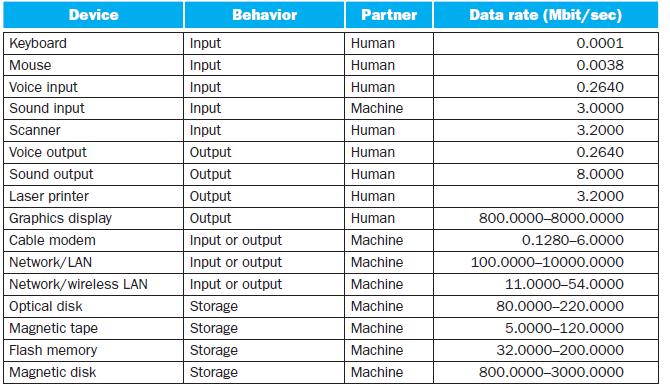
Select an appropriate bus (FireWire, USB, PCI, or SATA) for the peripherals listed in the table. Explain why the bus selected is appropriate.Among the most common bus types used in practice today are FireWire (IEEE 1394), USB, PCI, and SATA. Although all four are asynchronous, they are implemented
Describe device polling. Would each application in the table be appropriate for communication using polling techniques? Explain.Communicating with I/O devices is achieved using combinations of polling, interrupt handling, memory mapping, and special I/O commands. Answer the questions about
When an interrupt is detected, the Status register is saved and all but the highest priority interrupt is disabled. Why are low-priority interrupts disabled? Why is the status register saved prior to disabling interrupts?Section 6.6 defines an eight-step process for handling interrupts. The Cause
For the applications listed in the table, outline a design for commands implementing command driven communication. Identify commands and their interaction with the device.Communicating with I/O devices is achieved using combinations of polling, interrupt handling, memory mapping, and special I/O
For each application in the table, does I/O performance dominate system performance?Metrics for I/O performance may vary dramatically from application to application. Where the number of transactions processed dominates performance in some situations, data throughput dominates in others. Explore
For each application in the table, define characteristics that a set of benchmarks should exhibit when evaluating an I/O subsystem.Benchmarks play an important role in evaluating and selecting peripheral devices. For benchmarks to be useful, they must exhibit properties similar to those experienced
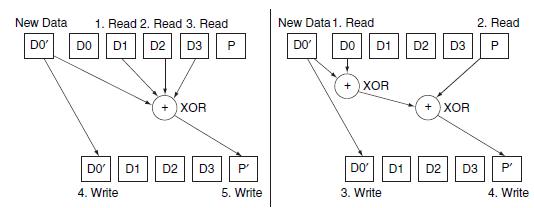
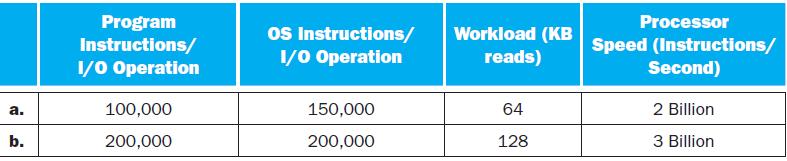
Calculate the new RAID 3 parity value P’ for data in lines a and b in the table.RAID 3, RAID 4, and RAID 5 all use parity system to protect blocks of data. Specifically, a parity block is associated with a collection of data blocks. Each row in the following table shows the values of the data and
RAID 0 uses striping to force parallel access among many disks. Why does striping improve disk performance? For each of the activities listed in the table, will striping help better achieve their goals?RAID is among the most popular approaches to parallelism and redundancy in storage systems. The
Find the maximum sustained I/O rate for random reads and writes. Ignore disk conflicts and assume the RAID controller is not the bottleneck. Follow the same approach as outlined in Section 6.10 making similar assumptions where necessary.The emergence of web servers for ecommerce, online storage,
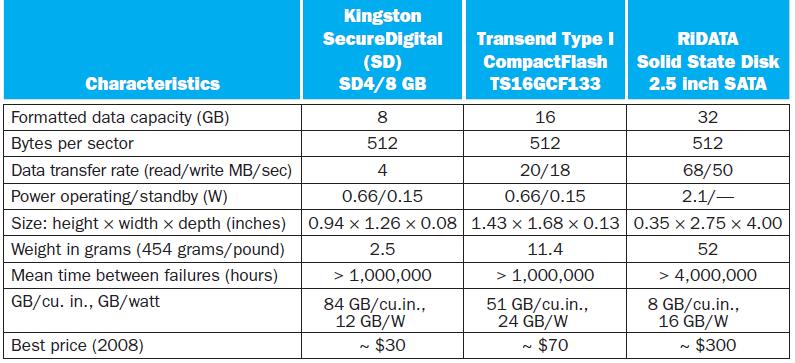
Calculate the average time to read or write a 1024-byte sector for each disk listed in the table.Average and minimum times for reading and writing to storage devices are common measurements used to compare devices. Using techniques from Chapter 6, calculate values related to read and write time for
For the application listed above, identify runtime characteristics for an operational system. Choose characteristics that will support evaluation similar to that performed for Exercise 6.16.Data from Exercise 6.16The emergence of web servers for ecommerce, online storage, and communication has made
For each application, would decreasing the sector size during reads and writes improve performance? Explain your answer.Ultimately, storage system design requires consideration of usage scenarios as well as disk parameters. Different situations require different metrics. Let's try to systematically
For each application, would increasing disk rotation speed improve performance? Explain your answer.Ultimately, storage system design requires consideration of usage scenarios as well as disk parameters. Different situations require different metrics. Let's try to systematically evaluate disk
Would each application benefit from a solid state FLASH drive given that cost is a design factor?FLASH memory is one of the first true competitors for traditional disk drives. Explore the implications of FLASH memory by answering questions about the following applications. a. Aircraft Control
Calculate the minimum time to read or write a 512-byte sector for each FLASH memory listed in the table.Explore the nature of FLASH memory by answering the questions related to performance for FLASH memories with the following characteristics. a. b. Data Transfer Rate 120 MB/s 100 MB/s Controller
What problems would long, synchronous busses cause for connections between a CPU and the peripherals listed in the table?I/O can be performed either synchronously or asynchronously. Explore the differences by answering performance questions about the following peripherals. Printer b. Scanner a.
Assume that annual failure rate varies over the lifetime of disks in the previous table. Speciically, assume that AFR is three times as high in the 1st month of operation and doubles every year starting in the 5th year. How many disks would be replaced after 7 years of operation? What about 10
Use online or library resources and summarize the communication structure for each bus type. Identify what the bus controller does and where the control physically is.Among the most common bus types used in practice today are FireWire (IEEE 1394), USB, PCI, and SATA. Although all four are
Describe interrupt driven communication. For each application in the table, if polling is inappropriate, explain how interrupt driven techniques could be used.Communicating with I/O devices is achieved using combinations of polling, interrupt handling, memory mapping, and special I/O commands.
For the interfaces identified in the previous problem, estimate their data rate.Figure 6.2 describes numerous I/O devices in terms of their behavior, partner, and data rate. However, these classifications often do not provide a complete picture of data low within a system. Explore device
Prioritize interrupts from the devices listed in each table row.Section 6.6 defines an eight-step process for handling interrupts. The Cause and Status registers together provide information on the cause of the interrupt and the status of the interrupt handling system. Explore interrupt handling by
Recommend a backup and data archiving system for the disk array from 6.20.1. Compare and contrast disk, tape, and online backup capabilities. Use Internet and library resources to identify potential servers. Assess cost and suitability for the application using parameters described in Chapter 6.
Of the peripherals listed in the table, which would benefit from DMA? What criteria determine if DMA is appropriate?Direct Memory Access (DMA) allows devices to access memory directly rather than working through the CPU. This can dramatically speed up the performance of peripherals, but adds
For each application in the table, is I/O performance best measured using raw data throughput?Metrics for I/O performance may vary dramatically from application to application. Where the number of transactions processed dominates performance in some situations, data throughput dominates in others.
Using online or library resources, identify a set of standard benchmarks for applications in the table. Why do standard benchmarks help?Benchmarks play an important role in evaluating and selecting peripheral devices. For benchmarks to be useful, they must exhibit properties similar to those
Calculate the new RAID 4 parity value P’ for data in lines a and b in the table.RAID 3, RAID 4, and RAID 5 all use parity system to protect blocks of data. Specifically, a parity block is associated with a collection of data blocks. Each row in the following table shows the values of the data and
RAID 1 mirrors data among several disks. Assuming that inexpensive disks have lower MTBF than expensive disks, how can redundancy using inexpensive disks result in a system with lower MTBF? Use the mathematical deinition of MTBF to explain your answer. For each of the activities listed in the
Assume we are configuring a Sun Fire x4150 server as described in Section 6.10. Determine if a configuration of 8 disks presents an I/O bottleneck. Repeat for configurations of 16, 4, and 2 disks.The emergence of web servers for ecommerce, online storage, and communication has made disk servers
Calculate the availability for each of the devices in the table.Mean Time Between Failures (MTBF), Mean Time To Replacement (MTTR), and Mean Time To Failure (MTTF) are useful metrics for evaluating the reliability and availability of a storage resource. Explore these concepts by answering the
Calculate the minimum time to read or write a 2048-byte sector for each disk listed in the table.Average and minimum times for reading and writing to storage devices are common measurements used to compare devices. Using techniques from Chapter 6, calculate values related to read and write time for
For the application listed above, find a server available in the marketplace that you feel would be appropriate for running the application. Before evaluating the server, identify reasons why it was selected.Determining the performance of a single server with relatively complete data is an easy
Figure 6.6 shows that FLASH memory read and write access times increase as FLASH memory gets larger. Is this unexpected? What factors cause this?Explore the nature of FLASH memory by answering the questions related to performance for FLASH memories with the following characteristics.
For each application, would increasing disk rotation speed improve system performance given that MTTF is decreased? Explain your answer.Ultimately, storage system design requires consideration of usage scenarios as well as disk parameters. Different situations require different metrics. Let's try
Would each application be inappropriate for a solid state FLASH drive given that cost is NOT a design factor?FLASH memory is one of the first true competitors for traditional disk drives. Explore the implications of FLASH memory by answering questions about the following applications. a. Aircraft
What problems would asynchronous busses cause for connections between a CPU and the peripherals listed in the table?I/O can be performed either synchronously or asynchronously. Explore the differences by answering performance questions about the following peripherals. Printer b. Scanner a.
Assume that disks with lower failure rates are more expensive. Specifically, disks are available at a higher cost that will start doubling their failure rate in year 8 rather than year 5. How much more would you pay for disks if your intent is to keep them for 7 years? What about 10
Outline limitations of each of the bus types. Explain why those limitations must be taken into consideration when using the bus.Among the most common bus types used in practice today are FireWire (IEEE 1394), USB, PCI, and SATA. Although all four are asynchronous, they are implemented in different
For the applications listed in the table, outline a design for memory mapped communication. Identify reserved memory locations and outline their contents.Communicating with I/O devices is achieved using combinations of polling, interrupt handling, memory mapping, and special I/O commands. Answer
For the interfaces identified in the previous problem, determine whether data rate or operation rate is the best performance measurement.Data from in previous problemFigure 6.2 describes numerous I/O devices in terms of their behavior, partner, and data rate. However, these classifications often do
For each application in the table, is I/O performance best measured using the number of transactions processed?Metrics for I/O performance may vary dramatically from application to application. Where the number of transactions processed dominates performance in some situations, data throughput
Does it make sense to evaluate an I/O subsystem outside the larger system it is a part of? How about evaluating a CPU?Benchmarks play an important role in evaluating and selecting peripheral devices. For benchmarks to be useful, they must exhibit properties similar to those experienced by a device
Is RAID 3 or RAID 4 more efficient? Are there reasons why RAID 3 would be preferable to RAID 4?RAID 3, RAID 4, and RAID 5 all use parity system to protect blocks of data. Specifically, a parity block is associated with a collection of data blocks. Each row in the following table shows the values of
Like RAID 1, RAID 3 provides higher data availability. Explain the trade-off between RAID 1 and RAID 3. Would each of the applications listed in the table benefit from RAID 3 over RAID 1?RAID is among the most popular approaches to parallelism and redundancy in storage systems. The name Redundant
Determine if the PCI bus, DIMM, or the Front Side Bus presents an I/O bottleneck. Use the same parameters and assumptions used in Section 6.10.The emergence of web servers for ecommerce, online storage, and communication has made disk servers critical applications. Availability and speed are
Using metrics similar to those used in Chapter 6 and Exercise 6.16, assess the server you identified in 6.17.2 in comparison to the Sun Fire x4150 server evaluated in Exercise 6.16. Which would you choose? Did the results of your analysis surprise you? Specifically, would you choose
For each disk in the table, determine the dominant factor for performance. Specifically, if you could make an improvement to any aspect of the disk, what would you choose? If there is no dominant factor, explain why.Average and minimum times for reading and writing to storage devices are common
What happens to availability as the MTTR approaches 0? Is this a realistic situation?Mean Time Between Failures (MTBF), Mean Time To Replacement (MTTR), and Mean Time To Failure (MTTF) are useful metrics for evaluating the reliability and availability of a storage resource. Explore these concepts
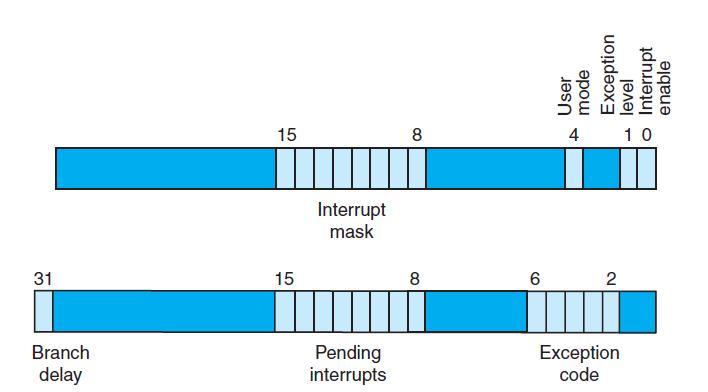
What happens if the interrupt enable bit of the Cause register is not set when handling an interrupt? What value could the interrupt mask value take to accomplish the same thing?Section 6.6 defines an eight-step process for handling interrupts. The Cause and Status registers together provide
Describe what problems could occur when mixing DMA and virtual memory. Which of the peripherals in the table could introduce such problems? How can they be avoided?Direct Memory Access (DMA) allows devices to access memory directly rather than working through the CPU. This can dramatically speed up
RAID 4 and RAID 5 use roughly the same mechanism to calculate and store parity for data blocks. How does RAID 5 differ from RAID 4 and for what applications would RAID 5 be more efficient?RAID 3, RAID 4, and RAID 5 all use parity system to protect blocks of data. Specifically, a parity block is
Is there a relationship between the performance measures from the previous two problems and choosing whether to use polling or interrupt driven communication? What about the choice of using memory mapped or commanddriven I/O?Metrics for I/O performance may vary dramatically from application to
Explain why real systems tend to use benchmarks or real applications to assess actual performance.The emergence of web servers for ecommerce, online storage, and communication has made disk servers critical applications. Availability and speed are well-known metrics for disk servers, but power
What happens to availability as the MTTR gets very high, i.e., a device is dificult to repair? Does this imply the device has low availability?Mean Time Between Failures (MTBF), Mean Time To Replacement (MTTR), and Mean Time To Failure (MTTF) are useful metrics for evaluating the reliability and
Most interrupt handling systems are implemented in the operating system. What hardware support could be added to make interrupt handling more efficient? Contrast your solution to potential hardware support for function calls.Section 6.6 defines an eight-step process for handling interrupts. The
Identify a standard benchmark set that would be useful for comparing the server you identified in 6.17.2 with the Sun Fire x4150.Exercise 6.17.2For the application listed above, find a server availablein the marketplace that you feel would be appropriate for running the application. Before
Does it make sense to define I/O subsystems that use a combination of memory mapping and command driven communication? Explain your answer.Communicating with I/O devices is achieved using combinations of polling, interrupt handling, memory mapping, and special I/O commands. Answer the questions
RAID 4 and RAID 5 speed improvements grow with respect to RAID 3 as the size of the protected block grows. Why is this the case? Is there a situation where RAID 4 and RAID 5 would be no more efficient than RAID 3?RAID 3, RAID 4, and RAID 5 all use parity system to protect blocks of data.
In some interrupt handling implementations, an interrupt causes an immediate jump to an interrupt vector. Instead of a Cause register where each interrupt sets a bit, each interrupt has its own interrupt vector. Can the same priority interrupt system be implemented using this approach? Is there any
Develop an equation that computes how many links in the n-cube (where n is the order of the cube) can fail and we can still guarantee an unbroken link will exist to connect any node in the n-cube.Refer to Figure 7.7b that shows an n-cube interconnect topology of order 3 that interconnects 8 nodes.
Describe the scenario where none of philosophers ever eats (i.e., starvation). What is the sequence of events that happen that lead up to this problem?The dining philosopher's problem is a classic problem of synchronization and concurrency. The general problem is stated as philosophers sitting at a
What are all the possible resulting values of w, x, y, and z? For each possible outcome, explain how we might arrive at those values. You will need to examine all possible inter leavings of instructions.Consider the following portions of two different programs running at the same time on four
For a 4 CPU MIMD machine, show the sequence of MIPS instructions that you would execute on each CPU. What is the speedup for this MIMD machine?We would like to execute the loop below as efficiently as possible. We have two different machines, a MIMD machine and a SIMD machine. for (i=0; i < 2000;
Consider proposed implementations of a systolic array (you can find these in on the Internet or in technical publications). Then attempt to program the loop provided in Exercise 7.14 using this MISD model. Discuss any difficulties you encounter.Exercise 7.14We would like to execute the loop below
If we have P CPU in the system, with T nodes in the CCNUMA system, with each CPU having C memory blocks stored in it, and we maintain a byte of coherency information in each cache line, provide an equation that expresses the amount of memory that will be present in the caches in a single node of
For a system that maintains coherency using cache-based block status, describe the inter-node traffic that will be generated as each of the 4 cores writes to a unique address, after which each address written to is read from by each of the remaining 3 cores.Considering the CC-NUMA system described
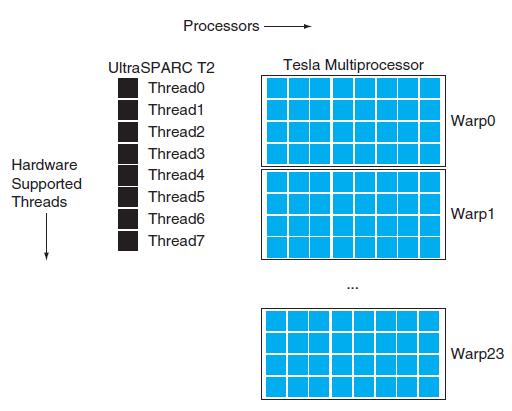
Describe how you will constructs warps for the SAXP loop to exploit the 8 cores provided in a single multiprocessor.Assume we want to execute the DAXP loop show on page 651 in MIPS assembly on the NVIDIA 8800 GTX GPU described in this Chapter. In this problem, we will assume that all math
Using the “template” SDK sample as a starting point, write a CUDA program to perform the following vector operations:Submit code for each program that demonstrates each operation and verifies the correctness of the results.Download the CUDA Toolkit and SDK from
Now consider which of these activities is already exploiting some form of parallelism (e.g., brushing multiple teeth at the same time, versus one at a time, carrying one book at a time to school, versus loading them all into your backpack and then carry them "in parallel"). For each of your
If on average we need to access memory once every 75 cycles, what is impact on our application?On a CC-NUMA system, the cost of accessing non-local memory can limit our ability to utilize multiprocessing effectively. The following table shows the costs associated with access data in local memory
Consider the following binary search algorithm (a classic divide and conquer algorithm) that searches for a value X in an sorted N-element array A and returns the index of matched entry:Assume that you have Y cores on a multi-core processor to run Binary Search. Assuming that Y is much smaller than
Assume that you have Y cores on a multi-core processor to run MergeSort. Assuming that Y is much smaller than length(m), express the speedup factor you might expect to obtain for values of Y and length(m). Plot these on a graph.Consider the following recursive mergesort algorithm (another classic
How many cycles does it take for all instructions in a single iteration of the above loop to execute?Consider the following piece of C code:Instructions have the following associated latencies (in cycles): for (j-2;j
Assume that we are going to compute C on both a single core shared memory machine and a 4-core shared-memory machine. Compute the speedup we would expect to obtain on the 4-core machine, ignoring any memory issues.Matrix multiplication plays an important role in a number of applications. Two
Your job is to cook 3 cakes as efficiently as possible. Assuming that you only have one oven large enough to hold one cake, one large bowl, one cake pan, and one mixer, come up with a schedule to make three cakes as quickly as possible. Identify the bottlenecks in completing this task.You are
Repeat 7.6.1, assuming that updates to C incur a cache miss due to false sharing when consecutive elements are in a row (i.e., index i) are updated.Exercise 7.6.1Assume that we are going to compute C on both a single core shared memory machine and a 4-core shared-memory machine. Compute thespeedup
Describe how we can solve this problem by introducing the concept of a priority? But can we guarantee that we will treat all the philosophers fairly? Explain.The dining philosopher's problem is a classic problem of synchronization and concurrency.The general problem is stated as philosophers
Compare the resiliency to failure of n-cube to a fully- connected interconnection network. Plot a comparison of reliability as a function of the added number of links for the two topologies.Refer to Figure 7.7b that shows an n-cube interconnect topology of order 3 that interconnects 8 nodes. One
Discuss what changes may be necessary in future multi-core CPU platforms in order to better match the resource demands placed on these systems. For instance, can multi-threading play an effective role in alleviating the competition for computing resources?Virtualization software is being
How could you make the execution more deterministic so that only one set of values is possible?Consider the following portions of two different programs running at the same time on four processors in a symmetric multi-core processor (SMP). Assume that before this code is run, both x and y are 0.
For an 8-wide SIMD machine (i.e., 8 parallel SIMD functional units), write an assembly program in using your own SIMD extensions to MIPS to execute the loop. Compare the number of instructions executed on the SIMD machine to the MIMD machine.We would like to execute the loop below as efficiently as
If each directory entry maintains a byte of information for each CPU, if our CC-NUMA system has S memory blocks, and the system has T nodes, provide an equation that expresses the amount of memory that will be present in each directory.In a CC-NUMA shared memory system, CPUs and physical memory are
In terms of the Rooline Model, how dependent will the results you obtain when running these benchmarks be on the amount of sharing and synchronization present in the workload used?Benchmarking is field of study that involves identifying representative workloads to run on specific computing
Discuss the similarities and differences between an MISD and SIMD machine. Answer this question in terms of data-level parallelism.A systolic array is an example of an MISD machine. A systolic array is a pipeline network or "wavefront" of data processing elements. Each of these elements does not
For a directory-based coherency mechanism, describe the internode traffic generated when executing the same code pattern.Considering the CC-NUMA system described in the Exercise 7.8, assume that the system has 4 nodes, each with a single-core CPU (each CPU has its own L1 data cache and L2 data
Next, consider which of the activities could be carried out concurrently (e.g., eating breakfast and listening to the news). For each of your activities, describe which other activity could be paired with this activity.First, write down a list of your daily activities that you typically do on a
When an instruction in a later iteration of a loop depends upon a data value produced in an earlier iteration of the same loop, we say that there is a loop carried dependence between iterations of the loop. Identify the loop- carried dependences in the above code. Identify the dependent program
If you have GPU hardware available, complete a performance analysis your program, examining the computation time for the GPU and a CPU version of your program for a range of vector sizes. Explain any results you see.Download the CUDA Toolkit and SDK from http://www.nvidia.com/object/cuda_ get.html.
Next, assume that Y is equal to N. How would this affect your conclusions in your previous answer? If you were tasked with obtaining the best speedup factor possible (i.e., strong scaling), explain how you might change thiscode to obtain it.Many computer applications involve searching through a set
Next, assume that Y is equal to length(m). How would this affect your conclusions your previous answer? If you were tasked with obtaining the best speedup factor possible (i.e., strong scaling), explain how you might change this code to obtain it.Consider the following recursive mergesort algorithm
If on average we need to access memory once every 50 cycles, what is impact on our application?On a CC-NUMA system, the cost of accessing non-local memory can limit our ability to utilize multiprocessing effectively. The following table shows the costs associated with access data in local memory
Assume now that you have three bowls, 3 cake pans and 3 mixers. How much faster is the process now that you have additional resources?You are trying to bake 3 blueberry pound cakes. Cake ingredients are as follows:1 cup butter, softened1 cup sugar4 large eggs1 teaspoon vanilla extract1/2 teaspoon
Does the CPU relinquish control of memory when DMA is active? For example, can a peripheral simply communicate with memory directly, avoiding the CPU completely?Direct Memory Access (DMA) allows devices to access memory directly rather than working through the CPU. This can dramatically speed up
Repeat 6.19.2 for a large disk farm operated by an online backup company. Does upgrading to either RAID 0 or RAID 1 make economic sense given that your income model is based on the availability of your server?Exercise 6.19.2Given that your company operates a global search engine with a large disk
Competing vendors for the systems you identified in 6.20.2 have offered to allow you to evaluate their systems on site. Identify the benchmarks you will use to determine which system is best for your application. Determine how long it will take you to gather enough data to make your
We can implement requests to the waiter as either a queue of requests or as a periodic retry of a request. With a queue, requests are handled in the order they are received. The problem with using the queue is that we may not always be able to service the philosopher whose request is at the head of
How would you ix the false sharing issue that can occur?Matrix multiplication plays an important role in a number of applications. Two matrices can only be multiplied if the number of columns of the first matrix is equal to the number of rows in the second.Let’s assume we have an m × n matrix A
The latency of the interconnect network plays a large role in the efficiency of message passing systems. How fast does the interconnect need to be in order to obtain any speedup from using the distributed system described in 7.3.3?Exercise 7.3.3Loop unrolling was described in Chapter 4. Apply loop
Compare the cake-making task to computing 3 iterations of a loop on a parallel computer. Identify data-level parallelism and task-level parallelism in the cake-making loop.You are trying to bake 3 blueberry pound cakes. Cake ingredients are as follows:1 cup butter, softened1 cup sugar4 large eggs1
Estimate how much shorter time it would take to carry out these activities if you tried to carry out as many tasks in parallel as possible.First, write down a list of your daily activities that you typically do on a weekday. For instance, you might get out of bed, take a shower, get dressed, eat
Assume now that you have two friends that will help you cook, and that you have a large oven that can accommodate all three cakes. How will this change the schedule you arrived at in 7.5.1 above?You are trying to bake 3 blueberry pound cakes. Cake ingredients are as follows:1 cup butter, softened1
Showing 300 - 400
of 1073
1
2
3
4
5
6
7
8
9
10
11
Step by Step Answers
















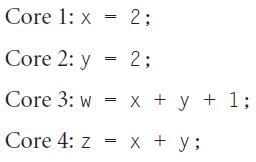
![for (i=0; i < 2000; i++) for (j=0; j <3000; j++) X_array[i][j] = Y_array[j][i] + 200;](https://dsd5zvtm8ll6.cloudfront.net/images/question_images/1698/3/9/4/330653b70dacb3f71698394330364.jpg)
![for (i=0; i < 2000; i++) for (j=0; j <3000; j++) X_array[i][j] = Y_array[j][i] + 200;](https://dsd5zvtm8ll6.cloudfront.net/images/question_images/1698/3/9/4/921653b7329c5da81698394921376.jpg)


![Binary Search (A[0..N-1], X) { low = 0 high = N - 1 while (low X) high else if (A[mid] < X) low = mid + 1 }](https://dsd5zvtm8ll6.cloudfront.net/images/question_images/1698/3/8/7/860653b57945b3cf1698387859891.jpg)



![for (j 2; j <1000; j++) D[j] = D[j-1]+D[j-2]; The MIPS code corresponding to the above fragment is: r2,r2,999](https://dsd5zvtm8ll6.cloudfront.net/images/question_images/1698/3/8/7/949653b57ed70e431698387949111.jpg)