New Semester
Started
Get
50% OFF
Study Help!
--h --m --s
Claim Now
Question Answers
Textbooks
Find textbooks, questions and answers
Oops, something went wrong!
Change your search query and then try again
S
Books
FREE
Study Help
Expert Questions
Accounting
General Management
Mathematics
Finance
Organizational Behaviour
Law
Physics
Operating System
Management Leadership
Sociology
Programming
Marketing
Database
Computer Network
Economics
Textbooks Solutions
Accounting
Managerial Accounting
Management Leadership
Cost Accounting
Statistics
Business Law
Corporate Finance
Finance
Economics
Auditing
Tutors
Online Tutors
Find a Tutor
Hire a Tutor
Become a Tutor
AI Tutor
AI Study Planner
NEW
Sell Books
Search
Search
Sign In
Register
study help
computer science
computer organization design
Computer Organization And Design The Hardware Software Interface 4th Revised Edition David A. Patterson, John L. Hennessy - Solutions
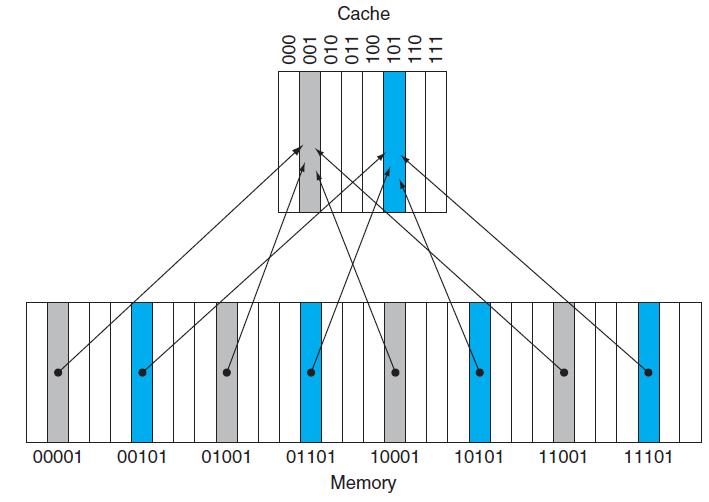
For each of these references, identify the binary address, the tag, and the index given a direct-mapped cache with two-word blocks and a total size of 8 blocks. Also list if each reference is a hit or a miss, assuming the cache is initially empty.Caches are important to providing a high-performance
How many entries does the cache have?For a direct-mapped cache design with a 32-bit address, the following bits of the address are used to access the cache. a. b. Tag 31-10 31-12 Index 9-5 11-6 Offset 4-0 5-0
Describe the procedure of handling an L1 write-miss, considering the component involved and the possibility of replacing a dirty block.Recall that we have two write policies and write allocation policies, and their combinations can be implemented either in L1 or L2 cache. L1 a. Write through,
Re-compute the miss rate when the cache line size is 16 bytes, 64 bytes, and 128 bytes. What kind of locality is this workload exploiting?Media applications that play audio or video files are part of a class of workloads called “streaming” workloads; i.e., they bring in large amounts of data
Using the references from Exercise 5.3, show the final cache contents for a fully associative cache with one-word blocks and a total size of 8 words. Use LRU replacement. For each reference identify the index bits, the tag bits, and if it is a hit or a miss.This exercise examines the impact of
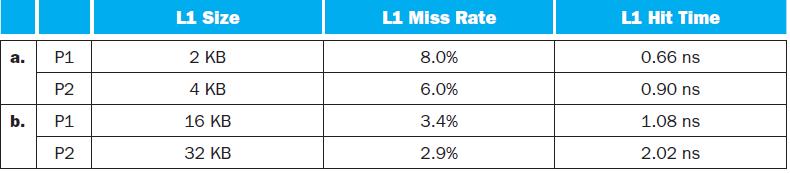
What is the AMAT for P1 and P2? In this exercise, we will look at the different ways capacity affects overall performance. In general, cache access time is proportional to capacity. Assume that main memory accesses take 70 ns and that memory accesses are 36% of all instructions. The following
Design a memory hierarchy for the system. Show the typical size and latency at various levels of the hierarchy. What is the relationship between cache size and its access latency?In this exercise we consider memory hierarchies for various applications, listed in the following table. a. Software
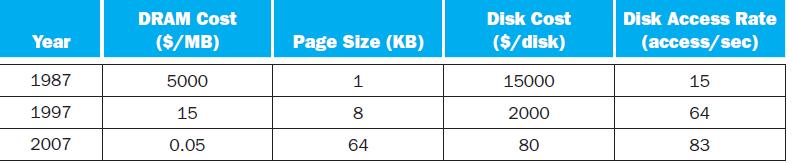
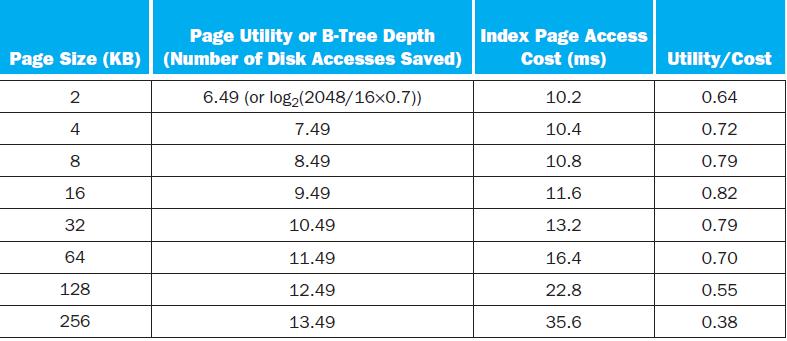
Based on 5.9.1, what is the best page size if pages are half full?Exercise 5.9.1What is the best page size if entries now become 128 bytes?For a high-performance system such as a B-tree index for a database, the page size is determined mainly by the data size and disk performance. Assume that on
References to which variables exhibit temporal locality?In this exercise we look at memory locality properties of matrix computation. The following code is written in C, where elements within the same row are stored contiguously. a. b. for (I=0; I
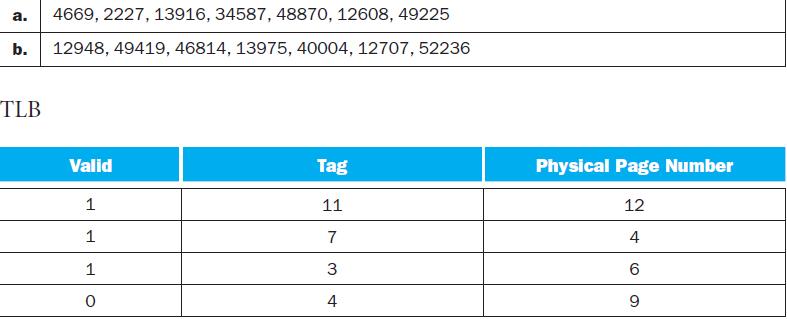
Repeat Exercise 5.10.1, but this time use 16 KB pages instead of 4 KB pages. What would be some of the advantages of having a larger page size? What are some of the disadvantages?Exercise 5.10.1Given the address stream in the table, and the initial TLB and page table states shown above, show the
Using a multilevel page table can reduce the physical memory consumption of page tables, by only keeping active PTEs in physical memory. How many levels of page tables will be needed in this case? And how many memory references are needed for address translation if missing in TLB?In this exercise,
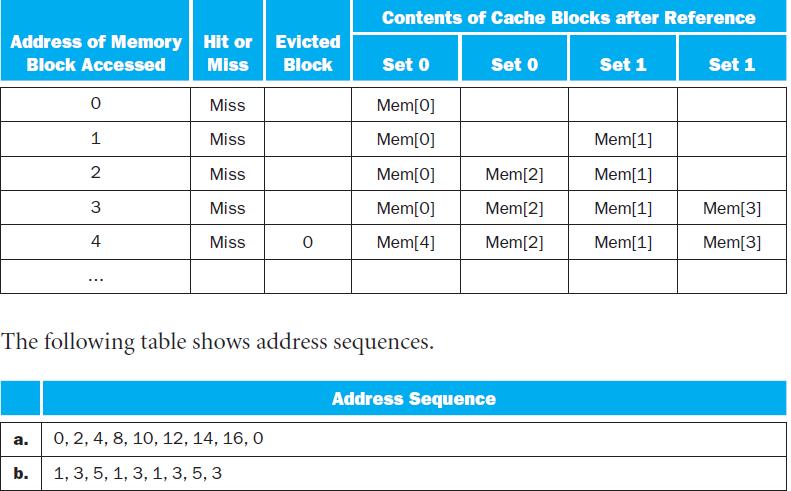
Assuming an MRU (most recently used) replacement policy, how many hits does this address sequence exhibit?In this exercise, we will examine how replacement policies impact miss rate. Assume a 2-way set associative cache with 4 blocks. You may find it helpful to draw a table like those found on page
Assuming an x86-based 4-level page table in both guest and nested page table, how many memory references are needed to service a TLB miss for native vs. nested page table?To support multiple virtual machines, two levels of memory virtualization are needed. Each virtual machine still controls the
I/O accesses often have a large impact on overall system performance. Calculate the CPI of a machine using the performance characteristics above, assuming a non-virtualized system. Calculate the CPI again, this time using a virtualized system. How do these CPIs change if the system has half the I/O
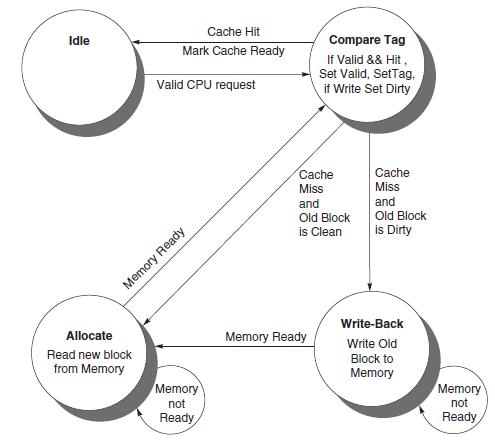
What should happen if the processor issues a request that misses in the cache while a block is being written back to main memory from the write buffer?In this exercise, we will explore the control unit for a cache controller for a processor with a write buffer. Use the inite state machine found in
What are the best-case and worst-case numbers of cache misses needed to execute the listed read/write instructions?Cache coherence concerns the views of multiple processors on a given cache block. The following table shows two processors and their read/write operations on two different words of a
Discuss the pros and cons of shared vs. private L2 caches for both single-threaded, multi-threaded, and multiprogrammed workloads, and reconsider them if having on-chip L3 caches.Both Barcelona and Nehalem are chip multiprocessors (CMPs), having multiple cores and their caches on a single chip. CMP
You are asked to optimize a cache design for the given references. There are three direct-mapped cache designs possible, all with a total of 8 words of data: C1 has 1-word blocks, C2 has 2-word blocks, and C3 has 4-word blocks. In terms of miss rate, which cache design is the best? If the miss
What is the ratio between total bits required for such a cache implementation over the data storage bits?For a direct-mapped cache design with a 32-bit address, the following bits of the address are used to access the cache. a. b. Tag 31-10 31-12 Index 9-5 11-6 Offset 4-0 5-0
For a multilevel exclusive cache (a block can only reside in one of the L1 and L2 caches), configuration, describe the procedure of handling an L1 write-miss, considering the component involved and the possibility of replacing a dirty block.Recall that we have two write policies and write
“Prefetching” is a technique that leverages predictable address patterns to speculatively bring in additional cache lines when a particular cache line is accessed. One example of prefetching is a stream buffer that prefetches sequentially adjacent cache lines into a separate buffer when a
Assuming a base CPI of 1.0 without any memory stalls, what is the total CPI for P1 and P2? Which processor is faster?In this exercise, we will look at the different ways capacity affects overall performance. In general, cache access time is proportional to capacity. Assume that main memory accesses
Using the references from Exercise 5.3, what is the miss rate for a fully associative cache with two-word blocks and a total size of 8 words, using LRU replacement? What is the miss rate using MRU (most recently used) replacement? Finally what is the best possible miss rate for this cache, given
What are the units of data transfers between hierarchies? What is the relationship between the data location, data size, and transfer latency?In this exercise we consider memory hierarchies for various applications, listed in the following table. a. Software version control b. Making phone calls
Show the final contents of the TLB if it is 2-way set associative. Also show the contents of the TLB if it is direct mapped. Discuss the importance of having a TLB to high performance. How would virtual memory accesses be handled if there were no TLB?Virtual memory uses a page table to track the
References to which variables exhibit spatial locality?In this exercise we look at memory locality properties of matrix computation. The following code is written in C, where elements within the same row are stored contiguously. a. b. for (I=0; I
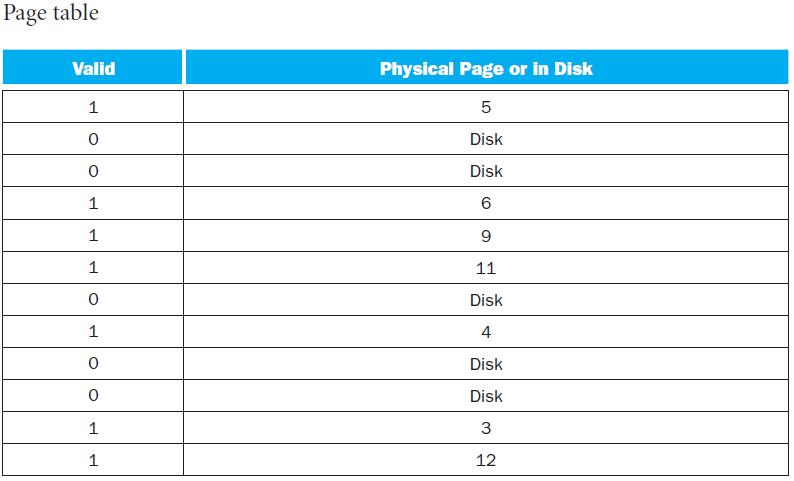
An inverted page table can be used to further optimize space and time. How many PTEs are needed to store the page table? Assuming a hash table implementation, what are the common case and worst case numbers of memory references needed for servicing a TLB miss?In this exercise, we will examine
Simulate a random replacement policy by lipping a coin. For example, “heads” means to evict the first block in a set and “tails” means to evict the second block in a set. How many hits does this address sequence exhibit?In this exercise, we will examine how replacement policies impact miss
Among TLB miss rate, TLB miss latency, page fault rate, and page fault handler latency, which metrics are more important for shadow page table? Which are important for nested page table?To support multiple virtual machines, two levels of memory virtualization are needed. Each virtual machine still
Compare and contrast the ideas of virtual memory and virtual machines. How do the goals of each compare? What are the pros and cons of each? List a few cases where virtual memory is desired, and a few cases where virtual machines are desired.One of the biggest impediments to widespread use of
Design a Finite state machine to enable the use of a write buffer.In this exercise, we will explore the control unit for a cache controller for a processor with a write buffer. Use the inite state machine found in Figure 5.34 as a starting point for designing your own inite state machines. Assume
List the possible values of C and D for an implementation that ensures both consistency assumptions on page 538.Memory consistency concerns the views of multiple data items. The following table shows two processors and their read/write operations on different cache blocks (A and B initially 0).
Assume both benchmarks have a base CPI of 1 (ideal L2 cache). If having non-blocking cache improves the average number of concurrent L2 misses from 1 to 2, how much performance improvement does this provide over a shared L2 cache? How much improvement can be achieved over private L2?Both Barcelona
Calculate the total number of bits required for the cache listed in the table, assuming a 32-bit address. Given that total size, find the total size of the closest direct-mapped cache with 16-word blocks of equal size or greater. Explain why the second cache, despite its larger data size, might
How many blocks are replaced?Starting from power on, the following byte-addressed cache references are recorded. Address O 4 16 132 232 160 1024 30 140 3100 180 2180
For a write-through, write-allocate cache, what are the minimum read and write bandwidths (measured by byte per cycle) needed to achieve a CPI of 2?Consider the following program and cache behaviors. a. b. Data Reads per 1000 Instructions 250 200 Data Writes per 1000
For 64 KB data caches with varying set associativities, what are the miss rates broken down by miss types (cold, capacity, and conflict misses) for each benchmark?For the problems below, use data from "Cache Performance for SPEC CPU2000 Benchmarks"
What is the optimal block size for a miss latency of 20×B cycles?Cache block size (B) can affect both miss rate and miss latency. Assuming a 1-CPI machine with an average of 1.35 references (both instruction and data) per instruction, help find the optimal block size given the following miss rates
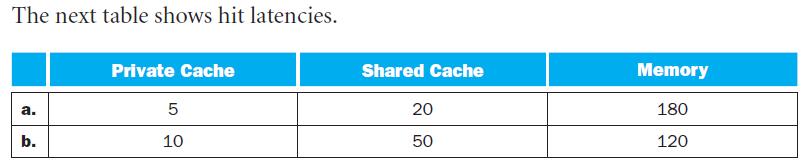
What is the AMAT for P1 with the addition of an L2 cache? Is the AMAT better or worse with the L2 cache?For the next three problems, we will consider the addition of an L2 cache to P1 to presumably make up for its limited L1 cache capacity. Use the L1 cache capacities and hit times from the
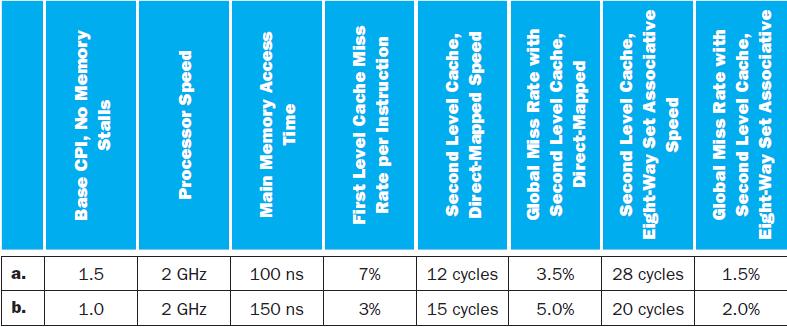
Calculate the CPI for the processor in the table using: 1) only a first level cache, 2) a second level direct-mapped cache, and 3) a second level eight way set associative cache. How do these numbers change if main memory access time is doubled? If it is cut in half?Multilevel caching is an
How many 16-byte cache lines are needed to store all 32-bit matrix elements being referenced?Locality is affected by both the reference order and data layout. The same computation can also be written below in Matlab, which differs from C by contiguously storing matrix elements within the same
Repeat 4.24.4, but now your predictor should be able to eventually (after a warm-up period during which it can make wrong predictions) start perfectly predicting both this pattern and its opposite. Your predictor should have an input that tells it what the real outcome was.Exercise 4.24.4Design a
What is the speedup achieved by adding this new instruction? In your calculation, assume that the CPI of the original program (without the new instruction) is 1.The last problem in this exercise assumes that each use of the new instruction replaces the given number of original instructions, that
In the rest of this exercise, we assume that the following basic digital logic elements are available, and that their latency and cost are as follows:The time given for a D-element is its setup time. The data input of a lip-lop must have the correct value one setup-time before the clock edge (end
What is the speedup of executing branches 1 stage earlier in an 8-issue processor? Discuss the difference between this result and the result from 4.32.5.Exercise 4.32.5What is the speedup of executing branches 1 stage earlier in a 4-issue processor?The remaining problems in this exercise assume the
What should the branch prediction accuracy be if we are willing to have a speedup of 0.5 (one half) relative to the same processor with an ideal branch predictor?For the remaining three problems in this exercise, unless the problem specifies otherwise, assume the following statistics about what
At the start of the cycle in which we fetch the first instruction of the third iteration of this loop, what is stored in the IF/ID register?The remaining three problems in this exercise refer to the following loop. Assume that perfect branch prediction is used (no stalls due to control hazards),
Repeat 4.34.3 for your extended datapath from 4.34.4.Exercise 4.34.3What needs to be done to support undeined instruction exceptions in your datapath from 4.34.1? Note that the undeined instruction exception should be triggered whenever the processor encounters any other kind of instruction. The
Calculate the CPI for the system listed above assuming that there are no accesses to I/O. What is the CPI if the VMM performance impact doubles? If it is cut in half? If a virtual machine software company wishes to obtain a 10% performance degradation, what is the longest possible penalty to trap
Communication bandwidth and server processing bandwidth are two important factors to consider when designing a memory hierarchy. How can the bandwidths be improved? What is the cost of improving them?In this exercise we consider memory hierarchies for various applications, listed in the following
What are the reuse time thresholds for these three technology generations?Keeping "frequently used" (or "hot") pages in DRAM can save disk accesses, but how do we determine the exact meaning of "frequently used" for a given system? Data engineers use the cost ratio between DRAM and disk access to
Given the parameters in the table above, calculate the total page table size for a system running 5 applications that utilize half of the memory available.There are several parameters that impact the overall size of the page table. Listed below are several key page table parameters. a. b. Virtual
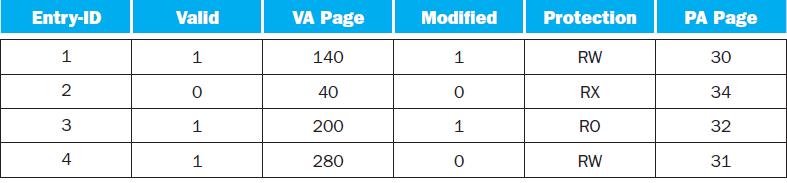
Under what scenarios would entry 2’s valid bit be set to zero?The following table shows the contents of a 4-entry TLB. Entry-ID 1 2 3 4 Valid 1 0 1 1 VA Page 140 40 200 280 Modified 1 0 1 0 Protection RW RX RO RW PA Page 30 34 32 31
Which address should be evicted at each replacement to maximize the number of hits? How many hits does this address sequence exhibit if you follow this “optimal” policy?In this exercise, we will examine how replacement policies impact miss rate. Assume a 2-way set associative cache with 4
Discusses virtualization under the assumption that the virtualized system is running the same ISA as the underlying hardware. However, one possible use of virtualization is to emulate non-native ISAs. An example of this is QEMU, which emulates a variety of ISAs such as MIPS, SPARC, and PowerPC.
For a benchmark with native execution CPI of 1, what are the CPI numbers if using shadow page tables vs. NPT (assuming only page table virtualization overhead)?The following table shows parameters for a shadow paging system. TLB Misses per 1000 Instructions 0.2 NPT TLB Miss Latency 200 cycles Page
Assume new generations of processors double the number of cores every 18 months. To maintain the same level of per-core performance, how much more off-chip memory bandwidth is needed for a 2012 processor?Both Barcelona and Nehalem are chip multiprocessors (CMPs), having multiple cores and their
List at least one more possible pair of values for C and D if such assumptions are not maintained.Memory consistency concerns the views of multiple data items. The following table shows two processors and their read/write operations on different cache blocks (A and B initially 0). a. b. A A = 1;
Generate a series of read requests that have a lower miss rate on a 2 KB 2-way set associative cache than the cache listed in the table. Identify one possible solution that would make the cache listed in the table have an equal or lower miss rate than the 2 KB cache. Discuss the advantages and
What is the hit ratio?Starting from power on, the following byte-addressed cache references are recorded. Address O 4 16 132 232 160 1024 30 140 3100 180 2180
Select the set associativity to be used by a 64 KB L1 data cache shared by both benchmarks. If the L1 cache has to be directly mapped, select the set associativity for the 1 MB L2 cache.For the problems below, use data from "Cache Performance for SPEC CPU2000 Benchmarks"
For a write-back, write-allocate cache, assuming 30% of replaced data cache blocks are dirty, what are the minimal read and write bandwidths needed for a CPI of 2?Consider the following program and cache behaviors. a. b. Data Reads per 1000 Instructions 250 200 Data Writes per 1000
What is the optimal block size for a miss latency of 24+B cycles?Cache block size (B) can affect both miss rate and miss latency. Assuming a 1-CPI machine with an average of 1.35 references (both instruction and data) per instruction, help find the optimal block size given the following miss rates
Assuming a base CPI of 1.0 without any memory stalls, what is the total CPI for P1 with the addition of an L2 cache?For the next three problems, we will consider the addition of an L2 cache to P1 to presumably make up for its limited L1 cache capacity. Use the L1 cache capacities and hit times from
It is possible to have an even greater cache hierarchy than two levels. Given the processor above with a second level, direct-mapped cache, a designer wants to add a third level cache that takes 50 cycles to access and will reduce the global miss rate to 1.3%. Would this provide better performance?
What are the reuse time thresholds if we keep using the same 4K page size? What’s the trend here?Keeping "frequently used" (or "hot") pages in DRAM can save disk accesses, but how do we determine the exact meaning of "frequently used" for a given system? Data engineers use the cost ratio between
Now consider multiple clients simultaneously accessing the server. Will such scenarios improve the spatial and temporal locality?In this exercise we consider memory hierarchies for various applications, listed in the following table. a. Software version control b. Making phone calls
Given the parameters in the table above, calculate the total page table size for a system running 5 applications that utilize half of the memory available, given a two level page table approach with 256 entries. Assume each entry of the main page table is 6 bytes. Calculate the minimum and maximum
References to which variables exhibit temporal locality?Locality is affected by both the reference order and data layout. The same computation can also be written below in Matlab, which differs from C by contiguously storing matrix elements within the same column. a. b. for I-1:8 for
What happens when an instruction writes to VA page 30? When would a software managed TLB be faster than a hardware managed TLB?The following table shows the contents of a 4-entry TLB. Entry-ID 1 2 3 4 Valid 1 0 1 1 VA Page 140 40 200 280 Modified 1 0 1 0 Protection RW RX RO RW PA Page 30 34 32 31
Describe why it is difficult to implement a cache replacement policy that is optimal for all address sequences.In this exercise, we will examine how replacement policies impact miss rate. Assume a 2-way set associative cache with 4 blocks. You may find it helpful to draw a table like those found on
What techniques can be used to reduce page table shadowing induced overhead?The following table shows parameters for a shadow paging system. TLB Misses per 1000 Instructions 0.2 NPT TLB Miss Latency 200 cycles Page Faults per 1000 Instructions 0.001 Shadowing Page Fault Overhead 30,000 cycles
For various combinations of write policies and write allocation policies, which combinations make the protocol implementation simpler?Memory consistency concerns the views of multiple data items. The following table shows two processors and their read/write operations on different cache blocks (A
Consider the entire memory hierarchy. What kinds of optimizations can improve the number of concurrent misses?Both Barcelona and Nehalem are chip multiprocessors (CMPs), having multiple cores and their caches on a single chip. CMP on-chip L2 cache design has interesting trade-offs. The following
What is inherently different between these two classes of workload when run on these multi-core systems?Benchmarking is field of study that involves identifying representative workloads to run on specific computing platforms in order to be able to objectively compare performance of one system to
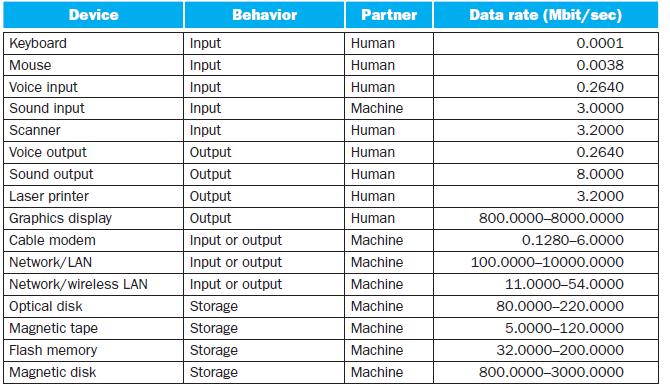
Of the peripherals listed in the table, which could cause coherency problems with cache contents? What criteria determine if coherency issues must be addressed?Direct Memory Access (DMA) allows devices to access memory directly rather than working through the CPU. This can dramatically speed up the
Calculate the MTBF for each of the devices in the table.Mean Time Between Failures (MTBF), Mean Time To Replacement (MTTR), and Mean Time To Failure (MTTF) are useful metrics for evaluating the reliability and availability of a storage resource. Explore these concepts by answering the questions
Outline how an interrupt from each of the devices listed in the table would be handled.Section 6.6 defines an eight-step process for handling interrupts. The Cause and Status registers together provide information on the cause of the interrupt and the status of the interrupt handling system.
Given that your company operates a global search engine with a large disk farm, does upgrading to either RAID 0 or RAID 1 make economic sense given that your income model is based on the number of advertisements served?For disks in the table in Exercise 6.18, assume that your vendor offers a RAID 0
For the devices listed in the table, identify I/O interfaces and classify them in terms of their behavior and partner.Figure 6.2 describes numerous I/O devices in terms of their behavior, partner, and data rate. However, these classifications often do not provide a complete picture of data low
Configure the Sun Fire x4150 to provide 10 terabytes of storage for a processor array of 1000 processors running bioinformatics simulations. Your configuration should minimize power consumption while addressing throughput and availability concerns for the disk array. Make sure you consider the
Given only the original problem parameters, would you recommend upgrading to either RAID 0 or RAID 1 assuming individual disk parameters remain the same in the previous table?For disks in the table in Exercise 6.18, assume that your vendor offers a RAID 0 configuration that will increase storage
Calculate the average time to read or write a 1024-byte sector for each FLASH memory listed in the table.Explore the nature of FLASH memory by answering the questions related to performance for FLASH memories with the following characteristics. a. b. Data Transfer Rate 120 MB/s 100 MB/s Controller
Give an example in the miss rate table where higher set associativity actually increases miss rate. Construct a cache configuration and reference stream to demonstrate this.For the problems below, use data from "Cache Performance for SPEC CPU2000 Benchmarks"
List the inal state of the cache, with each valid entry represented as a record of .Starting from power on, the following byte-addressed cache references are recorded. Address O 4 16 132 232 160 1024 30 140 3100 180 2180
The formula shown on page 457 shows the typical method to index a direct-mapped cache, specifically (Block address) modulo (Number of blocks in the cache). Assuming a 32-bit address and 1024 blocks in the cache, consider a different indexing function, specifically (Block address[31:27] XOR Block
For constant miss latency, what is the optimal block size?Cache block size (B) can affect both miss rate and miss latency. Assuming a 1-CPI machine with an average of 1.35 references (both instruction and data) per instruction, help find the optimal block size given the following miss rates for
What are the minimal bandwidths needed to achieve the performance of CPI=1.5?Consider the following program and cache behaviors. a. b. Data Reads per 1000 Instructions 250 200 Data Writes per 1000 Instructions 100 100 Instruction Cache Miss Rate 0.30% 0.30% Data Cache Miss Rate 2% 2% Block
Which processor is faster, now that P1 has an L2 cache? If P1 is faster, what miss rate would P2 need in its L1 cache to match P1’s performance? If P2 is faster, what miss rate would P1 need in its L1 cache to match P2’s performance?For the next three problems, we will consider the addition of
In older processors such as the Intel Pentium or Alpha 21264, the second level of cache was external (located on a different chip) from the main processor and the irst level cache. While this allowed for large second level caches, the latency to access the cache was much higher, and the bandwidth
Give an example of where the cache can provide out-of-date data. How should the cache be designed to mitigate or avoid such issues?In this exercise we consider memory hierarchies for various applications, listed in the following table. a. Software version control b. Making phone calls
What other factors can be changed to keep using the same page size (thus avoiding software rewrite)? Discuss their likeliness with current technology and cost trends.Keeping "frequently used" (or "hot") pages in DRAM can save disk accesses, but how do we determine the exact meaning of "frequently
References to which variables exhibit spatial locality?Locality is affected by both the reference order and data layout. The same computation can also be written below in Matlab, which differs from C by contiguously storing matrix elements within the same column. a. b. for I-1:8 for J-1:8000 A(I,J)
A cache designer wants to increase the size of a 4 KB virtually indexed, physically tagged cache. Given the page size listed in the table above, is it possible to make a 16 KB direct-mapped cache, assuming 2 words per block? How would the designer increase the data size of the cache?There are
What happens when an instruction writes to VA page 200?The following table shows the contents of a 4-entry TLB. Entry-ID 1 2 3 4 Valid 1 0 1 1 VA Page 140 40 200 280 Modified 1 0 1 0 Protection RW RX RO RW PA Page 30 34 32 31
Assume you could make a decision upon each memory reference whether or not you want the requested address to be cached. What impact could this have on miss rate?In this exercise, we will examine how replacement policies impact miss rate. Assume a 2-way set associative cache with 4 blocks. You may
What techniques can be used to reduce NPT induced overhead?The following table shows parameters for a shadow paging system. TLB Misses per 1000 Instructions 0.2 NPT TLB Miss Latency 200 cycles Page Faults per 1000 Instructions 0.001 Shadowing Page Fault Overhead 30,000 cycles
Calculate annual failure rate (AFR) for disks in the table.Measurements and statistics provided by storage vendors must be carefully interpreted to gain meaningful predictions about their system behavior. The following table provides data for various disk drives. a. b. # of
As we move towards solid state drives constructed from FLASH memory, what will change about disk read times assuming that the data transfer rate stays constant?FLASH memory is one of the first true competitors for traditional disk drives. Explore the implications of FLASH memory by answering
What would be the most appropriate bus type (synchronous or asynchronous) for handling communications between a CPU and the peripherals listed in the table?I/O can be performed either synchronously or asynchronously. Explore the differences by answering performance questions about the following
Showing 200 - 300
of 1073
1
2
3
4
5
6
7
8
9
10
11
Step by Step Answers





![a. b. for (I=0; I <8; I++) for (J-0; J <8000; J++) A[I] [J] B[I][0]+A[J][I]; for (J-0; J <8000; J++) for](https://dsd5zvtm8ll6.cloudfront.net/images/question_images/1698/3/1/6/038653a3f06eb7821698316036991.jpg)


![a. b. X[0] ++ X[1] X[0] =10; X[1] = P1 3; = 3; X[0] X[0] = = P2 5; X[1] +=2; 5; X[1] +=2;](https://dsd5zvtm8ll6.cloudfront.net/images/question_images/1698/3/2/2/966653a5a16238741698322965852.jpg)














![a. b. ADD Rd, Rs. Rt ADDI Rt. Rs. Imm Reg[Rd]-Reg[Rs]+Reg[Rt] Reg[Rt]-Reg[Rs]+[mm](https://dsd5zvtm8ll6.cloudfront.net/images/question_images/1699/3/3/4/5736549c9ad2e3dd1699334573295.jpg)
![a. b. Instruction AND Rd, Rs. Rt SW Rt.Offs (Rs) Interpretation Reg[Rd]-Reg[Rs] AND Reg[Rt] Mem[Reg[Rs]+Offs]](https://dsd5zvtm8ll6.cloudfront.net/images/question_images/1699/3/3/4/5366549c988950481699334536710.jpg)