New Semester
Started
Get
50% OFF
Study Help!
--h --m --s
Claim Now
Question Answers
Textbooks
Find textbooks, questions and answers
Oops, something went wrong!
Change your search query and then try again
S
Books
FREE
Study Help
Expert Questions
Accounting
General Management
Mathematics
Finance
Organizational Behaviour
Law
Physics
Operating System
Management Leadership
Sociology
Programming
Marketing
Database
Computer Network
Economics
Textbooks Solutions
Accounting
Managerial Accounting
Management Leadership
Cost Accounting
Statistics
Business Law
Corporate Finance
Finance
Economics
Auditing
Tutors
Online Tutors
Find a Tutor
Hire a Tutor
Become a Tutor
AI Tutor
AI Study Planner
NEW
Sell Books
Search
Search
Sign In
Register
study help
computer science
computer organization design
Computer Organization And Design The Hardware Software Interface 4th Revised Edition David A. Patterson, John L. Hennessy - Solutions
With the 2-bit predictor, what speedup would be achieved if we could convert half of the branch instructions in a way that replaces a branch instruction with an ALU instruction? Assume that correctly and incorrectly predicted instructions have the same chance of being replaced.The importance of
Given these pipeline stage latencies, repeat the speedup calculation from 4.14.2, but take into account the (possible) change in clock cycle time. When EX and MEM are done in a single stage, most of their work can be done in parallel. As a result, the resulting EX/MEM stage has a latency that is
What CPI would be achieved if the MIPS version of this loop is executed on a 1-issue processor with dynamic scheduling? Assume that our processor is not doing register renaming, so you can only reorder instructions that have no data dependences.Problems in this exercise refer to the following loop,
Design a predictor that would achieve a perfect accuracy if this pattern is repeated forever. You predictor should be a sequential circuit with one output that provides a prediction (1 for taken, 0 for not taken) and no inputs other than the clock and the control signal that indicates that the
Give an example of where this instruction might be useful and a sequence of existing MIPS instructions that are replaced by this instruction.In this exercise, we examine how the ISA affects pipeline design. Problems in this exercise refer to the following new instruction: a. b. ADDM Rd, Rt+Offs
What is the cycle time for the circuit you designed in 4.5.2? What is the speedup achieved by using this circuit instead of the one from 4.5.1 for a 32-bit operation?Problem 4.5.1Design a circuit with 1-bit data inputs and a 1-bit data output that accomplishes this operation serially, starting with
What is the speedup achieved by changing the processor from 4-issue to 8-issue? Assume that the 8-issue and the 4-issue processor differ only in the number of instructions per cycle, and are otherwise identical (pipeline depth, branch resolution stage, etc.).The remaining problems in this exercise
If we have the given fraction of branch instructions and branch prediction accuracy, what percentage of all cycles are entirely spent fetching wrong-path instructions? Ignore the performance loss number.For the remaining three problems in this exercise, unless the problem specifies otherwise,
Show a pipeline execution diagram for the third iteration of this loop, from the cycle in which we fetch the first instruction of that iteration up to (but not including) the cycle in which we can fetch the first instruction of the next iteration. Show all instructions that are in the pipeline
What is the address of the exception handler in 4.25.3? What happens if there is an invalid instruction at that address in instruction memory?Exercise 4.25.3If the second instruction from this table is fetched right after the instruction from the first table, describe what happens in the pipeline
Describe how to extend your datapath from 4.34.1 so it can also support this instruction. Your extended datapath should be designed to only support instances of these two instructions.Exercise 4.34.1Describe a pipelined datapath needed to support only this instruction. Your datapath should be
Translate this C loop into MIPS instructions, assuming that our ISA requires one delay slot for every branch. Try to ill delay slots with non-NOP instructions when possible. You can assume that variables a, b, c, i, and j are kept in registers r1, r2, r3, r4, and r5.The remaining four problems in
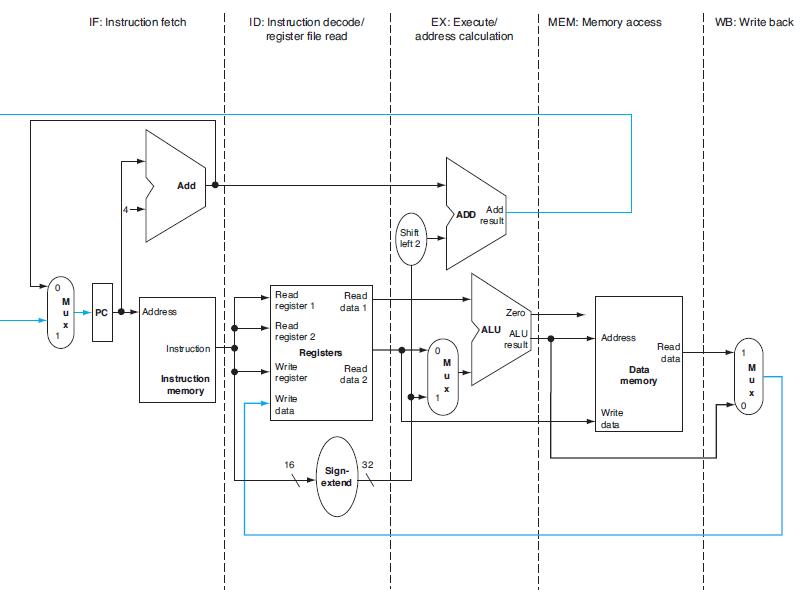
Assuming there are no stalls, what is the speedup achieved by pipelining a single-cycle datapath?Each pipeline stage in Figure 4.33 has some latency. Additionally, pipelining introduces registers between stages, and each of these adds an additional latency. The remaining problems in this exercise
Can we generate exception control signals in EX instead of in ID? Explain how this will work or why it will not work, using the “BNE R4,R5,Label” instruction and these pipeline stage latencies as an example.The remaining three problems in this exercise assume that pipeline stages have the
Given this breakdown of execution cycles in the processor with direct support for the ADDM instruction, what speedup is achieved by replacing this instruction with a 3-instruction sequence (LW, ADD, and then SW)? Assume that the ADDM instruction is somehow (magically) supported with a classical
For which kinds of instructions (if any) is this resource on the critical path?The remaining three problems in this exercise refer to the following logic block (resource) in the datapath: Shift-left-2 b. Registers a. Resource
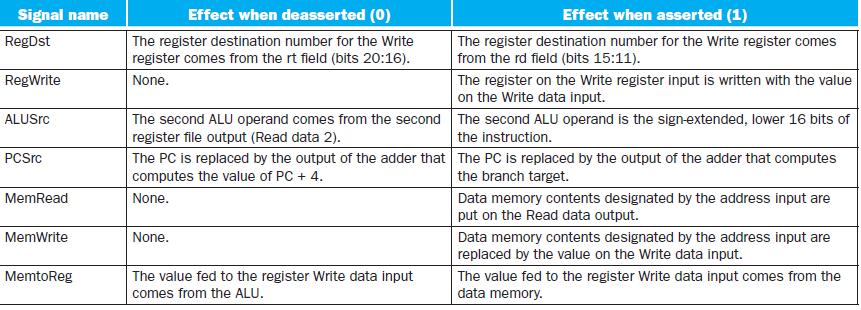
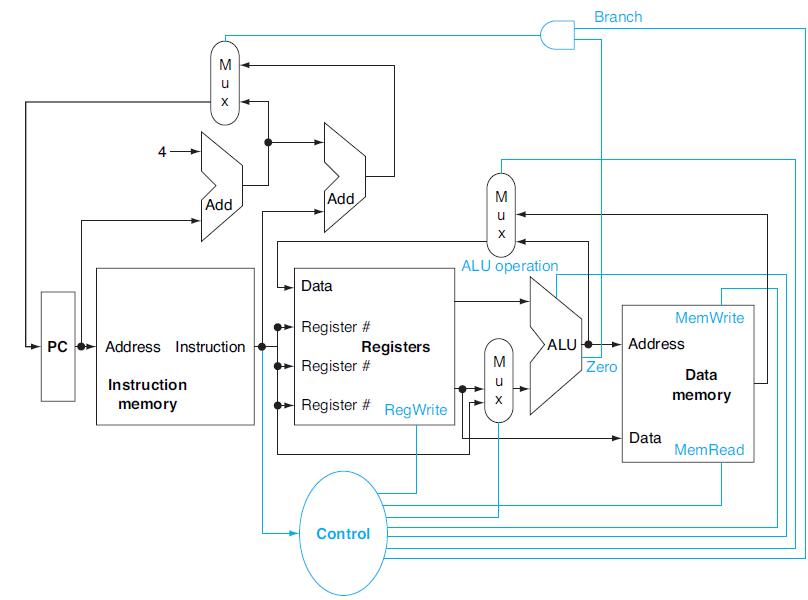
For which MIPS instruction(s) are both of these signals set to 1?The remaining problems in this exercise refer to the following signals from Figure 4.48:Figure 4.48 a. b. Signal 1 ALUSrc Branch Signal 2 PCSrc RegWrite
If LD/ST address computation can overflow, can we delay overflow exception detection into the MEM stage? Use the given store instruction to explain what happens.The remaining three problems in this exercise also refer to the following store instruction: SW b. SW a. R5,-40 (R15) R1,0 (R1) Store
What is the speedup of going from a 1-issue processor to a 2-issue processor from Figure 4.69? Use your code from 4.28.1 for both 1-issue and 2-issue, and assume that 1,000,000 iterations of the loop are executed. As in 4.28.2, assume that the processor has perfect branch predictions, and that a
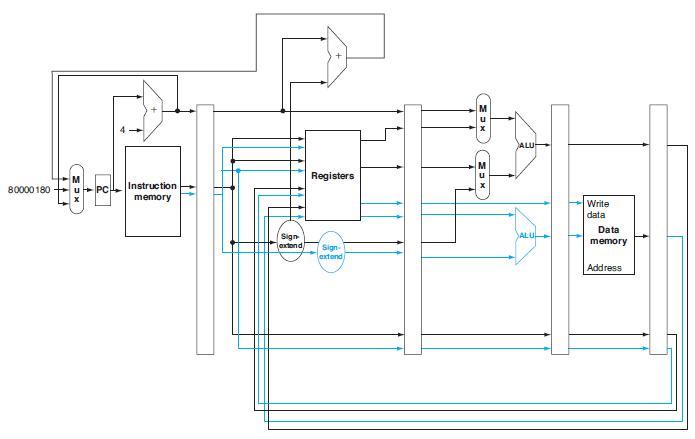
For the ALU and the two add units, what are their data input values?The remaining problems in this exercise assume that data memory is all zeros and that the processor’s registers have the following values at the beginning of the cycle in which the above instruction word is fetched:
What is the critical path for an MIPS load (LD) instruction?Different execution units and blocks of digital logic have different latencies (time needed to do their work). In Figure 4.2 there are seven kinds of major blocks. Latencies of blocks along the critical (longest-latency) path for an
In what fraction of all cycles is the input of the sign-extend circuit needed? What is this circuit doing in cycles in which its input is not needed?For the remaining problems in this exercise, assume that there are no pipeline stalls and that the breakdown of executed instructions is as follows:
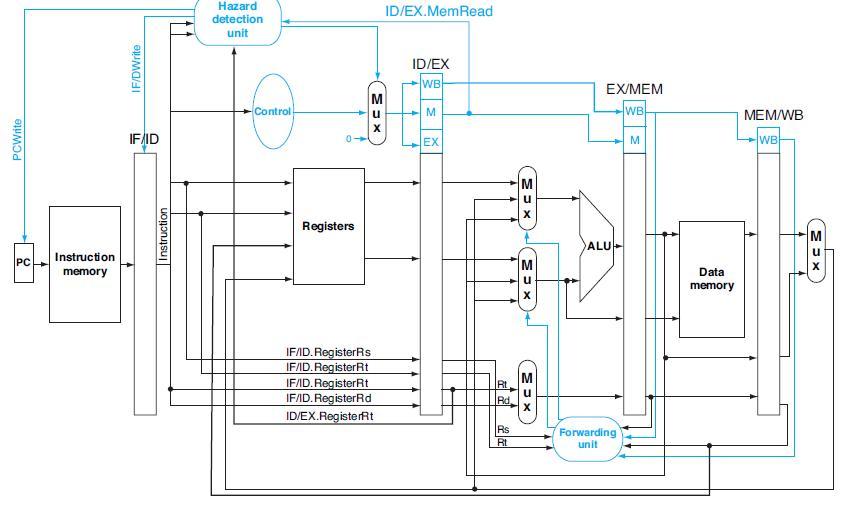
What would be the additional speedup (relative to a processor with forwarding) if we added time-travel forwarding that eliminates all data hazards? Assume that the yet-to-be-invented time-travel circuitry adds 100ps to the latency of the full-forwarding EX stage.The remaining three problems in this
Assuming there are no stalls or hazards, what is the utilization of the write-register port of the “Registers” unit?The remaining problems in this exercise assume that instructions executed by the processor are broken down as follows: a. b. ALU 45% 55% BEQ 20% 15% LW 20% 15% SW 15% 15%
Repeat 4.8.1, but now the fault to test for is whether the “Jump” control signal has this fault.Problem 4.8.1Let us assume that processor testing is done by filling the PC, registers, and data and instruction memories with some values (you can choose which values), letting a single instruction
Repeat 4.37.4, but now assume that we only want to support ADD instructions.Exercise 4.37.4Given these latencies for individual elements of the datapath, compare clock cycle times of the single-cycle and the 5-stage pipelined datapath.The remaining three problems in this exercise assume that
If we assume forwarding will be implemented when we design the hazard detection unit, but then we forget to actually implement forwarding, what are the final register values after this instruction sequence?The remaining three problems in this exercise assume that, before any of the above is
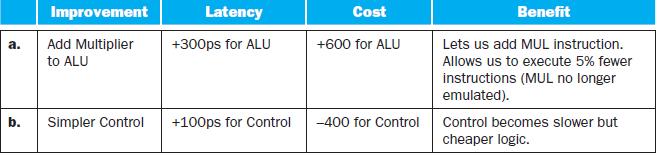
What is the speedup achieved by adding this improvement?When processor designers consider a possible improvement to the processor datapath, the decision usually depends on the cost/performance trade-off. In the following three problems, assume that we are starting with a datapath from Figure 4.2,
We can eliminate the MemRead control signal and have the data memory be read in every cycle, i.e., we can permanently have MemRead=1. Explain why the processor still functions correctly after this change. What is the effect of this change on clock frequency and energy consumption?The remaining
If there is no forwarding, what new inputs and output signals do we need for the hazard detection unit in Figure 4.60? Using this instruction sequence as an example, explain why each signal is needed.This exercise is intended to help you understand the relationship between forwarding, hazard
What is the speedup of using your code from 4.29.4 instead of the original code with a 2-issue static superscalar processor? Assume that the loop has many (e.g., 1,000,000) iterations.Exercise 4.29.4Unroll this loop once and schedule it for a 2-issue static superscalar processor. Assume that the
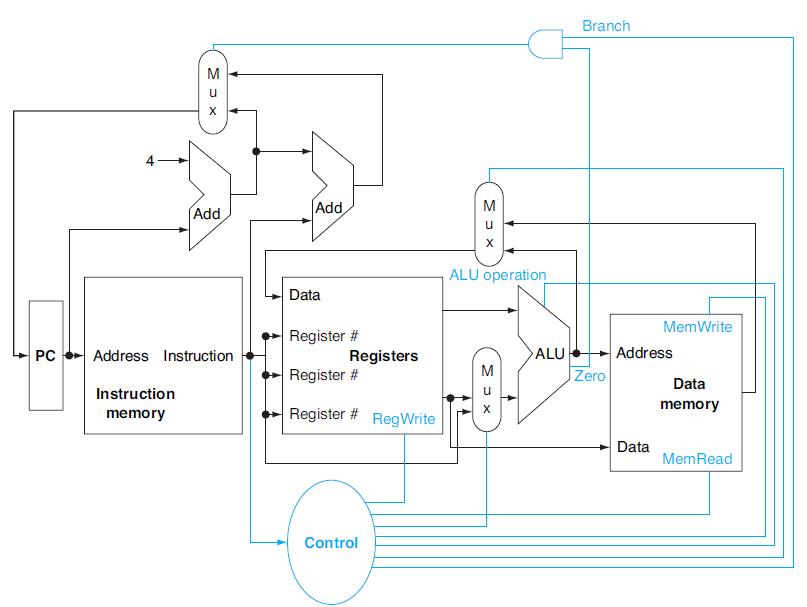
For the datapath from Figure 4.24, draw the logic diagram for the part of the control unit that implements just the first signal. Assume that we only need to support LW, SW, BEQ, ADD, and J (jump) instructions.Different instructions require different control signals to be asserted in the datapath.
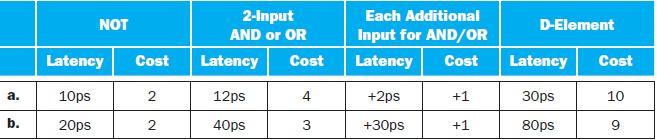
What is the cost of your implementation from 4.3.2?Problem 4.3.2Show how this block can be implemented. Use only AND, OR, NOT, and D Flip-Flops.Cost and latency of digital logic depends on the kinds of basic logic elements (gates) that are available and on the properties of these gates. The
Repeat 4.39.4, but this time the goal is to minimize energy spent per instruction while increasing the clock cycle time by no more than 10%.Exercise 4.39.4It is often possible to sacrifice some speed in a circuit in order to reduce its energy consumption. Assume that we can reduce energy
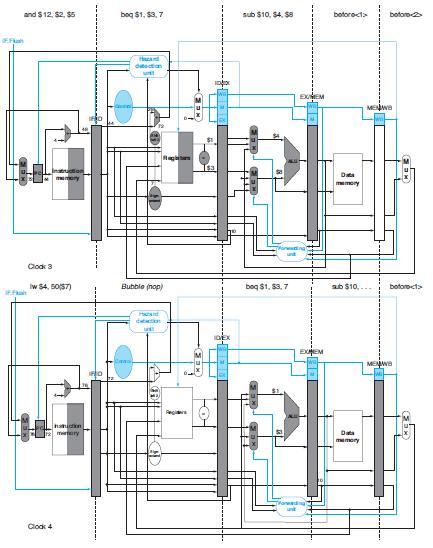
Add NOP instructions to this code to eliminate hazards if there is ALU-ALU forwarding only (no forwarding from the MEM to the EX stage).In this exercise, we examine how data dependences affect execution in the basic 5-stage pipeline described in Section 4.5. Problems in this exercise refer to the
For the given code, what is the speedup achieved by moving branch execution into the ID stage? Explain your answer. In your speedup calculation, assume that the additional comparison in the ID stage does not affect clock cycle time.This exercise is intended to help you understand the relationship
If you can speed up the generation of control signals, but the cost of the entire processor increases by $1 for each 5ps improvement of a single control signal, which control signals would you speed up and by how much to maximize performance? What is the cost (per processor) of this performance
Repeat 4.30.4, but for a 4-issue processor. What conclusion can you draw about the importance of good branch prediction when the issue width of the processor is increased?Exercise 4.30.4For a 2-issue static superscalar processor with a classic 5-stage pipeline, what speedup is achieved by making
With the 2-bit predictor, what speedup would be achieved if we could convert half of the branch instructions in a way that replaced each branch instruction with two ALU instructions? Assume that correctly and incorrectly predicted instructions have the same chance of being replaced.The importance
Given these pipeline stage latencies, repeat the speedup calculation from 4.14.3, taking into account the (possible) change in clock cycle time. Assume that the latency ID stage increases by 50% and the latency of the EX stage decreases by 10ps when branch outcome resolution is moved from EX to
Assuming that there are many free registers available, rename the MIPS version of this loop to eliminate as many data dependences as possible between instructions in the same iteration of the loop. Now repeat 4.31.4, using your new renamed code.Problems in this exercise refer to the following loop,
What is the accuracy of your predictor from 4.24.4 if it is given a repeating pattern that is the exact opposite of this one?Exercise 4.24.4Design a predictor that would achieve a perfect accuracy if this pattern is repeated forever. You predictor should be a sequential circuit with one output that
If this instruction already exists in a legacy ISA, explain how it would be executed in a modern processor like AMD Barcelona.In this exercise, we examine how the ISA affects pipeline design. Problems in this exercise refer to the following new instruction: a. b. ADDM Rd, Rt+Offs (Rs) BEQM Rd, Rt,
Compare cost/performance ratios for the two circuits you designed in 4.5.1 and 4.5.2. For this problem, performance of a circuit is the inverse of the time needed to perform a 32-bit operation.Problem 4.5.1Design a circuit with 1-bit data inputs and a 1-bit data output that accomplishes this
What is the speedup of executing branches 1 stage earlier in a 4-issue processor?The remaining problems in this exercise assume the following pipeline depth and that the branch outcome is determined in the following pipeline stage (counting from stage 1): a. b. Pipeline Depth 15 30 Branch Outcome
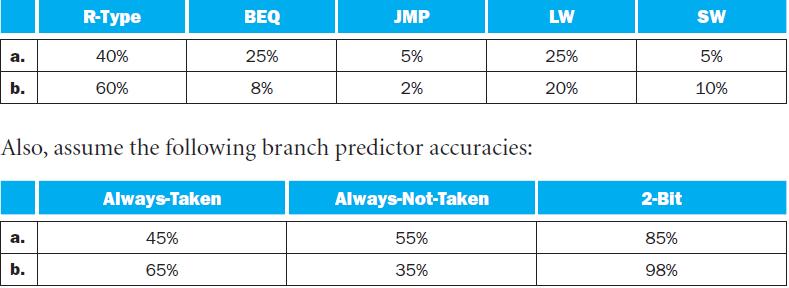
For the remaining three problems in this exercise, unless the problem specifies otherwise, assume the following statistics about what percentage of instructions are branches, predictor accuracy, and performance loss due to branch mispredictions: a. b. Branches as a Fraction of All Executed
How often (as a percentage of all cycles) do we have a cycle in which all five pipeline stages are doing useful work?The remaining three problems in this exercise refer to the following loop. Assume that perfect branch prediction is used (no stalls due to control hazards), that there are no delay
In vectored exception handling, the table of exception handler addresses is in data memory at a known (fixed) address. Change the pipeline to implement this exception handling mechanism. Repeat 4.25.3 using this modified pipeline and vectored exception handling.Exercise 4.25.3If the second
Repeat 4.34.2 for your extended datapath from 4.34.4.Exercise 4.34.2Describe the requirements of forwarding and hazard detection units for your datapath from 4.34.1.What needs to be done to support undefined instruction exceptions in your datapath from 4.34.1? Note that the undefined instruction
Repeat 4.35.4 for a processor that has two delay slots for every branch.Exercise 4.35.4ranslate this C loop into MIPS instructions, assuming that our ISA requires one delay slot for every branch. Try to ill delay slots with non-NOP instructions when possible. You can assume that variables a, b, c,
We can convert all load/store instructions into register-based (no offset) and put the memory access in parallel with the ALU. What is the clock cycle time if this is done in the single-cycle and in the pipelined datapath? Assume that the latency of the new EX/MEM stage is equal to the longer of
Repeat 4.36.5, but now assume that ADDM was supported by adding a pipeline stage. When ADDM is translated, this extra stage can be removed and, as a result, half of the existing data stalls are eliminated. Note that the data stall elimination applies only to stalls that existed before ADDM
Assuming that each Mux has a latency of 40ps, determine how much time does the control unit have to generate the lush signals? Which signal is the most critical?The remaining three problems in this exercise assume that pipeline stages have the following latencies:
One of these signals goes back through the pipeline. Which signal is it? Is this a time-travel paradox? Explain.The remaining problems in this exercise refer to the following signals from Figure 4.48:Figure 4.48 a. b. Signal 1 ALUSrc Branch Signal 2 PCSrc RegWrite
Assuming that we only support BEQ and ADD instructions, discuss how changes in the given latency of this resource affect the cycle time of the processor. Assume that the latencies of other resources do not change.The remaining three problems in this exercise refer to the following logic block
For debugging, it is useful to be able to detect when a particular value is written to a particular memory address. We want to add two new registers, WADDR and WVAL. The processor should trigger an exception when the value equal to WVAL is about to be written to address WADDR. How would you change
Repeat 4.28.5, but this time assume that in the 2-issue processor one of the instructions to be executed in a cycle can be of any kind, and the other must be a non-memory instruction.Exercise 4.28.5What is the speedup of going from a 1-issue processor to a 2-issue processor from Figure 4.69? Use
What are the values of all inputs for the “Registers” unit?The remaining problems in this exercise assume that data memory is all zeros and that the processor’s registers have the following values at the beginning of the cycle in which the above instruction word is fetched:
If we can improve the latency of one of the given datapath components by 10%, which component should it be? What is the speedup from this improvement?For the remaining problems in this exercise, assume that there are no pipeline stalls and that the breakdown of executed instructions is as follows:
What is the critical path for an MIPS BEQ instruction?Different execution units and blocks of digital logic have different latencies (time needed to do their work). In Figure 4.2 there are seven kinds of major blocks. Latencies of blocks along the critical (longest-latency) path for an instruction
Repeat 4.19.3 but this time determine which of the two options results in shorter time per instruction.Problem 4.19.3Let us assume that we cannot afford to have three-input Muxes that are needed for full forwarding. We have to decide if it is better to forward only from the EX/MEM pipeline register
Instead of a single-cycle organization, we can use a multicycle organization where each instruction takes multiple cycles but one instruction inishes before another is fetched. In this organization, an instruction only goes through stages it actually needs (e.g., ST only takes 4 cycles because it
Using a single test described in 4.8.1, we can test for faults in several different signals, but typically not all of them. Describe a series of tests to look for this fault in all Mux outputs (every output bit from each of the ive Muxes). Try to do this with as few single-instruction tests as
If it costs $1 to reduce the latency of a single component of the datapath by 1ps, what would it cost to reduce the clock cycle time by 20% in the single-cycle and in the pipelined design?The remaining three problems in this exercise assume that components of the datapath have the following
For the design described in 4.20.5, add NOPs to this instruction sequence to ensure correct execution in spite of missing support for forwarding.Problems 4.20.5If we assume forwarding will be implemented when we design the hazard detection unit, but then we forget to actually implement
Compare the cost/performance ratio with and without this improvement.When processor designers consider a possible improvement to the processor datapath, the decision usually depends on the cost/performance trade-off. In the following three problems, assume that we are starting with a datapath from
If an idle unit spends 10% of the power it would spend if it were active, what is the energy spent by the instruction memory in each cycle? What percentage of the overall energy spent by the instruction memory does this idle energy represent?The remaining three problems in this exercise assume that
For the new hazard detection unit from 4.21.5, specify which output signals it asserts in each of the first five cycles during the execution of this code.Problem 4.21.5If there is no forwarding, what new inputs and output signals do we need for the hazard detection unit in Figure 4.60? Using this
What is the speedup of using your code from 4.29.4 instead of the original code with a pipelined (1-issue) processor? Assume that the loop has many (e.g., 1,000,000) iterations.Exercise 4.29.4Unroll this loop once and schedule it for a 2-issue staticsuperscalar processor. Assume that the loop
Change your design to minimize the latency, then to minimize the cost. Compare the cost and latency of these two optimized designs.Cost and latency of digital logic depends on the kinds of basic logic elements (gates) that are available and on the properties of these gates. The remaining three
Repeat 4.39.5, but now assume that energy consumption is reduced by a factor of X2 when latency is made X times longer. What are the power savings compared to what you computed for 4.39.2?Exercise 4.39.2What is the power dissipated in watts (joules per second)?Exercise 4.39.5Repeat 4.39.4, but this
Repeat 4.9.5, but now implement both of these signals.Problems 4.9.5For the datapath from Figure 4.24, draw the logic diagram for the part of the control unit that implements just the first signal. Assume that we only need to support LW, SW, BEQ, ADD, and J (jump) instructions.Different
Using the first branch instruction in the given code as an example, describe the forwarding support that must be added to support branch execution in the ID stage. Compare the complexity of this new forwarding unit to the complexity of the existing forwarding unit in Figure 4.62.This exercise is
What is the total execution time of this instruction sequence with only ALU-ALU forwarding? What is the speedup over a no-forwarding pipeline?In this exercise, we examine how data dependences affect execution in the basic 5-stage pipeline described in Section 4.5. Problems in this exercise refer to
What fraction of the cost was saved in your circuit from 4.4.3 by implementing these two control signals together instead of separately?Problem 44.3When multiple logic expressions are implemented, it is possible to reduce implementation cost by using the same signals in more than one expression.
Repeat 4.30.5, but now assume that the 4-issue processor has 50 pipeline stages. Assume that each of the original 5 stages is broken into 10 new stages, and that branches are executed in the first of ten new EX stages. What conclusion can you draw about the importance of good branch prediction when
If the processor is already too expensive, instead of paying to speed it up as we did in 4.10.5, we want to minimize its cost without further slowing it down. If you can use slower logic to implement control signals, saving $1 of the processor cost for each 5ps you add to the latency of a single
Assuming stall-on-branch and no delay slots, what is the new clock cycle time and execution time of this instruction sequence if BEQ address computation is moved to the MEM stage? What is the speedup from this change? Assume that the latency of the EX stage is reduced by 20ps and the latency of the
Some branch instructions are much more predictable than others. If we know that 80% of all executed branch instructions are easy-to-predict loop-back branches that are always predicted correctly, what is the accuracy of the 2-bit predictor on the remaining 20% of the branch instructions?The
Which cache design is better for each of these benchmarks? Use data to support your conclusion.Both Barcelona and Nehalem are chip multiprocessors (CMPs), having multiple cores and their caches on a single chip. CMP on-chip L2 cache design has interesting trade-offs. The following table shows the
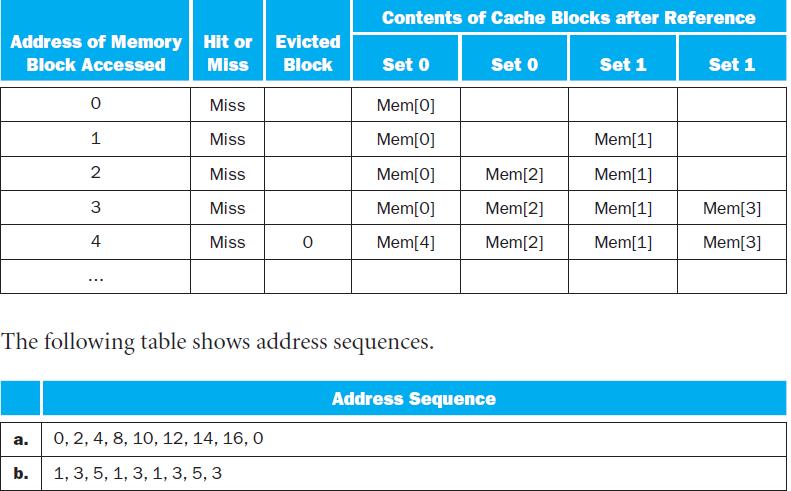
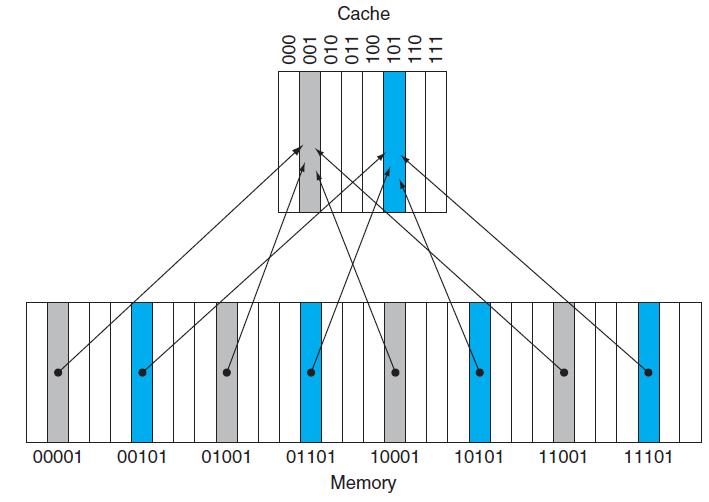
For each of these references, identify the binary address, the tag, and the index given a direct-mapped cache with 16 one-word blocks. Also list if each reference is a hit or a miss, assuming the cache is initially empty.Caches are important to providing a high-performance memory hierarchy to
The change in 4.17.5 requires many existing LW/SW instructions to be converted into two-instruction sequences. If this is needed for 50% of these instructions, what is the overall speedup achieved by changing from the 5-stage pipeline to the 4-stage pipeline where EX and MEM are done in
How many iterations of your loop from 4.35.4 can be “in light” within this processor’s pipeline? We say that an iteration is “in light” when at least one of its instructions has been fetched and has not yet been committed.Exercise 4.35.4ranslate this C loop into MIPS instructions,
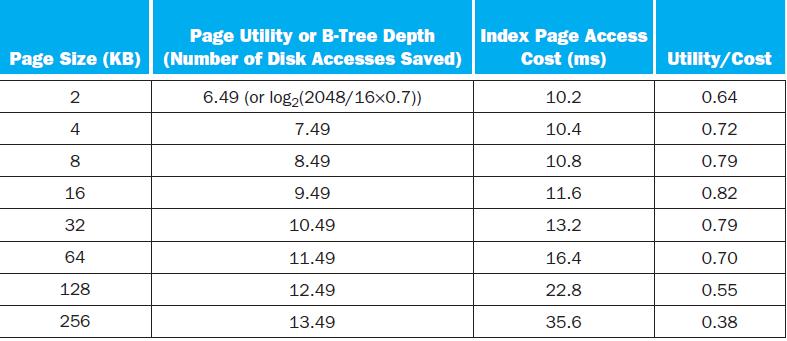
What is the best page size if using a modern disk with a 3 ms latency and 100 MB/s transfer rate? Explain why future servers are likely to have larger pages.For a high-performance system such as a B-tree index for a database, the page size is determined mainly by the data size and disk performance.
List the possible values of the given cache block for a correct cache coherence protocol implementation. List at least one more possible value of the block if the protocol doesn’t ensure cache coherency.Cache coherence concerns the views of multiple processors on a given cache block. The
What is the cache line size (in words)?For a direct-mapped cache design with a 32-bit address, the following bits of the address are used to access the cache. a. b. Tag 31-10 31-12 Index 9-5 11-6 Offset 4-0 5-0
Buffers are employed between different levels of memory hierarchy to reduce access latency. For this given configuration, list the possible buffers needed between L1 and L2 caches, as well as L2 cache and memory.Recall that we have two write policies and write allocation policies, and their
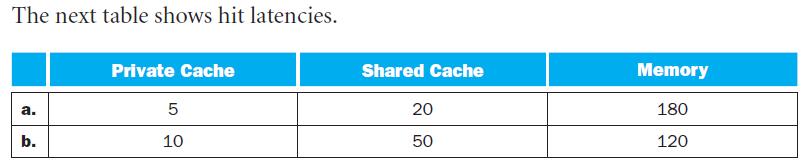
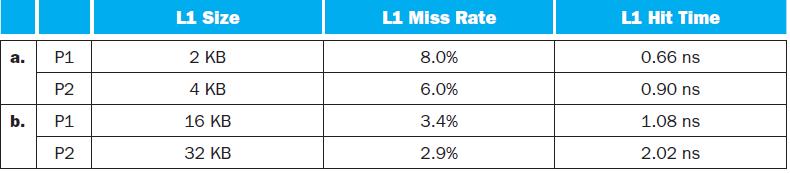
Assuming that the L1 hit time determines the cycle times for P1 and P2, what are their respective clock rates?In this exercise, we will look at the different ways capacity affects overall performance. In general, cache access time is proportional to capacity. Assume that main memory accesses take
Assume a 64 KB direct-mapped cache with a 32-byte line. What is the miss rate for the address stream above? How is this miss rate sensitive to the size of the cache or the working set? How would you categorize the misses this workload is experiencing, based on the 3C model?Media applications that
Using the references from Exercise 5.3, show the final cache contents for a three-way set associative cache with two-word blocks and a total size of 24 words. Use LRU replacement. For each reference identify the index bits, the tag bits, the block offset bits, and if it is a hit or a miss.This
Assuming both client and server are involved in the process, first name the client and server systems. Where can caches be placed to speed up the process?In this exercise we consider memory hierarchies for various applications, listed in the following table. a. Software version control b. Making
What is the best page size if entries now become 128 bytes?For a high-performance system such as a B-tree index for a database, the page size is determined mainly by the data size and disk performance. Assume that on average a B-tree index page is 70% full with ix-sized entries. The utility of a
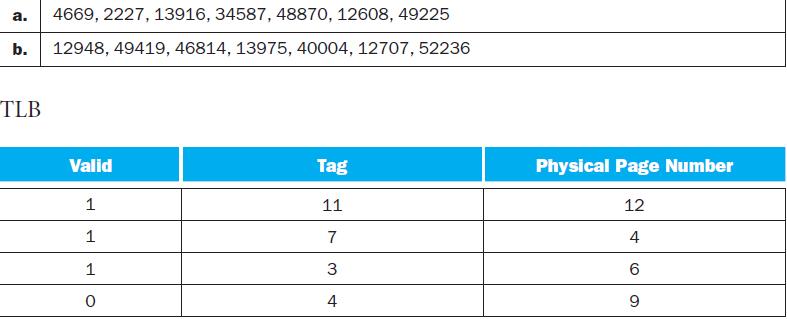
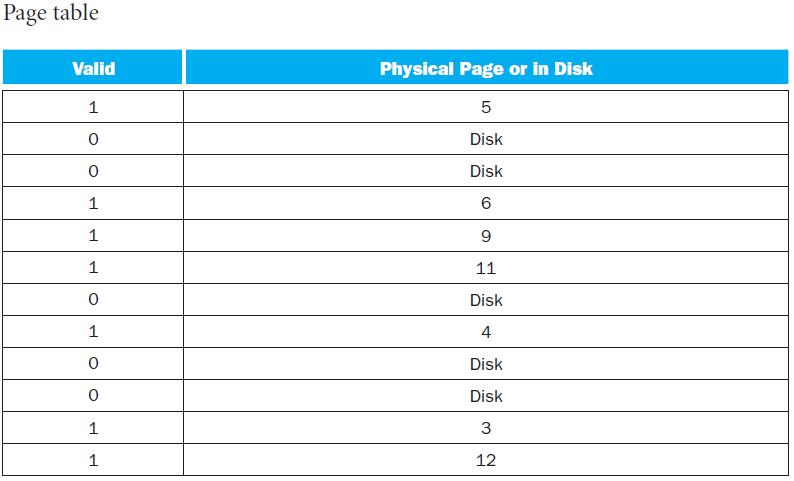
Given the address stream in the table, and the initial TLB and page table states shown above, show the final state of the system. Also list for each reference if it is a hit in the TLB, a hit in the page table, or a page fault.Virtual memory uses a page table to track the mapping of virtual
How many 32-bit integers can be stored in a 16-byte cache line?In this exercise we look at memory locality properties of matrix computation. The following code is written in C, where elements within the same row are stored contiguously. a. b. for (I=0; I
For a single-level page table, how many page table entries (PTEs) are needed? How much physical memory is needed for storing the page table?In this exercise, we will examine space/time optimizations for page tables. The following table shows parameters of a virtual memory system. a. b. Virtual
Assuming an LRU replacement policy, how many hits does this address sequence exhibit?In this exercise, we will examine how replacement policies impact miss rate. Assume a 2-way set associative cache with 4 blocks. You may find it helpful to draw a table like those found on page 482 to solve the
What would happen for the given operation sequence for shadow page table and nested page table, respectively?To support multiple virtual machines, two levels of memory virtualization are needed. Each virtual machine still controls the mapping of virtual address (VA) to physical address (PA), while
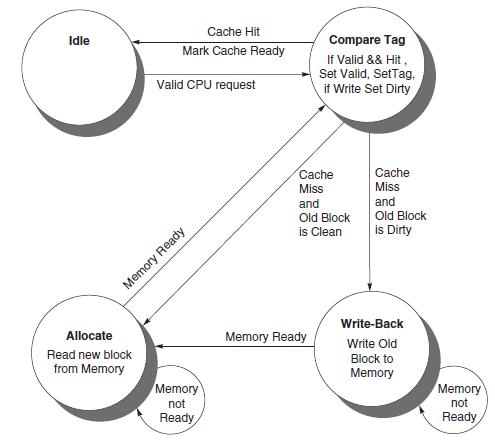
What should happen if the processor issues a request that hits in the cache while a block is being written back to main memory from the write buffer?In this exercise, we will explore the control unit for a cache controller for a processor with a write buffer. Use the inite state machine found in
For a snooping protocol, list a valid operation sequence on each processor/cache to inish the above read/write operations.Cache coherence concerns the views of multiple processors on a given cache block. The following table shows two processors and their read/write operations on two different words
Shared cache latency increases with the CMP size. Choose the best design if the shared cache latency doubles. Off-chip bandwidth becomes the bottleneck as the number of CMP cores increases. Choose the best design if offchip memory latency doubles.Both Barcelona and Nehalem are chip multiprocessors
Showing 100 - 200
of 1073
1
2
3
4
5
6
7
8
9
10
11
Step by Step Answers



![a. b. ADDM Rd, Rt+Offs (Rs) BEQM Rd, Rt, Offs (Rs) Rd=Rt+Mem[Offs+Rs] if Rt=Mem[Offs+Rs] then PC = Rd](https://dsd5zvtm8ll6.cloudfront.net/images/question_images/1698/2/3/0/1826538efa6aa82d1698230175553.jpg)





![a. b. Instruction ADD Rd, Rs, Rt ADDI Rt, Rs, Imm Interpretation Reg[Rd]=Reg[Rs]+Reg[Rt] Reg[Rt] Reg[Rs]+[mm](https://dsd5zvtm8ll6.cloudfront.net/images/question_images/1698/3/0/9/194653a244a76f8a1698309191510.jpg)
![a. b. for(i=0;i!-j; i++) { c+=a[i]; } for(i=0;i!-j;i+=2) { c+ a[i]-a[i+1]; }](https://dsd5zvtm8ll6.cloudfront.net/images/question_images/1698/3/0/9/609653a25e95982e1698309606387.jpg)






![a. for(i=0;i!-j;i+=2) a[i+1]=a[i]; b. for(i=0; i-j;i+=2) b[i]-a[i]-a[i+1]; C Code](https://dsd5zvtm8ll6.cloudfront.net/images/question_images/1698/3/0/6/885653a1b454551c1698306883241.jpg)













![PC 4 Instruction [25-0] Add Read address Instruction [31-0] Instruction memory 26 Shift left 2 Instruction](https://dsd5zvtm8ll6.cloudfront.net/images/question_images/1698/2/2/1/8226538cefe791201698221821237.jpg)









![a. b. X[0] ++ X[1] X[0] =10; X[1] = P1 3; = 3; X[0] X[0] = = P2 5; X[1] +=2; 5; X[1] +=2;](https://dsd5zvtm8ll6.cloudfront.net/images/question_images/1698/3/2/2/966653a5a16238741698322965852.jpg)




![a. b. for (I=0; I <8; I++) for (J-0; J <8000; J++) A[I] [J] B[I][0]+A[J][I]; for (J-0; J <8000; J++) for](https://dsd5zvtm8ll6.cloudfront.net/images/question_images/1698/3/1/6/038653a3f06eb7821698316036991.jpg)