New Semester
Started
Get
50% OFF
Study Help!
--h --m --s
Claim Now
Question Answers
Textbooks
Find textbooks, questions and answers
Oops, something went wrong!
Change your search query and then try again
S
Books
FREE
Study Help
Expert Questions
Accounting
General Management
Mathematics
Finance
Organizational Behaviour
Law
Physics
Operating System
Management Leadership
Sociology
Programming
Marketing
Database
Computer Network
Economics
Textbooks Solutions
Accounting
Managerial Accounting
Management Leadership
Cost Accounting
Statistics
Business Law
Corporate Finance
Finance
Economics
Auditing
Tutors
Online Tutors
Find a Tutor
Hire a Tutor
Become a Tutor
AI Tutor
AI Study Planner
NEW
Sell Books
Search
Search
Sign In
Register
study help
computer science
computer organization design
Computer Organization And Design The Hardware Software Interface 4th Revised Edition David A. Patterson, John L. Hennessy - Solutions
If on average we need to access memory once every 100 cycles, what is impact on our application?On a CC-NUMA system, the cost of accessing non-local memory can limit our ability to utilize multiprocessing effectively. The following table shows the costs associated with access data in local memory
Loop unrolling was described in Chapter 4. Apply loop unrolling to this loop and then consider running this code on a 2-node distributed memory message passing system. Assume that we are going to use message passing as described in Section 7.4, where we introduce a new operation send (x, y) that
First, write down a list of your daily activities that you typically do on a weekday. For instance, you might get out of bed, take a shower, get dressed, eat breakfast, dry your hair, brush your teeth, etc. Make sure to break down your list so you have a minimum of 10 activities.For 7.1.2, what
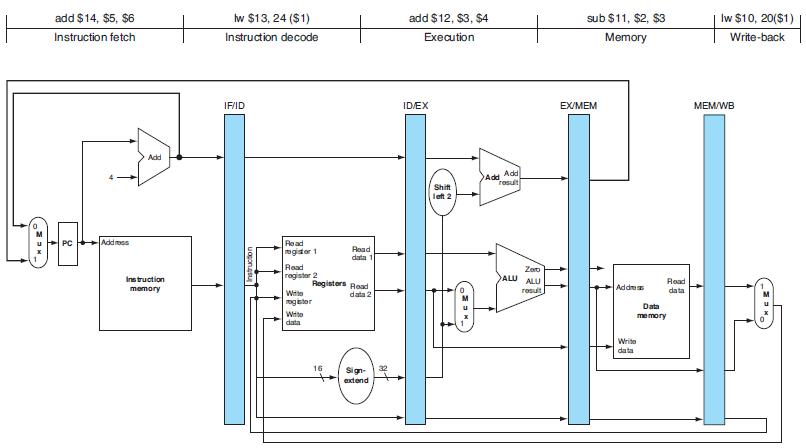
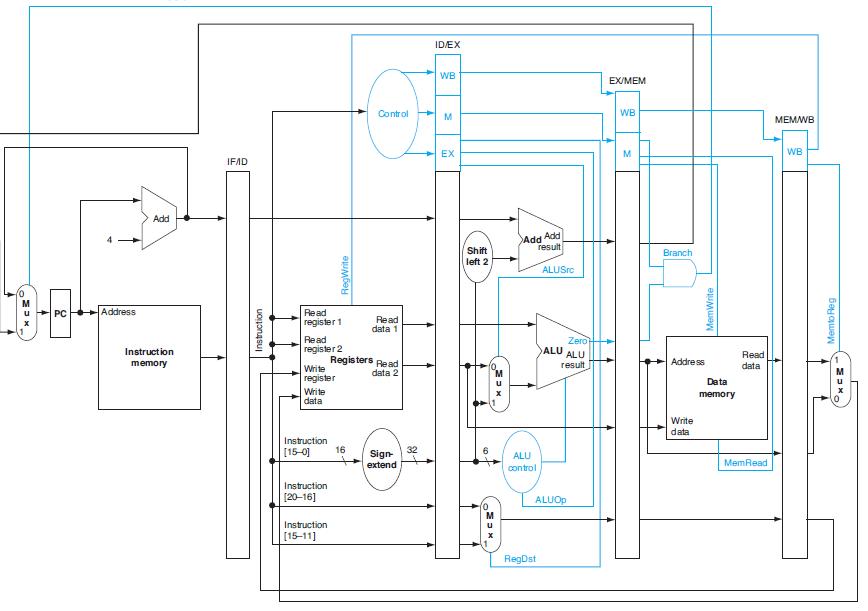
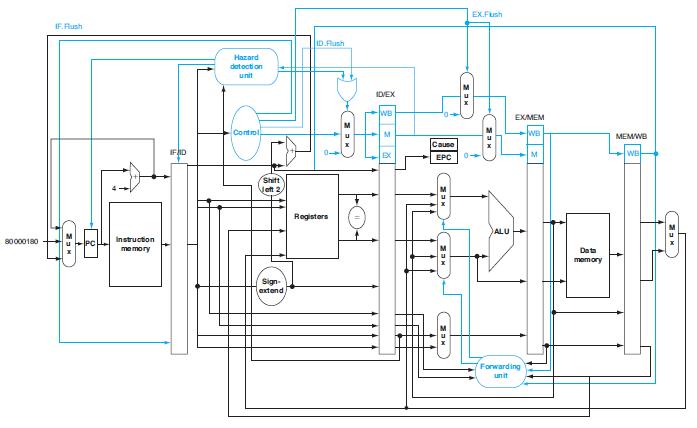
Find all hazards in this instruction sequence for a 5-stage pipeline with and then without forwarding.Problems in this exercise refer to the following instruction sequences: a. b. ADD R1, R2, R1 LW R2,0 (R1) LW R1,4 (R1) OR R3, R1, R2 LW R1,0 (R1) R1, R1, R2 AND LW R2,0 (R1) LW R1,0
Control hazards can be eliminated by adding branch delay slots. How many delay slots must follow each branch if we want to eliminate all control hazards in this processor?This exercise is intended to help you better understand the relationship between ISA design and pipelining. Problems in this
What is the total latency of an LW instruction in a pipelined and non-pipelined processor?In this exercise, we examine how pipelining affects the clock cycle time of the processor. Problems in this exercise assume that individual stages of the datapath have the following latencies:
This exercise is intended to help you understand the cost/complexity/performance trade-offs of forwarding in a pipelined processor. Problems in this exercise refer to pipelined datapaths from Figure 4.45. These problems assume that, of all the instructions executed in a processor, the following
This exercise explores some of the tradeoffs involved in pipelining, such as clock cycle time and utilization of hardware resources. The first three problems in this exercise refer to the following MIPS code. The code is written with an assumption that the processor does not use delay slots.What is
If the loop exits after executing only two iterations, draw a pipeline diagram for your MIPS code from 4.28.1 executed on a 2-issue processor shown in Figure 4.69. Assume the processor has perfect branch prediction and can fetch any two instructions (not just consecutive instructions) in the same
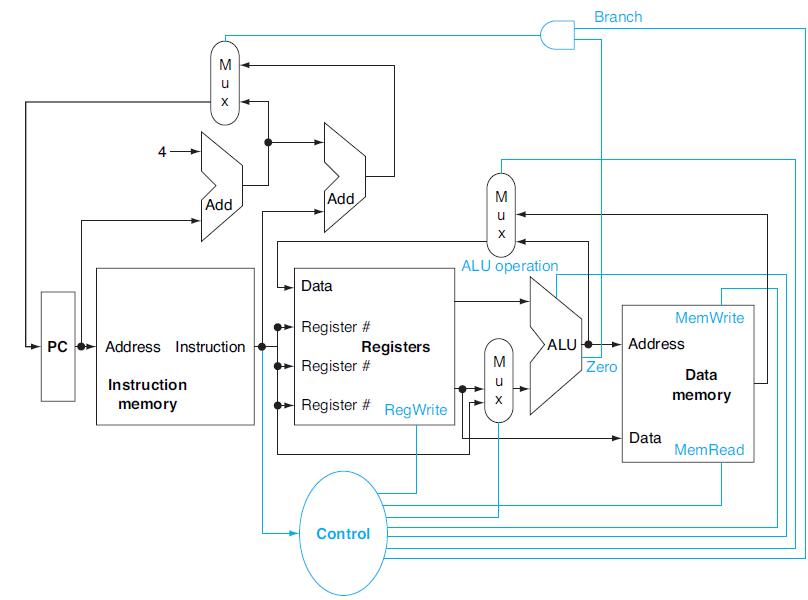
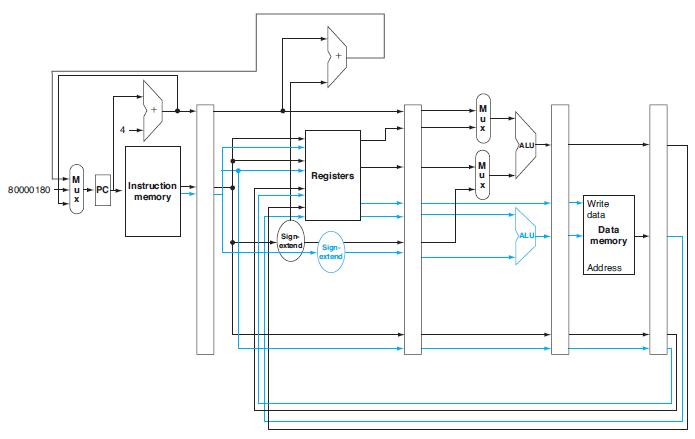
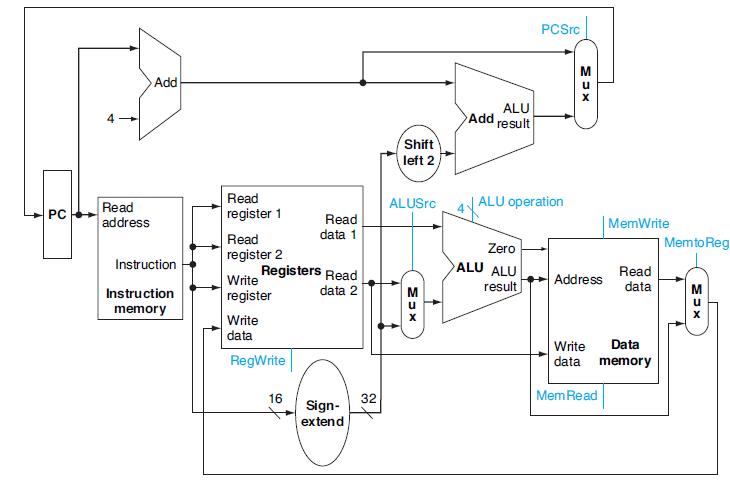
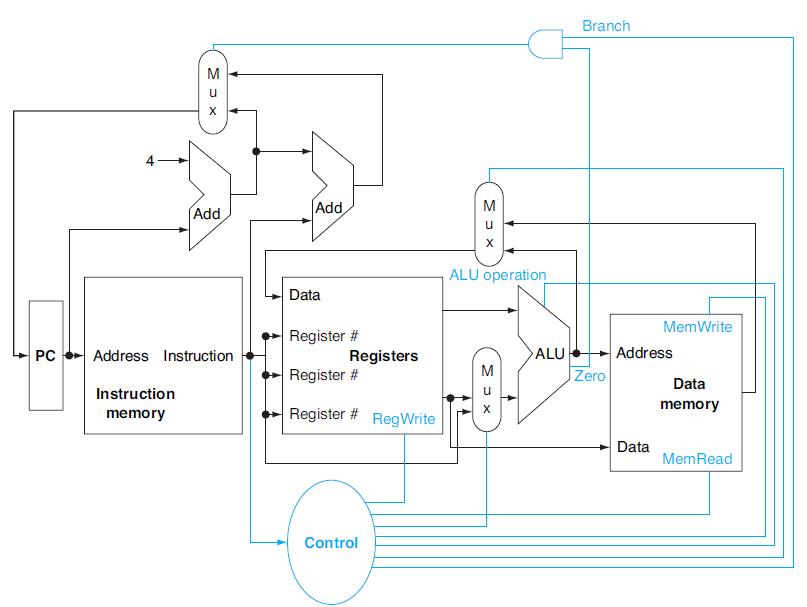
In this exercise we examine in detail how an instruction is executed in a single-cycle datapath. Problems in this exercise refer to a clock cycle in which the processor fetches the following instruction word:What are the values of the ALU control unit’s inputs for this instruction?
Repeat 4.27.1, but this time assume that the instruction in the delay slot also causes a hardware error exception when it is in MEM stage.Exercise 4.27.1Assume that this branch is correctly predicted as taken, but then the instruction at “Label” is an undefined instruction. Describe what is
The first three problems in this exercise refer to the execution of the following instruction in the pipelined datapath from Figure 4.51, and assume the following clock cycle time, ALU latency, and Mux latency:Figure 4.51How much time does the control unit have to generate the ALUSrc control
Consider a datapath similar to the one in Figure 4.11, but for a processor that only has one type of instruction: unconditional PC-relative branch. What would the cycle time be for this datapath?Figure 4.11Problems in this exercise assume that logic blocks needed to implement a processor’s
This exercise is intended to help you better understand the last pitfall from failure to consider pipelining in instruction set design. The first four problems in this exercise refer to the following new MIPS instruction:How would you change the 5-stage MIPS pipeline to add support for micro-op
This exercise explores how exception handling affects control unit design and processor clock cycle time. The first three problems in this exercise refer to the following MIPS instruction that triggers an exception:Some of the control signals generated in the ID stage are stored into the ID/EX
Different instructions utilize different hardware blocks in the basic single-cycle implementation. The next three problems in this exercise refer to the following instruction:Which resources (blocks) perform a useful function for this instruction? a. b. Instruction AND Rd, Rs, Rt SW Rt, Offs
What are the values of control signals generated by the control in Figure 4.2 for this instruction?Figure 4.2Different instructions utilize different hardware blocks in the basic single-cycle implementation. The next three problems in this exercise refer to the following instruction:
Assuming there are no stalls and that 60% of all conditional branches are taken, in what percentage of clock cycles does the branch adder in the EX stage generate a value that is actually used?Problems in this exercise assume that instructions executed by a pipelined processor are broken down as
This exercise is designed to help you understand the discussion of the “Pipelining is easy. The first four problems in this exercise refer to the following MIPS instruction:Describe a pipelined datapath needed to support only this instruction. Your datapath should be designed with the assumption
The first three problems in this exercise refer to the following MIPS instruction:As this instruction executes, what is kept in each register located between two pipeline stages? a. b. SW R16,-100 (R6) OR R2, R1, RO Instruction
Assuming there are no stalls, how often (percentage of all cycles) do we actually need to use all three register ports (two reads and a write) in the same cycle?Problems in this exercise assume that instructions executed by a pipelined processor are broken down as follows:
What is the speedup that would be achieved by using four branch delay slots to reduce control hazards in this processor? Assume that there are no data dependences between instructions and that all four delay slots can be illed with useful instructions without increasing the number of executed
Describe the requirements of forwarding and hazard detection units for your datapath from 4.34.1.Exercise 4.34.1Describe a pipelined datapath needed to support only this instruction. Your datapath should be designed with the assumption that the only instructions that will ever be executed are
If there is a separate handler address for each exception, show how the pipeline organization must be changed to be able to handle this exception. You can assume that the addresses of these handlers are known when the processor is designed.This exercise explores how exception handling affects
Which registers need to be read, and which registers are actually read?The first three problems in this exercise refer to the following MIPS instruction: a. b. SW R16,-100 (R6) OR R2, R1, RO Instruction
In a 4-issue processor with these pipeline parameters, how many branch instructions can be expected to be “in progress” (already fetched but not yet committed) at any given time?The remaining problems in this exercise assume the following pipeline depth and that the branch outcome is determined
What do you get if you take the square root of B and then multiply that value by itself? What should you get? Do for both single and double precision floating point numbers. (Write a program to do these calculations.)The following table shows pairs, each consisting of a fraction and an integer.
Write down the binary representation of the decimal number assuming it was stored using the single precision IBM format (base 16, instead of base 2, with 7 bits of exponent).The following table shows decimal numbers. a. 63.25 b. 146987.40625
Problems in this exercise refer to the following logic block:Does this block contain logic only, lip-lops only, or both? Logic Block a. Small Multiplexor (Mux) with four 8-bit data inputs b. Small 8-bit ALU that can do either AND, OR, or NOT
For this problem, assume that all branches are perfectly predicted (this eliminates all control hazards) and that no delay slots are used. If we only have one memory (for both instructions and data), there is a structural hazard every time we need to fetch an instruction in the same cycle in which
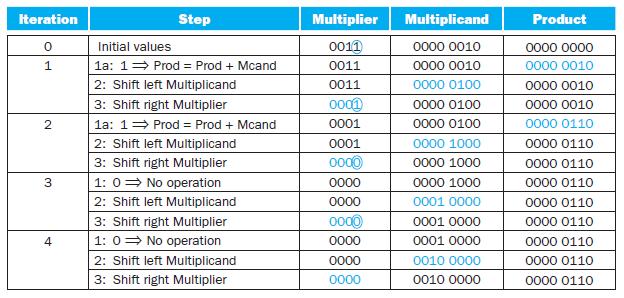
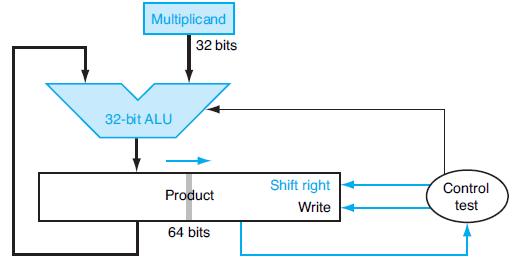
Write an MIPS assembly language program to calculate the product of the signed integers A and B. State if you are using the approach given in 3.4.4 or 3.4.5.Problem 3.4.4When multiplying signed numbers, one way to get the correct answer is to convert the multiplier and multiplicand to positive
Assume A and B are unsigned 8-bit integers. Calculate A + B using saturating arithmetic. The result should be written in decimal. Show your work.The following table also shows pairs of decimal numbers. a. b. A 15 151 В 139 214
Write an MIPS assembly language program to calculate the sum of A and B, assuming they are stored in the modified 16-bit NVIDIA format described in 3.11.2. Assume 1 guard, 1 round bit, and 1 sticky bit, and round to the nearest even.The following table shows pairs of decimal numbers. a. b. A 2.6125
Describe in detail one technique for performing floating point division in a digital computer. Be sure to include references to the sources you used.The following table shows further pairs of decimal numbers. a. b. A 8.625 x 10¹ 1.84375 x 10⁰ B -4.875 x 10⁰ 1.3203125 x 10⁰
Write an MIPS assembly language program to perform the multiplication of A and B using Booth’s algorithm.The following table shows further pairs of hexadecimal numbers. a. b. A F6 08 B 7F 55
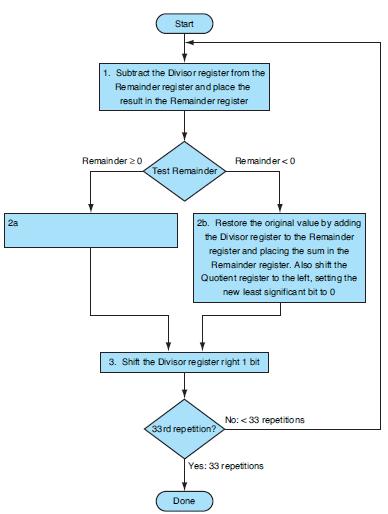
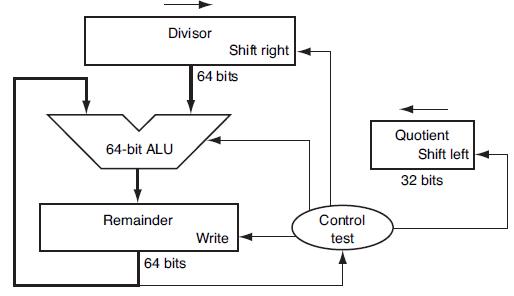
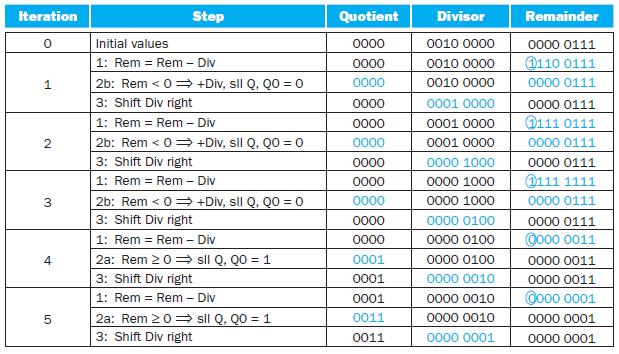
Using a table similar to that shown in Figure 3.11, calculate A divided by B using the hardware described in Figure 3.12. You should show thecontents of each register on each step. Assume A and B are 6-bit signed integers in sign-magnitude format. Be sure to include how you are calculating the
Assume A and B are signed 8-bit decimal integers stored in two’s complement format. Calculate A – B using saturating arithmetic. The result should be written in decimal. Show your work.The following table also shows pairs of decimal numbers. a. b. A 15 151 В 139 214
In the following exercise, the data table contains various MIPS logical operations. You will be asked to find the result of these operations given values for registers $t0 and $t1.Assume that $t0 = 0xA5A5FFFF and $t1 = A5A5FFFF. What is the value of $t2 after the two instructions in the table?
How does the performance of non-restoring and nonperforming division compare? Demonstrate by showing the number of steps necessary to calculate A divided by B using each method. Assume A and B are signed 6-bit integers, stored in sign-magnitude format. Writing a program to perform the nonperforming
Based on your answers to 3.13.4 and 3.13.5, does (A × B) × C = A × (B × C)?Problem 3.13.4Calculate (A × B) × C by hand, assuming A, B, and C are stored in the modified 16-bit NVIDIA format described in 3.11.2 (and also described in the text). Assume 1 guard, 1 round bit, and 1 sticky bit,
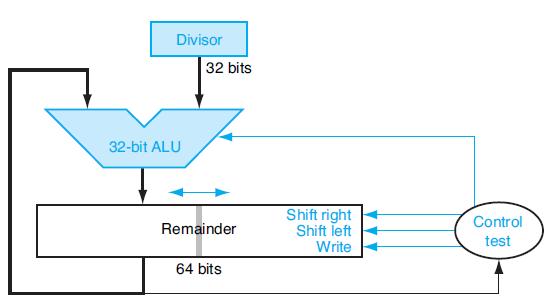
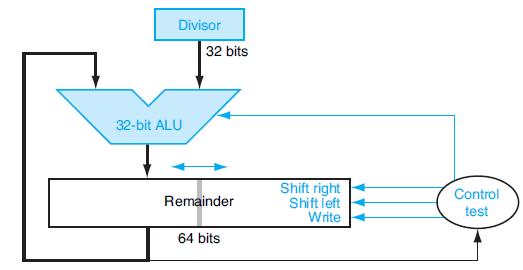
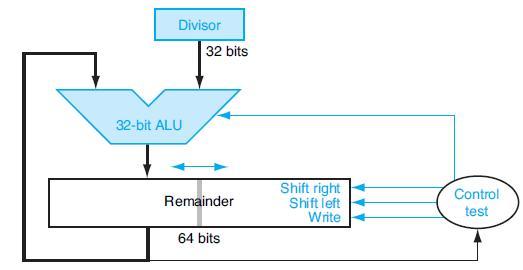
Write an MIPS assembly language program to calculate A divided by B, using the approach described in Figure 3.12. Assume A and B are signed integers.Figure 3.12The following table shows further pairs of octal numbers. Divisor 32-bit ALU 32 bits Remainder 64 bits Shift right Shift
Translate this instruction into MIPS micro-operations.This exercise is intended to help you better understand the last pitfall from failure to consider pipelining in instruction set design. The first four problems in this exercise refer to the following new MIPS instruction: a. Instruction SWINC
If there is no forwarding or hazard detection, insert NOPs to ensure correct execution.This exercise is intended to help you understand the relationship between forwarding, hazard detection, and ISA design. Problems in this exercise refer to the following sequences of instructions, and assume that
What is the value of the instruction word?In this exercise we examine the operation of the single-cycle datapath for a particular instruction. Problems in this exercise refer to the following MIPS instruction: a. b. SW R4,-100 (R16) SLT R1, R2, R3 Instruction
If many (e.g., 1,000,000) iterations of this loop are executed, determine the fraction of all register reads that are useful in a 2-issue static superscalar processor.In this exercise, we consider the execution of a loop in a statically scheduled superscalar processor. To simplify the exercise,
To avoid lengthening the critical path of the datapath shown in Figure 4.24, how much time can the control unit take to generate the MemWrite signal?In this exercise we examine how the clock cycle time of the processor affects the design of the control unit, and vice versa. Problems in this
Draw the pipeline execution diagram for this code, assuming there are no delay slots and that branches execute in the EX stage.This exercise is intended to help you understand the relationship between delay slots, control hazards, and branch execution in a pipelined processor. In this exercise, we
Implement the logic for the Control signal 1. Your circuit should directly implement the given expression (do not reorganize the expression to “optimize” it), using NOT gates and 2-input AND, OR, and XOR gates.When implementing a logic expression in digital logic, one must use the available
What is the CPI achieved by a 2-issue static superscalar processor on this program?In this exercise, we make several assumptions. First, we assume that an N-issue superscalar processor can execute any N instructions in the same cycle, regardless of their types. Second, we assume that every
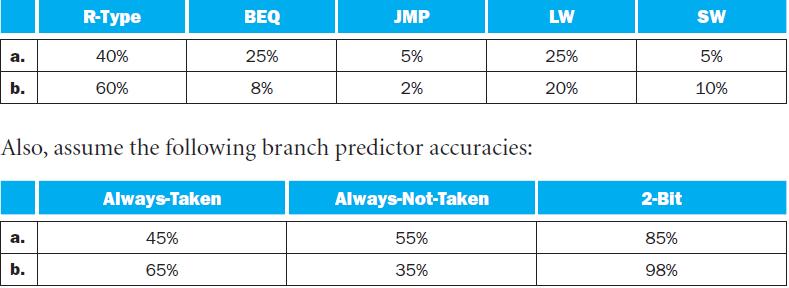
Stall cycles due to mispredicted branches increase the CPI. What is the extra CPI due to mispredicted branches with the always-taken predictor? Assume that branch outcomes are determined in the EX stage, that there are no data hazards, and that no delay slots are used.The importance of having a
What CPI would be achieved if the MIPS version of this loop is executed on a 1-issue processor with static scheduling and a 5-stage pipeline?Problems in this exercise refer to the following loop, which is given as x86 code and also as an MIPS translation of that code. You can assume that this loop
Design a circuit with 1-bit data inputs and a 1-bit data output that accomplishes this operation serially, starting with the least-significant bit. In a serial implementation, the circuit is processing input operands bit by bit, generating output bits one by one. For example, a serial AND circuit
What is the accuracy of always-taken and always-not-taken predictors for this sequence of branch outcomes?This exercise examines the accuracy of various branch predictors for the following repeating pattern (e.g., in a loop) of branch outcomes: a. b. T, T, NT, NT T, NT, T, T, NT Branch Outcomes
What must be changed in the pipelined datapath to add this instruction to the MIPS ISA?In this exercise, we examine how the ISA affects pipeline design. Problems in this exercise refer to the following new instruction: a. b. ADDM Rd, Rt+Offs (Rs) BEQM Rd, Rt, Offs (Rs) Rd=Rt+Mem[Offs+Rs] if
How many instructions are expected to be executed between the time one branch misprediction is detected and the time the next branch misprediction is detected?Problems in this exercise assume that branches represent the following fraction of all executed instructions, and the following branch
How many register read ports should the processor have to avoid any resource hazards due to register reads?This exercise explores how branch prediction affects performance of a deeply pipelined multiple-issue processor. Problems in this exercise refer to a processor with the following number of
Convert A into a binary number. What makes base 8 (octal) an attractive numbering system for representing values in computers?The following table also shows pairs of octal numbers. a. b. A 7040 4365 В 0444 3412
Convert A into a binary number. What makes base 16 (hexadecimal) an attractive numbering system for representing values in computers?The following table also shows pairs of hexadecimal numbers. a. b. A C352 5ED4 B 36AE 07A4
Write an MIPS assembly language program to calculate the sum of A and B, assuming they are stored using the format described in 3.11.1. Now modify the program to calculate the sum assuming the format described in 3.11.3. Which format is easier for a programmer to deal with? How do they each compare
For each stage of the pipeline, determine the values of exception- related control signals from Figure 4.66 as this instruction passes through that pipeline stage.This exercise explores how exception handling affects control unit design and processor clock cycle time. The first three problems in
If the only thing we need to do in a processor is fetch consecutive instructions, what would the cycle time be?Problems in this exercise assume that logic blocks needed to implement a processor’s datapath have the following latencies: I-Mem Add Mux ALU 70ps 20ps 90ps 200ps 50ps 250ps a. 200ps b.
For each stage of the pipeline, what are the values of the control signals asserted by this instruction in that pipeline stage?The first three problems in this exercise refer to the execution of the following instruction in the pipelined datapath from Figure 4.51, and assume the following clock
What are the outputs of the sign-extend and the jump “Shift left 2” unit (near the top of Figure 4.24) for this instruction word?In this exercise we examine in detail how an instruction is executed in a single-cycle datapath. Problems in this exercise refer to a clock cycle in which the
Assume that this branch is correctly predicted as taken, but then the instruction at “Label” is an undefined instruction. Describe what is done in each pipeline stage for each cycle, starting with the cycle in which the branch is decoded up to the cycle in which the first instruction of the
If we use no forwarding, what fraction of cycles are we stalling due to data hazards?This exercise is intended to help you understand the cost/complexity/performance trade-offs of forwarding in a pipelined processor. Problems in this exercise refer to pipelined datapaths from Figure 4.45. These
Translate this C code into MIPS instructions. Your translation should be direct, without rearranging instructions to achieve better performance.In this exercise we compare the performance of 1-issue and 2-issue processors, taking into account program transformations that can be made to optimize for
Which parts of the basic single-cycle datapath are used by all of these instructions? Which parts are the least utilized?This exercise explores some of the tradeoffs involved in pipelining, such as clock cycle time and utilization of hardware resources. The first three problems in this exercise
What is the clock cycle time if the only types of instructions we need to support are ALU instructions (ADD, AND, etc.)?In this exercise we examine how latencies of individual components of the datapath affect the clock cycle time of the entire datapath, and how these components are utilized by
What is the clock cycle time in a pipelined and non-pipelined processor?In this exercise, we examine how pipelining affects the clock cycle time of the processor. Problems in this exercise assume that individual stages of the datapath have the following latencies:
Let us assume that processor testing is done by illing the PC, registers, and data and instruction memories with some values (you can choose which values), letting a single instruction execute, then reading the PC, memories, and registers. These values are then examined to determine if a particular
Which existing blocks (if any) can be used for this instruction?The basic single-cycle MIPS implementation in Figure 4.2 can only implement some instructions. New instructions can be added to an existing ISA, but the decision whether or not to do that depends, among other things, on the cost and
Find all data dependences in this instruction sequence.Problems in this exercise refer to the following instruction sequences: a. b. ADD R1, R2, R1 LW R2,0 (R1) LW R1,4 (R1) OR R3, R1, R2 LW R1,0 (R1) R1, R1, R2 AND LW R2,0 (R1) LW R1,0 (R3) Instruction Sequence
How much energy is spent to execute an ADD instruction in a single-cycle design and in the 5-stage pipelined design?This exercise explores energy efficiency and its relationship with performance. Problems in this exercise assume the following energy consumption for activity in Instruction memory,
Which exceptions can each of these instructions trigger? For each of these exceptions, specify the pipeline stage in which it is detected.This exercise explores how exception handling affects pipeline design. The first three problems in this exercise refer to the following two instructions:
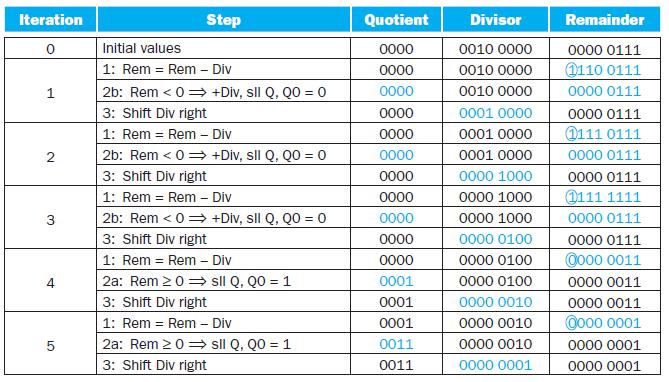
Using a table similar to that shown in Figure 3.11, calculate A divided by B using the hardware described in Figure 3.12. You should show the contents of each register on each step. Assume A and B are unsigned 6-bit integers. This algorithm requires a slightly different approach than that shown in
Calculate A + (B + C) by hand, assuming A, B, and C are stored in the modified 16-bit NVIDIA format described in 3.11.2 (and also described in the text). Assume 1 guard, 1 round bit, and 1 sticky bit, and round to the nearest even. Show all the steps, and write your answer in both the 16-bit
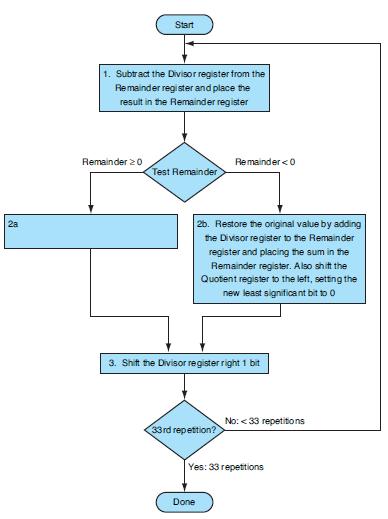
Write an MIPS assembly language program to calculate A divided by B using non-restoring division. Assume A and B are 6-bit signed (two’s complement) integers.Figure 3.10 describes a restoring division algorithm, because when subtracting the divisor from the remainder produces a negative result,
Use a low chart (or a high-level code snippet) to describe how the algorithm works.Division is so time-consuming and difficult that the CRAY T3E Fortran Optimization guide states, “The best strategy for division is to avoid it whenever possible.” This exercise looks at the following different
Calculate (A × B) + (A × C) by hand, assuming A, B, and C are stored in the modified 16-bit NVIDIA format described in 3.11.2 (and also described in the text). Assume 1 guard, 1 round bit, and 1 sticky bit, and round to the nearest even. Show all the steps, and write your answer in both the
If this bit pattern is placed into the Instruction Register, what MIPS instruction will be executed?In a Von Neumann architecture, groups of bits have no intrinsic meanings by themselves. What a bit pattern represents depends entirely on how it is used. The following table shows bit patterns
What is the sum of A and B if they represent signed 12-bit octal numbers stored in sign-magnitude format? The result should be written in octal. Show your work.The book shows how to add and subtract binary and decimal numbers. However, other numbering systems are also very popular when dealing with
What is the sum of A and B if they represent signed 16-bit hexadecimal numbers stored in sign-magnitude format? The result should be written in hexadecimal. Show your work.Hexadecimal (base 16) is also a commonly used numbering system for representing values in computers. In fact, it has become
NVIDIA has a “half” format, which is similar to IEEE 754 except that it is only 16 bits wide. The leftmost bit is still the sign bit, the exponent is 5 bits wide and stored in excess-56 format, and the mantissa is 10 bits long. A hidden 1 is assumed. Write down the bit pattern assuming a
Write down the bit pattern in the mantissa assuming a floating point format that uses Binary Coded Decimal (base 10) numbers in the mantissa instead of base 2. Assume there are 24 bits, and you do not need to normalize. Is this representation exact?Binary numbers are used in the mantissa field, but
Assume A and B are signed 8-bit decimal integers stored in sign magnitude format. Calculate A – B. Is there overflow, underflow, or neither?Overflow occurs when a result is too large to be represented accurately given a finite word size. Underflow occurs when a number is too small to be
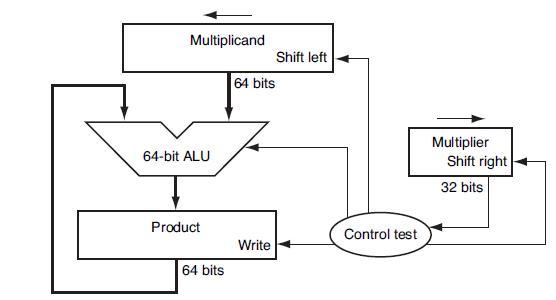
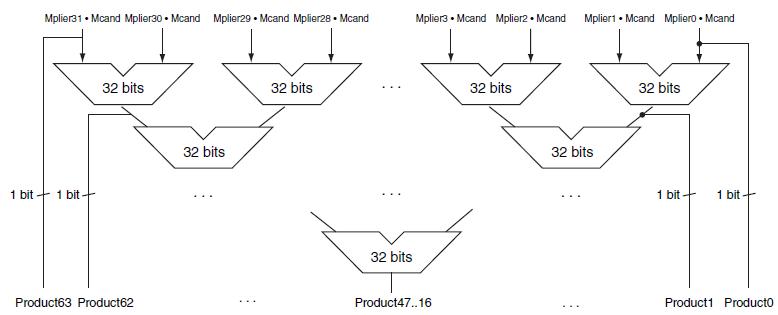
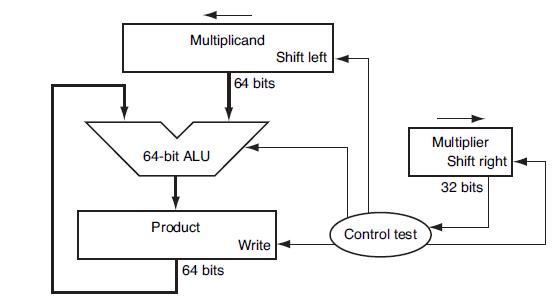
Write an MIPS assembly language program to calculate the product of unsigned integers A and B, using the approach described in Figure 3.4.Figure 3.4Let’s look in more detail at multiplication. We will use the numbers in the following table. Multiplicand 64-bit ALU Product 64 bits 64
Write an MIPS assembly language program to calculate the product of A and B, assuming they are stored using the format described in 3.11.1. Now modify the program to calculate the sum assuming the format described in 3.11.3. Which format is easier for a programmer to deal with? How do they each
Calculate the time necessary to perform a multiply using the approach given in Figure 3.8 if an integer is A bits wide and an adder takes B time units.Figure 3.8For many reasons, we would like to design multipliers that require less time. Many different approaches have been taken to accomplish this
Write an MIPS assembly language program that performs a multiplication on signed integers using shifts and adds, using the approach described in 3.6.1.In this exercise we will look at a couple of other ways to improve the performance of multiplication, based primarily on doing more shifts and fewer
Write an MIPS assembly language program to calculate A divided by B, using the approach described in Figure 3.9. Assume A and B are unsigned 6-bit integers.Figure 3.9Let’s look in more detail at division. We will use the octal numbers in the following table. Divisor 64-bit ALU Remainder 64
Based on your answers to 3.13.1 and 3.13.2, does (A + B) + C = A + (B + C)?Operations performed on fixed-point integers behave the way one expects—the commutative, associative, and distributive laws all hold. This is not always the case when working with floating point numbers, however. Let’s
How does the performance of restoring and non-restoring division compare? Demonstrate by showing the number of steps necessary to calculate A divided by B using each method. Assume A and B are 6-bit signed (sign- magnitude) integers. Writing a program to perform the restoring and non restoring
Write an MIPS assembly language program to perform division using the algorithm.Division is so time-consuming and difficult that the CRAY T3E Fortran Optimization guide states, “The best strategy for division is to avoid it whenever possible.” This exercise looks at the following different
Based on your answers to 3.14.1. and 3.14.2, does (A × B) + (A × C) = A × (B + C)?The Associative law is not the only one that does not always hold in dealing with floating point numbers. There are other oddities that occur as well. The following table shows sets of decimal numbers.
What decimal number does the bit pattern represent if it is a floating point number? Use the IEEE 754 standard.In a Von Neumann architecture, groups of bits have no intrinsic meanings by themselves. What a bit pattern represents depends entirely on how it is used. The following table shows bit
Convert A into a decimal number, assuming it is unsigned.Repeat assuming it stored in sign-magnitude format. Show your work.The book shows how to add and subtract binary and decimal numbers. However, other numbering systems are also very popular when dealing with computers. The octal (base 8)
Convert A into a decimal number, assuming it is unsigned. Repeat assuming it stored in sign-magnitude format. Show your work.Hexadecimal (base 16) is also a commonly used numbering system for representing values in computers. In fact, it has become much more popular than octal. The following table
The Hewlett-Packard 2114, 2115, and 2116 used a format with the leftmost 16 bits being the mantissa stored in two’s complement format, followed by another 16-bit field which had the leftmost 8 bits as an extension of the mantissa (making the mantissa 24 bits long), and the rightmost 8 bits
Write down the bit pattern assuming that we are using base 15 numbers in the mantissa instead of base 2. (Base 16 numbers use the symbols 0–9 and A–F. Base 15 numbers would use 0–9 and A–E.) Assume there are 24 bits, and you do not need to normalize. Is this representation exact?Binary
When multiplying signed numbers, one way to get the correct answer is to convert the multiplier and multiplicand to positive numbers, save the original signs, and then adjust the final value accordingly. Using a table similar to that shown in Figure 3.7, calculate the product of A and B using the
Showing 400 - 500
of 1073
1
2
3
4
5
6
7
8
9
10
11
Step by Step Answers

![for (j 2; j <1000;j++) D[j] = D[j-1]+D[j-2]; The MIPS code corresponding to the above fragment is: r2,r2,999](https://dsd5zvtm8ll6.cloudfront.net/images/question_images/1698/3/8/7/949653b57ed70e431698387949111.jpg)






![a. for(i=0;i!-j;i+=2) a[i+1]=a[i]; b. for(i=0; i-j;i+=2) b[i]-a[i]-a[i+1]; C Code](https://dsd5zvtm8ll6.cloudfront.net/images/question_images/1698/3/0/6/885653a1b454551c1698306883241.jpg)





![a. Instruction SWINC Rt, Offset (Rs) b. SWI Rt, Rd (Rs) Interpretation Mem[Reg[Rs]+Offset]=Reg [Rt] Reg[Rs ]](https://dsd5zvtm8ll6.cloudfront.net/images/question_images/1698/3/0/9/990653a2766637201698309988336.jpg)

![a. b. Instruction AND Rd, Rs, Rt SW Rt, Offs (Rs) Interpretation Reg[Rd]=Reg[Rs] AND Reg[Rt]](https://dsd5zvtm8ll6.cloudfront.net/images/question_images/1698/2/1/5/9996538b83feea8f1698215981279.jpg)

![a. b. Instruction AND Rd, Rs, Rt SW Rt, Offs (Rs) Interpretation Reg[Rd]=Reg[Rs] AND Reg[Rt]](https://dsd5zvtm8ll6.cloudfront.net/images/question_images/1698/3/0/9/169653a24315b4331698309167288.jpg)


















![PC Instruction [25-0] Add Read address Instruction [31-0] Instruction memory 26 Shift left 2/ Instruction](https://dsd5zvtm8ll6.cloudfront.net/images/question_images/1698/2/2/3/1346538d41eab5351698223133326.jpg)







![a. b. ADDM Rd, Rt+Offs (Rs) BEQM Rd, Rt, Offs (Rs) Rd=Rt+Mem[Offs+Rs] if Rt=Mem[Offs+Rs] then PC = Rd](https://dsd5zvtm8ll6.cloudfront.net/images/question_images/1698/2/3/0/1826538efa6aa82d1698230175553.jpg)






![PC 4 Instruction [25-0] Add Read address Instruction [31-0] Instruction memory 26 Shift left 2, Instruction](https://dsd5zvtm8ll6.cloudfront.net/images/question_images/1698/2/2/0/7976538cafd628951698220795953.jpg)
![a. b. Instruction SEQ Rd, Rs. Rt LWI Rt, Rd (Rs) Reg[Rd] Reg[Rt] = Interpretation Boolean value (0 or 1) of](https://dsd5zvtm8ll6.cloudfront.net/images/question_images/1698/2/1/6/7006538bafd00a0f1698216699865.jpg)