New Semester
Started
Get
50% OFF
Study Help!
--h --m --s
Claim Now
Question Answers
Textbooks
Find textbooks, questions and answers
Oops, something went wrong!
Change your search query and then try again
S
Books
FREE
Study Help
Expert Questions
Accounting
General Management
Mathematics
Finance
Organizational Behaviour
Law
Physics
Operating System
Management Leadership
Sociology
Programming
Marketing
Database
Computer Network
Economics
Textbooks Solutions
Accounting
Managerial Accounting
Management Leadership
Cost Accounting
Statistics
Business Law
Corporate Finance
Finance
Economics
Auditing
Tutors
Online Tutors
Find a Tutor
Hire a Tutor
Become a Tutor
AI Tutor
AI Study Planner
NEW
Sell Books
Search
Search
Sign In
Register
study help
computer science
computer organization design
Computer Organization and Design The Hardware Software Interface 5th edition David A. Patterson, John L. Hennessy - Solutions
For each function call, show the contents of the stack after the function call is made. Assume the stack pointer is originally at address 0x7ff ff ff c, and follow the register conventions as specified in Figure 2.11.Preserved
Write the MIPS assembly code to implement the following C code:lock(lk);shvar=max(shvar,x);unlock(lk);Assume that the address of the lk variable is in $a0, the address of the shvar variable is in $a1, and the value of variable x is in $a2. Your critical section should not contain any function
Repeat Exercise 2.43, but this time use ll/sc to perform an atomic update of the shvar variable directly, without using lock() and unlock(). Note that in this problem there is no variable lk.Exercise 2.43Write the MIPS assembly code to implement the following C
What is 5ED4 - 07A4 when these values represent signed 16-bit hexadecimal numbers stored in sign-magnitude format? The result should be written in hexadecimal. Show your work.
What is 4365 - 3412 when these values represent unsigned 12-bit octal numbers? The result should be written in octal. Show your work.
Assume 151 and 214 are signed 8-bit decimal integers stored in two’s complement format. Calculate 151 - 214 using saturating arithmetic. The result should be written in decimal. Show your work.
Assume 151 and 214 are unsigned 8-bit integers. Calculate 151 + 214 using saturating arithmetic. The result should be written in decimal. Show your work.
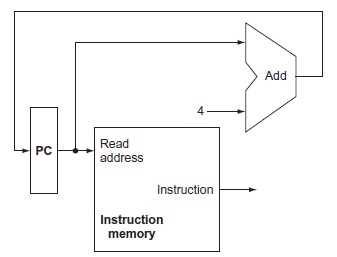
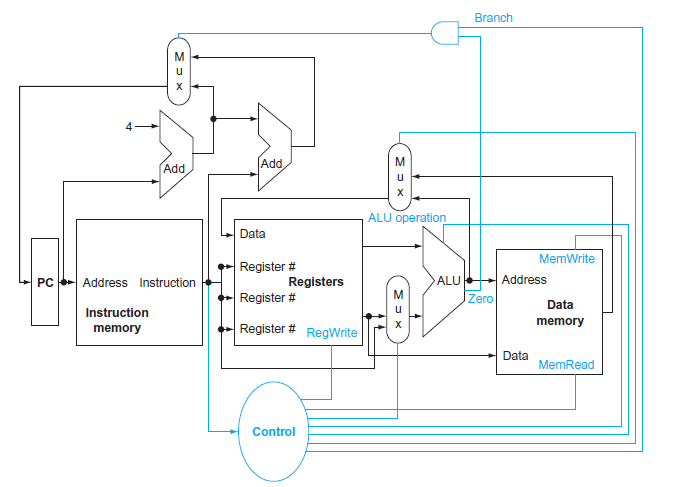
In this exercise we examine in detail how an instruction is executed in a single-cycle datapath. Problems in this exercise refer to a clock cycle in which the processor fetches the following instruction word:10101100011000100000000000010100.Assume that data memory is all zeros and that the
Consider the following three CPU organizations:CPU SS: A 2-core superscalar microprocessor that provides out-of-order issue capabilities on 2 function units (FUs). Only a single thread can run on each core at a time.CPU MT: A fine-grained multithreaded processor that allows instructions from 2
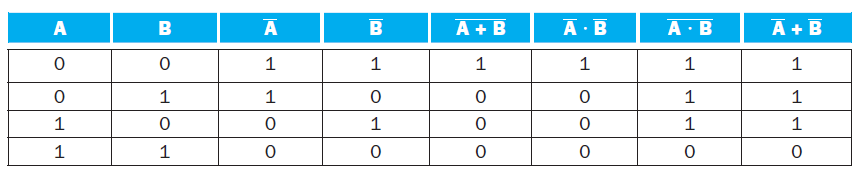
In addition to the basic laws we discussed in this section, there are two important theorems, called DeMorgan€™s theorems:Prove DeMorgan€™s theorems with a truth table of the form A + B = A· B and A · B = A + B A + B A
Implement the four-input odd-parity function with a PLA.
Implement the four functions described in Exercise B.11 using a PLA.Exercise B.11Assume that X consists of 3 bits, x2 x1 x0. Write four logic functions that are true if and only if■ X contains only one 0■ X contains an even number of 0s■ X when interpreted as an unsigned binary number is less
Assume that X consists of 3 bits, x2 x1 x0, and Y consists of 3 bits, y2 y1 y0. Write logic functions that are true if and only if■ X < Y, where X and Y are thought of as unsigned binary numbers■ X < Y, where X and Y are thought of as signed (two’s complement) numbers■ X = YUse a
Implement a switching network that has two data inputs (A and B), two data outputs (C and D), and a control input (S). If S equals 1, the network is in pass-through mode, and C should equal A, and D should equal B. If S equals 0, the network is in crossing mode, and C should equal B, and D should
When a program is adapted to run on multiple processors in a multiprocessor system, the execution time on each processor is comprised of computing time and the overhead time required for locked critical sections and/or to send data from one processor to another.Assume a program requires t = 100 s
Prove that the two equations for E in the example starting on page B-7 are equivalent by using DeMorgan’s theorems and the axioms shown on page B-7.
Construct the truth table for a four-input odd-parity function (see page B-65 for a description of parity).
The Verilog code on page B-53 is for a D flip-flop. Show the Verilog code for a D latch.
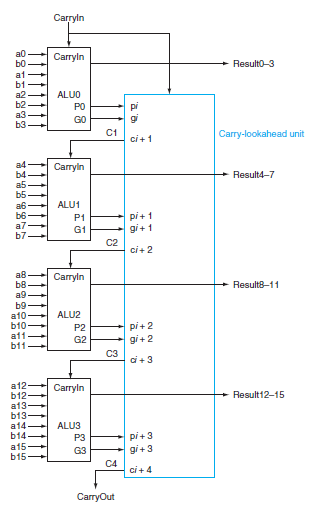
Write the equations for the carry-lookahead logic for a 64-bit adder using the new notation from Exercise B.26 and using 16-bit adders as building blocks. Include a drawing similar to Figure B.6.3 in your solution.Figure B.6.3 Carryln a0 Бо Carryln Resulto-3 at ALUO pi PO GO C1 ci+ 1
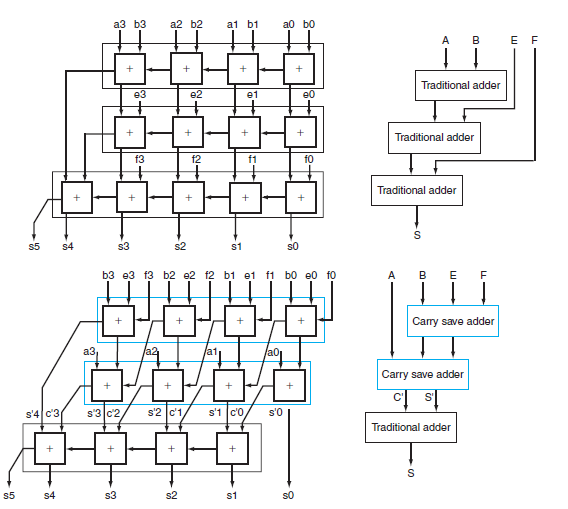
First, show the block organization of the 16-bit carry save adders to add these 16 terms, as shown in Figure B.14.1. Assume that the time delay through each 1-bit adder is 2T. Calculate the time of adding four 4-bit numbers to the organization at the top versus the organization at the bottom
Rewrite the equations on page B-44 for a carry-lookahead logic for a 16-bit adder using a new notation. First, use the names for the CarryIn signals of the individual bits of the adder. That is, use c4, c8, c12, … instead of C1, C2, C3, …. In addition, let Pi,j; mean a propagate signal for bits
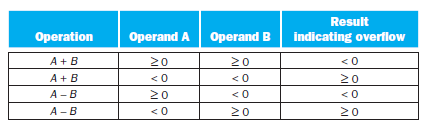
A simple check for overfl ow during addition is to see if the CarryIn to the most significant bit is not the same as the CarryOut of the most significant bit. Prove that this check is the same as inFigure 3.2. Result Result Operand A Operand B indicating overflow Operation A + B A+ B
The ALU supported set on less than (slt) using just the sign bit of the adder. Let’s try a set on less than operation using the values -7ten and 6ten.To make it simpler to follow the example, let’s limit the binary representations to 4 bits: 1001two and 0110two.1001two – 0110two = 1001two +
Repeat Exercise B.22, but for an unsigned divider rather than a multiplier.Data from in Repeat Exercise B.22Section 3.3 presents basic operation and possible implementations of multipliers. A basic unit of such implementations is a shift - and-add unit. Show a Verilog implementation for this unit.
Section 3.3 presents basic operation and possible implementations of multipliers. A basic unit of such implementations is a shift - and-add unit. Show a Verilog implementation for this unit. Show how can you use this unit to build a 32-bit multiplier.
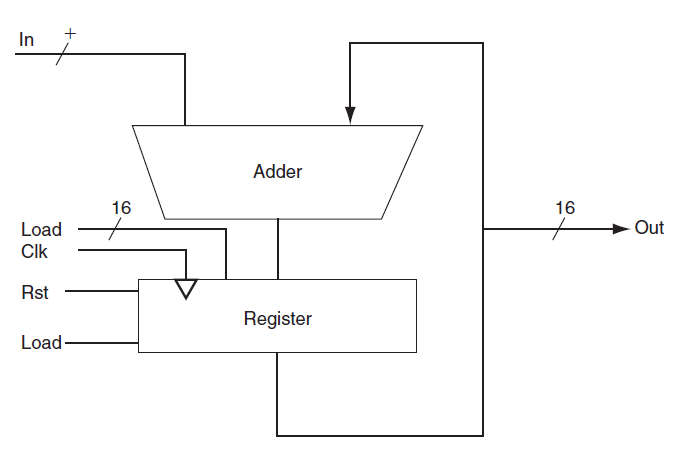
Given the following logic diagram for an accumulator, write down the Verilog module implementation of it. Assume a positive edgetriggered register and asynchronous Rst. In Adder 16 16 Out Load Clk Rst Register Load
Write down a Verilog module implementation of a 2-to-4 decoder (and/or encoder).
What is the function implemented by the following Verilog modules: module FUNC1 (10, I1, S, out); input I0, I1; input S; output out; out = S? Il: I0; endmodule module FUNC2 (out,ctl, clk,reset); output [7:0] out; input ctl, clk, reset; reg [7:0] out; always @(posedge clk) if (reset) begin out
Derive the product-of-sums representation for E shown on page B-11 starting with the sum-of-products representation. You will need to use DeMorgan’s theorems.
Assume that X consists of 3 bits, x2 x1 x0. Write four logic functions that are true if and only if■ X contains only one 0■ X contains an even number of 0s■ X when interpreted as an unsigned binary number is less than 4■X when interpreted as a signed (two’s complement) number is negative.
Implement the four-input odd-parity function with AND and OR gates using bubbled inputs and outputs.
Assume a quad-core computer system can process database queries at a steady state rate of requests per second. Also assume that each transaction takes, on average, a fixed amount of time to process. The following table shows pairs of transaction latency and processing rate.Average Transaction
In future systems, we expect to see heterogeneous computing platforms constructed out of heterogeneous CPUs. We have begun to see some appear in the embedded processing market in systems that contain both floating point DSPs and a microcontroller CPUs in a multichip module package. Assume that you
When performing computations on sparse matrices, latency in the memory hierarchy becomes much more of a factor. Sparse matrices lack the spatial locality in the data stream typically found in matrix operations. As a result, new matrix representations have been proposed.One the earliest sparse
Benchmarking is field of study that involves identifying representative workloads to run on specific computing platforms in order to be able to objectively compare performance of one system to another. In this exercise we will compare two classes of benchmarks: the Whetstone CPU benchmark and the
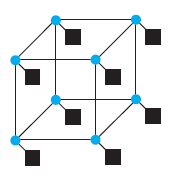
Refer to Figure 6.14b, which shows an n-cube interconnect topology of order 3 that interconnects 8 nodes. One attractive feature of an n-cube interconnection network topology is its ability to sustain broken links and still provide connectivity.1. Develop an equation that computes how
We would like to execute the loop below as efficiently as possible. We have two different machines, a MIMD machine and a SIMD machine.for (i=0; i < 2000; i++)for (j=0; j<3000; j++)X_array[i][j] = Y_array[j][i] + 200;1. For a 4 CPU MIMD machine, show the sequence of MIPS instructions that
The dining philosopher’s problem is a classic problem of synchronization and concurrency. The general problem is stated as philosophers sitting at a round table doing one of two things: eating or thinking. When they are eating, they are not thinking, and when they are thinking, they are not
Consider the following portions of two different programs running at the same time on four processors in a symmetric multicore processor (SMP). Assume that before this code is run, both x and y are 0.Core 1: x = 2;Core 2: y = 2;Core 3: w = x + y + 1;Core 4: z = x + y;1. What are
Matrix multiplication plays an important role in a number of applications. Two matrices can only be multiplied if the number of columns of the first matrix is equal to the number of rows in the second.Let’s assume we have an m × n matrix A and we want to multiply it
Consider the following recursive mergesort algorithm (another classic divide and conquer algorithm). Mergesort was first described by John Von Neumann in 1945. The basic idea is to divide an unsorted list x of m elements into two sublists of about half the size of the original
Consider the following piece of C code:for (j=2;j<1000;j++)D[j] = D[jˆ’1]+D[jˆ’2];Th e MIPS code corresponding to the above fragment is:Instructions have the following associated latencies (in cycles):1. How many cycles does it take for all instructions in a single iteration
Many computer applications involve searching through a set of data and sorting the data. A number of efficient searching and sorting algorithms have been devised in order to reduce the runtime of these tedious tasks. In this problem we will consider how best to parallelize these tasks.1. Consider
You are trying to bake 3 blueberry pound cakes. Cake ingredients are as follows:1 cup butter, softened1 cup sugar4 large eggs1 teaspoon vanilla extract1/2 teaspoon salt1/4 teaspoon nutmeg1 1/2 cups flour1 cup blueberriesThe recipe for a single cake is as follows:Step 1: Preheat oven to 325°F
First, write down a list of your daily activities that you typically do on a weekday. For instance, you might get out of bed, take a shower, get dressed, eat breakfast, dry your hair, brush your teeth. Make sure to break down your list so you have a minimum of 10 activities.1. Now consider which of
In this exercise we show the definition of a web server log and examine code optimizations to improve log processing speed. Th e data structure for the log is defined as follows:
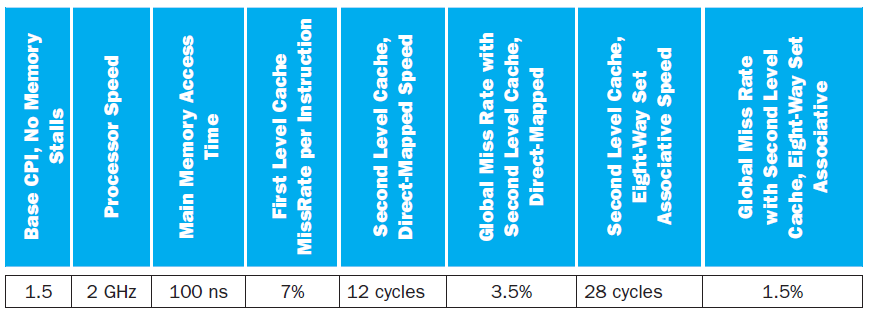
Chip multiprocessors (CMPs) have multiple cores and their caches on a single chip. CMP on-chip L2 cache design has interesting trade-off s. Th e following table shows the miss rates and hit latencies for two benchmarks with private vs. shared L2 cache designs. Assume L1 cache misses once every 32
Cache coherence concerns the views of multiple processors on a given cache block. The following data shows two processors and their read/write operations on two different words of a cache block X (initially X[0] = X[1] = 0). Assume the size of integers is 32 bits.P1 P2X[0] ++; X[1] = 3; X[0] = 5;
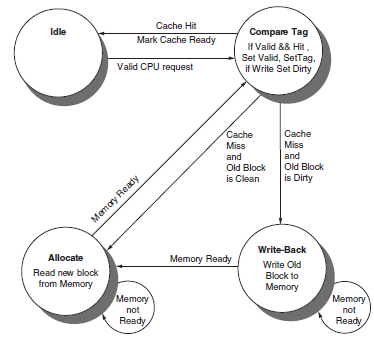
In this exercise, we will explore the control unit for a cache controller for a processor with a write buffer. Use the finite state machine found in Figure 5.40 as a starting point for designing your own finite state machines. Assume that the cache controller is for the simple direct-mapped cache
One of the biggest impediments to widespread use of virtual machines is the performance overhead incurred by running a virtual machine. Listed below are various performance parameters and application behavior.1. Calculate the CPI for the system listed above assuming that there are no accesses to
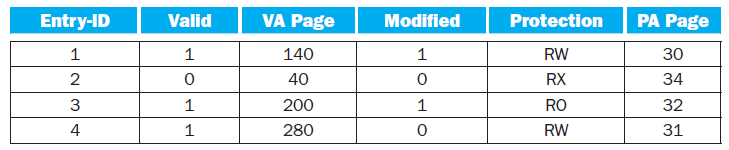
To support multiple virtual machines, two levels of memory virtualization are needed. Each virtual machine still controls the mapping of virtual address (VA) to physical address (PA), while the hypervisor maps the physical address (PA) of each virtual machine to the actual machine address (MA). To
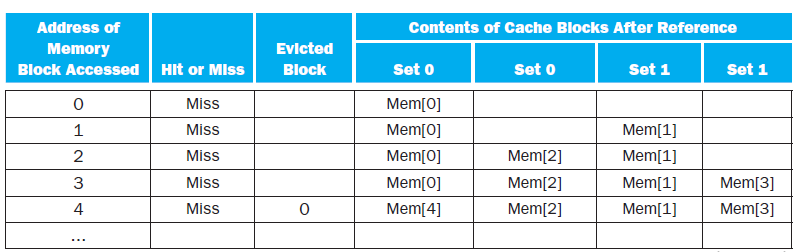
In this exercise, we will examine how replacement policies impact miss rate. Assume a 2-way set associative cache with 4 blocks. To solve the problems in this exercise, you may find it helpful to draw a table like the one below, as demonstrated for the address sequence €œ0, 1, 2, 3,
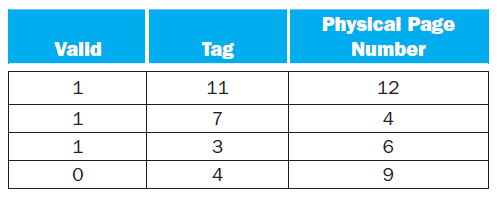
In this exercise, we will examine space/time optimizations for page tables. The following list provides parameters of a virtual memory system.1. For a single-level page table, how many page table entries (PTEs) are needed? How much physical memory is needed for storing the page table?2. Using a
As described in Section 5.7, virtual memory uses a page table to track the mapping of virtual addresses to physical addresses. This exercise shows how this table must be updated as addresses are accessed. The following data constitutes a stream of virtual addresses as seen on a system. Assume 4 KiB
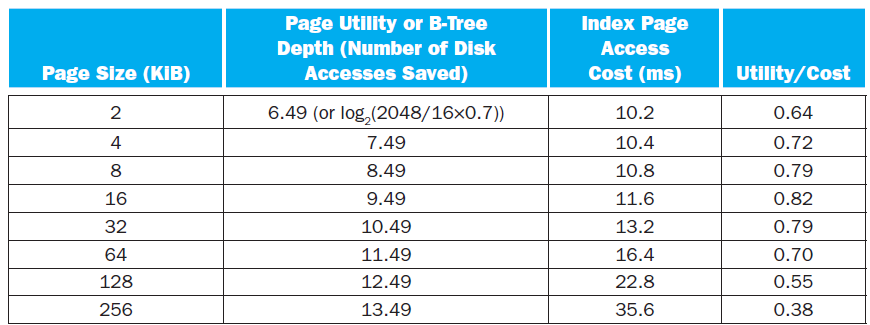
For a high-performance system such as a B-tree index for a database, the page size is determined mainly by the data size and disk performance. Assume that on average a B-tree index page is 70% full with fix-sized entries. The utility of a page is its B-tree depth, calculated as log2(entries). Th e
Th is Exercise examines the single error correcting, double error detecting (SEC/DED) Hamming code.1. What is the minimum number of parity bits required to protect a 128-bit word using the SEC/DED code?2. Section 5.5 states that modern server memory modules (DIMMs) employ SEC/DED ECC to protect
Mean Time Between Failures (MTBF), Mean Time To Replacement (MTTR), and Mean Time To Failure (MTTF) are useful metrics for evaluating the reliability and availability of a storage resource. Explore these concepts by answering the questions about devices with the following metrics.MTTF
This exercise examines the impact of different cache designs, specifically comparing associative caches to the direct-mapped caches from Section 5.4. For these exercises, refer to the address stream shown in Exercise 5.2.1. Using the sequence of references from Exercise 5.2, show the final cache
In this exercise, we will look at the different ways capacity affects overall performance. In general, cache access time is proportional to capacity. Assume that main memory accesses take 70 ns and that memory accesses are 36% of all instructions.The following table shows data for L1 caches
Based on your answers to 3.35 and 3.36, does (3.41796875 10-3 × 6.34765625 × 10-3) × 1.05625 × 102 = 3.41796875 × 10-3 × (6.34765625 × 10-3 × 1.05625 × 102)?
If the bit pattern 0×0C000000 is placed into the Instruction Register, what MIPS instruction will be executed?
What decimal number does the bit pattern 0×0C000000 represent if it is a two’s complement integer? An unsigned integer?
Media applications that play audio or video files are part of a class of workloads called €œstreaming€ workloads; i.e., they bring in large amounts of data but do not reuse much of it. Consider a video streaming workload that accesses a 512 KiB working set sequentially with the
Recall that we have two write policies and write allocation policies, and their combinations can be implemented either in L1 or L2 cache. Assume the following choices for L1 and L2 caches: L1
For a direct-mapped cache design with a 32-bit address, the following bits of the address are used to access the cache.1. What is the cache block size (in words)?2. How many entries does the cache have?3. What is the ratio between total bits required for such a cache implementation over the data
Caches are important to providing a high-performance memory hierarchy to processors. Below is a list of 32-bit memory address references, given as word addresses.3, 180, 43, 2, 191, 88, 190, 14, 181, 44, 186, 2531. For each of these references, identify the binary address, the tag, and the index
In this exercise we look at memory locality properties of matrix computation.The following code is written in C, where elements within the same row are stored contiguously. Assume each word is a 32-bit integer.for (I=0; I<8; I++)for (J=0; J<8000; J++)A[I][J]=B[I][0]+A[J][I];1. How many 32-bit
This exercise explores energy efficiency and its relationship with performance. Problems in this exercise assume the following energy consumption for activity in Instruction memory, Registers, and Data memory. You can assume that the other components of the datapath spend a negligible amount of
In this exercise we compare the performance of 1-issue and 2-issue processors, taking into account program transformations that can be made to optimize for 2-issue execution. Problems in this exercise refer to the following loop(written in C):for(i=0;i!=j;i+=2)b[i]=a[i]€“a[i+1];When
This exercise explores how exception handling affects pipeline design. The first three problems in this exercise refer to the following two instructions:Instruction 1...................Instruction 2BNE R1, R2, ...............Label LW R1, 0(R1)1. Which exceptions can each of these instructions
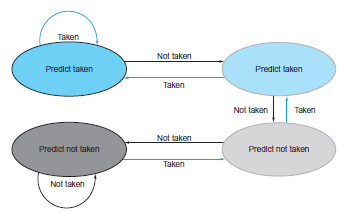
This exercise examines the accuracy of various branch predictors for the following repeating pattern (e.g., in a loop) of branch outcomes: T, NT, T, T, NT1. What is the accuracy of always-taken and always-not taken predictors for this sequence of branch outcomes?2. What is the accuracy of the
The importance of having a good branch predictor depends on how oft en conditional branches are executed. Together with branch predictor accuracy, this will determine how much time is spent stalling due to mispredicted branches. In this exercise, assume that the breakdown of dynamic instructions
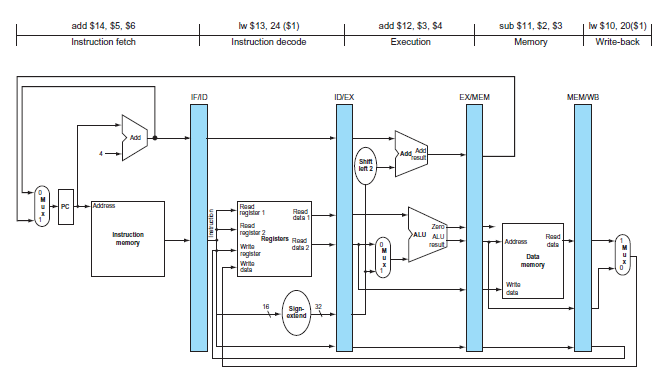
This exercise is intended to help you understand the relationship between delay slots, control hazards, and branch execution in a pipelined processor. In this exercise, we assume that the following MIPS code is executed on a pipelined processor with a 5-stage pipeline, full forwarding, and a
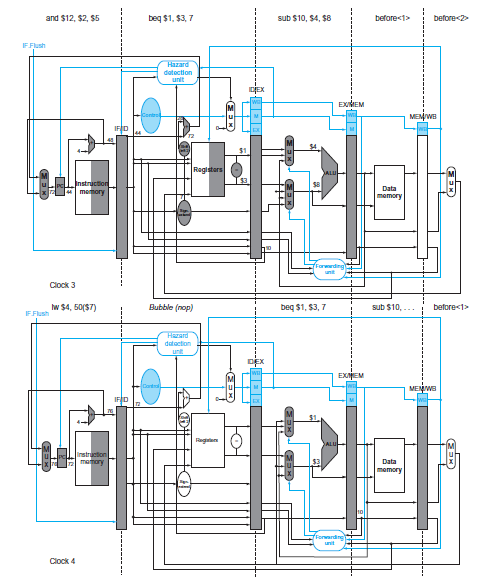
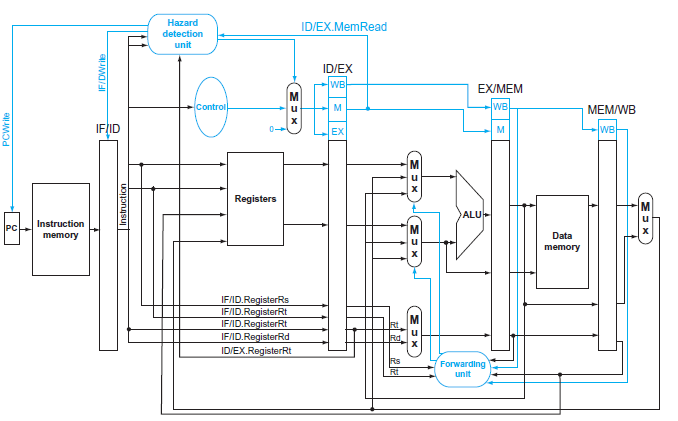
This exercise is intended to help you understand the relationship between forwarding, hazard detection, and ISA design. Problems in this exercise refer to the following sequence of instructions, and assume that it is executed on a 5-stage pipelined datapath:1. If there is no forwarding or hazard
This exercise is intended to help you understand the cost/complexity/ performance trade-off s of forwarding in a pipelined processor. Problems in this exercise refer to pipelined datapaths from Figure 4.45. These problems assume that, of all the instructions executed in a processor, the following
Consider the following loop.Assume that perfect branch prediction is used (no stalls due to control hazards), that there are no delay slots, and that the pipeline has full forwarding support. Also assume that many iterations of this loop are executed before the loop exits.1. Show a pipeline
In this exercise, we examine how resource hazards, control hazards, and Instruction Set Architecture (ISA) design can affect pipelined execution. Problems in this exercise refer to the following fragment of MIPS code:Assume that individual pipeline stages have the following latencies: IF ID1. For
In this exercise, we examine how data dependences affect execution in the basic 5-stage pipeline described in Section 4.5. Problems in this exercise refer to the following sequence of instructions:Also, assume the following cycle times for each of the options related to forwarding:1. Indicate
In this exercise, we examine how pipelining affects the clock cycle time of the processor. Problems in this exercise assume that individual stages of the datapath have the following latencies:Also, assume that instructions executed by the processor are broken down as follows:1. What is the clock
When silicon chips are fabricated, defects in materials (e.g., silicon) and manufacturing errors can result in defective circuits. A very common defect is for one wire to affect the signal in another. This is called a cross-talk fault. A special class of cross-talk faults is when a signal is
For the problems in this exercise, assume that there are no pipeline stalls and that the breakdown of executed instructions is as follows:1. In what fraction of all cycles is the data memory used?2. In what fraction of all cycles is the input of the sign extend circuit needed? What is this circuit
Problems in this exercise assume that logic blocks needed to implement a processor€™s datapath have the following latencies:1. If the only thing we need to do in a processor is fetch consecutive instructions (Figure 4.6), what would the cycle time be?Figure 4.62. Consider a datapath
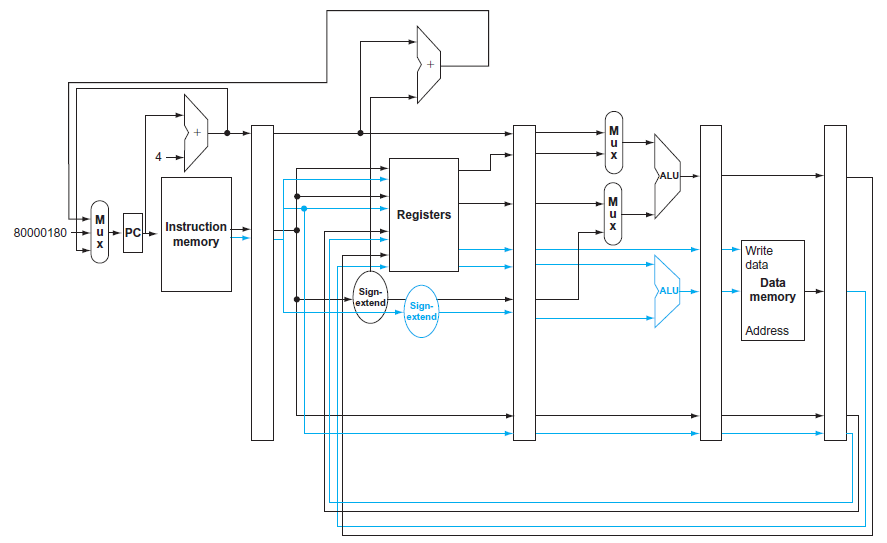
When processor designers consider a possible improvement to the processor datapath, the decision usually depends on the cost/performance trade-off . In the following three problems, assume that we are starting with a datapath from Figure 4.2, where I-Mem, Add, Mux, ALU, Regs, D-Mem, and Control
The basic single-cycle MIPS implementation in Figure 4.2 can only implement some instructions. New instructions can be added to an existing Instruction Set Architecture (ISA), but the decision whether or not to do that depends, among other things, on the cost and complexity the proposed addition
Consider the following instruction:Instruction: AND Rd,Rs,RtInterpretation: Reg[Rd] = Reg[Rs] AND Reg[Rt]1. What are the values of control signals generated by the control in Figure 4.2 for the above instruction?Figure 4.22. Which resources (blocks) perform a useful function for this
Th e following C code implements a four-tap FIR filter on input array sig_in. Assume that all arrays are 16-bit fixed point values.Assume you are to write an optimized implementation this code in assembly language on a processor that has SIMD instructions and 128-bit registers. Without knowing the
Write down the bit pattern assuming that we are using base 30 numbers in the fraction instead of base 2. (Base 16 numbers use the symbols 0–9 and A–F. Base 30 numbers would use 0–9 and A–T.) Assume there are 20 bits, and you do not need to normalize. Is this representation exact?
Write down the bit pattern assuming that we are using base 15 numbers in the fraction instead of base 2. (Base 16 numbers use the symbols 0–9 and A–F. Base 15 numbers would use 0–9 and A–E.) Assume there are 24 bits, and you do not need to normalize. Is this representation exact?
Write down the bit pattern in the fraction assuming a floating point format that uses Binary Coded Decimal (base 10) numbers in the fraction instead of base 2. Assume there are 24 bits, and you do not need to normalize. Is this representation exact?
Write down the bit pattern in the fraction of value 1/3 assuming a floating point format that uses binary numbers in the fraction. Assume there are 24 bits, and you do not need to normalize. Is this representation exact?
What do you get if you add -1/4 to itself 4 times? What is -1/4 × 4? Are they the same? What should they be?
Using the IEEE 754 floating point format, write down the bit pattern that would represent -1/4. Can you represent -1/4 exactly?
Based on your answers to 3.38 and 3.39, does (1.666015625 × 100 × 1.9760 × 104) + (1.666015625 × 100 × -1.9744 × 104) = 1.666015625 × 100 × (1.9760 × 104 + -1.9744 × 104)?
Calculate (1.666015625 × 100 × 1.9760 × 104) + (1.666015625 × 100 × -1.9744 × 104) by hand, assuming each of the values are stored in the 16-bit half precision format described in Exercise 3.27 (and also described in the text). Assume 1 guard, 1 round bit, and 1 sticky bit, and round to the
Calculate 1.666015625 × 100 × (1.9760 × 104 + -1.9744 × 104) by hand, assuming each of the values are stored in the 16-bit half precision format described in Exercise 3.27 (and also described in the text). Assume 1 guard, 1 round bit, and 1 sticky bit, and round to the nearest even. Show all
Calculate 3.41796875 10-3 × (6.34765625 × 10-3 × 1.05625 × 102) by hand, assuming each of the values are stored in the 16-bit half precision format described in Exercise 3.27 (and also described in the text). Assume 1 guard, 1 round bit, and 1 sticky bit, and round to the nearest even. Show all
Calculate (3.41796875 10-3 × 6.34765625 × 10-3) × 1.05625 × 102 by hand, assuming each of the values are stored in the 16-bit half precision format described in Exercise 3.27 (and also described in the text). Assume 1 guard, 1 round bit, and 1 sticky bit, and round to the nearest even. Show all
Based on your answers to 3.32 and 3.33, does (3.984375 × 10-1 + 3.4375 × 10-1) + 1.771 × 103 = 3.984375 × 10-1 + (3.4375 × 10-1 + 1.771 × 103)?
Calculate 3.984375 × 10-1 + (3.4375 × 10-1 + 1.771 × 103) by hand, assuming each of the values are stored in the 16-bit half precision format described in Exercise 3.27 (and also described in the text). Assume 1 guard, 1 round bit, and 1 sticky bit, and round to the nearest even. Show all the
Calculate (3.984375 × 10-1 + 3.4375 × 10-1) + 1.771 × 103 by hand, assuming each of the values are stored in the 16-bit half precision format described in Exercise 3.27 (and also described in the text). Assume 1 guard, 1 round bit, and 1 sticky bit, and round to the nearest even. Show all the
Showing 900 - 1000
of 1073
1
2
3
4
5
6
7
8
9
10
11
Step by Step Answers

![Instruction [25-0] Jump address [31-0] Shift left 2 26 28 0. PC + 4 [31-281 Add Add ALU result Shift left 2 RegDst Jump](https://dsd5zvtm8ll6.cloudfront.net/si.question.images/images/question_images/1544/5/3/2/4615c0fb1ed1969c1544515022341.jpg)
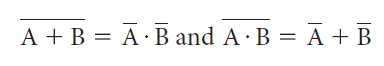


![Row 1 [1, 2, 0, 0, 0, 0] Row 2 [0, 0, 1, 1, 0, 0] Row 3 [0, 0, 0, 0, 9, 0] Row 4 [2, 0, 0, 0, 0, 2] Row 5 [0, 0, 3, 3, 0](https://dsd5zvtm8ll6.cloudfront.net/si.question.images/images/question_images/1544/6/0/7/0655c10d559e38871544534990373.jpg)




![BinarySearch(A[0..N-1], X) { low = 0 high = N -1 while (low <= high) { mid = (1ow + high) / 2 if (A[mid] style=](https://dsd5zvtm8ll6.cloudfront.net/si.question.images/images/question_images/1544/6/0/6/8865c10d4a6538ac1544534810652.jpg)
![struct entry { int srcIP; char URL[128]; // request URL (e.g. , “GET index.html](https://dsd5zvtm8ll6.cloudfront.net/si.question.images/images/question_images/1544/5/3/9/9465c0fcf2a9d50f1544522507321.jpg)




















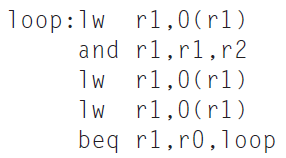


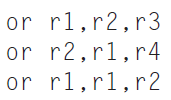



![Jump address [31-0] Instruction [25-0] Shift left 2 26 28 0. PC + 4 [31-281 Add ALU result Add Shift left 2 RegDst Jump](https://dsd5zvtm8ll6.cloudfront.net/si.question.images/images/question_images/1544/5/3/2/2375c0fb10d8a54d1544514798788.jpg)


![for (i= 3;i<128;i++) sig_out[i]=sig_in[i-3] +sig_in[i-1] * f[2]+sig_in[i] * f[3]; * f [0]+sig_in[i- 2] * f[1]](https://dsd5zvtm8ll6.cloudfront.net/si.question.images/images/question_images/1544/5/2/3/3345c0f8e4651f901544505895410.jpg)

