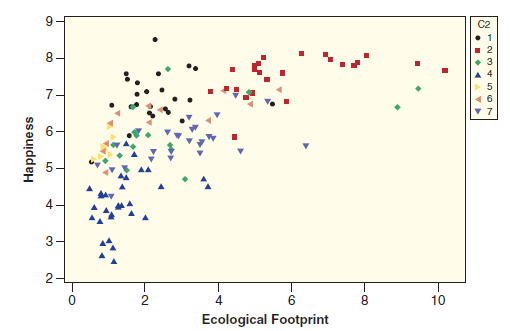
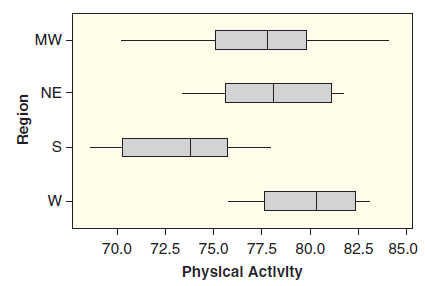
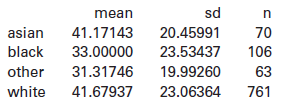
Statistics Unlocking The Power Of Data 1st Edition Robin H. Lock, Patti Frazer Lock, Kari Lock Morgan, Eric F. Lock, Dennis F. Lock - Solutions
Discover comprehensive resources for "Statistics: Unlocking The Power Of Data 1st Edition" by Robin H. Lock and others, featuring a rich collection of questions and answers. Our online platform offers an extensive answers key and solutions manual, providing step-by-step answers to enhance your understanding. Access the solutions PDF to explore solved problems and chapter solutions, perfect for mastering the textbook material. Ideal for students seeking a test bank, instructor manual, or those preparing for exams, our content is available for free download. Empower your learning with structured, accessible solutions today.